 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtkarsh Mall
Evolving Interpretable Visual Classifiers with Large Language Models
Apr 15, 2024
Multimodal pre-trained models, such as CLIP, are popular for zero-shot classification due to their open-vocabulary flexibility and high performance. However, vision-language models, which compute similarity scores between images and class labels, are largely black-box, with limited interpretability, risk for bias, and inability to discover new visual concepts not written down. Moreover, in practical settings, the vocabulary for class names and attributes of specialized concepts will not be known, preventing these methods from performing well on images uncommon in large-scale vision-language datasets. To address these limitations, we present a novel method that discovers interpretable yet discriminative sets of attributes for visual recognition. We introduce an evolutionary search algorithm that uses a large language model and its in-context learning abilities to iteratively mutate a concept bottleneck of attributes for classification. Our method produces state-of-the-art, interpretable fine-grained classifiers. We outperform the latest baselines by 18.4% on five fine-grained iNaturalist datasets and by 22.2% on two KikiBouba datasets, despite the baselines having access to privileged information about class names.
Remote Sensing Vision-Language Foundation Models without Annotations via Ground Remote Alignment
Dec 12, 2023We introduce a method to train vision-language models for remote-sensing images without using any textual annotations. Our key insight is to use co-located internet imagery taken on the ground as an intermediary for connecting remote-sensing images and language. Specifically, we train an image encoder for remote sensing images to align with the image encoder of CLIP using a large amount of paired internet and satellite images. Our unsupervised approach enables the training of a first-of-its-kind large-scale vision language model (VLM) for remote sensing images at two different resolutions. We show that these VLMs enable zero-shot, open-vocabulary image classification, retrieval, segmentation and visual question answering for satellite images. On each of these tasks, our VLM trained without textual annotations outperforms existing VLMs trained with supervision, with gains of up to 20% for classification and 80% for segmentation.
Field-Guide-Inspired Zero-Shot Learning
Aug 24, 2021
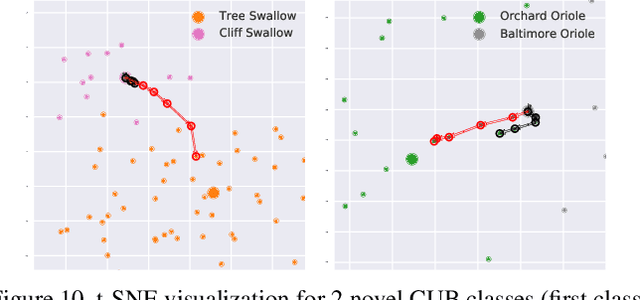
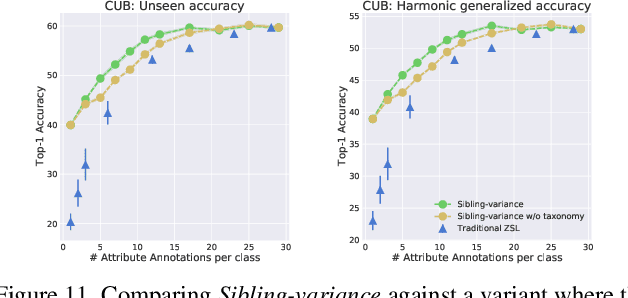
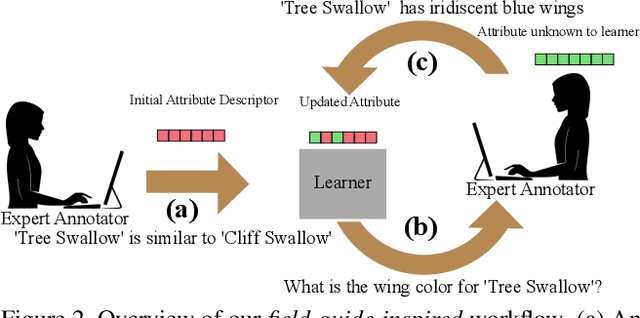
Modern recognition systems require large amounts of supervision to achieve accuracy. Adapting to new domains requires significant data from experts, which is onerous and can become too expensive. Zero-shot learning requires an annotated set of attributes for a novel category. Annotating the full set of attributes for a novel category proves to be a tedious and expensive task in deployment. This is especially the case when the recognition domain is an expert domain. We introduce a new field-guide-inspired approach to zero-shot annotation where the learner model interactively asks for the most useful attributes that define a class. We evaluate our method on classification benchmarks with attribute annotations like CUB, SUN, and AWA2 and show that our model achieves the performance of a model with full annotations at the cost of a significantly fewer number of annotations. Since the time of experts is precious, decreasing annotation cost can be very valuable for real-world deployment.
PiCIE: Unsupervised Semantic Segmentation using Invariance and Equivariance in Clustering
Mar 30, 2021
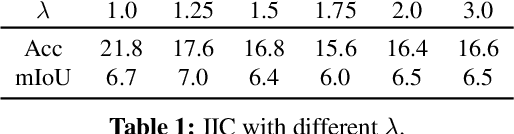
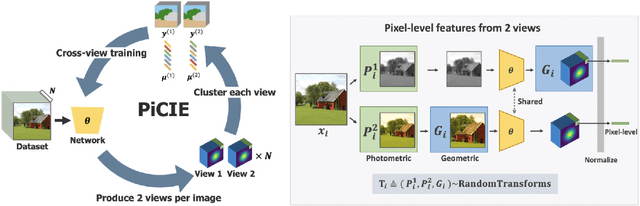
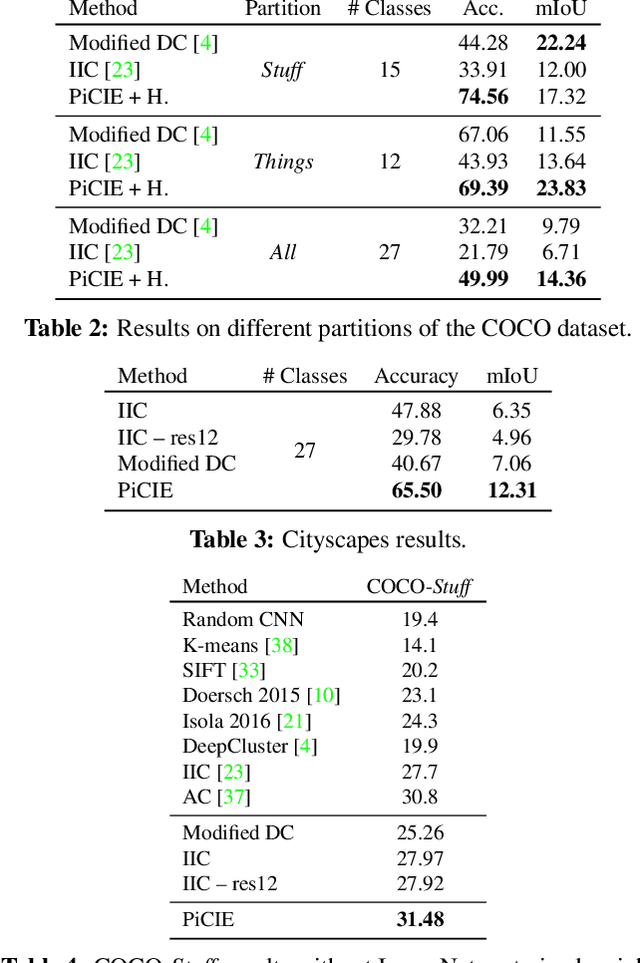
We present a new framework for semantic segmentation without annotations via clustering. Off-the-shelf clustering methods are limited to curated, single-label, and object-centric images yet real-world data are dominantly uncurated, multi-label, and scene-centric. We extend clustering from images to pixels and assign separate cluster membership to different instances within each image. However, solely relying on pixel-wise feature similarity fails to learn high-level semantic concepts and overfits to low-level visual cues. We propose a method to incorporate geometric consistency as an inductive bias to learn invariance and equivariance for photometric and geometric variations. With our novel learning objective, our framework can learn high-level semantic concepts. Our method, PiCIE (Pixel-level feature Clustering using Invariance and Equivariance), is the first method capable of segmenting both things and stuff categories without any hyperparameter tuning or task-specific pre-processing. Our method largely outperforms existing baselines on COCO and Cityscapes with +17.5 Acc. and +4.5 mIoU. We show that PiCIE gives a better initialization for standard supervised training. The code is available at https://github.com/janghyuncho/PiCIE.
Discovering Underground Maps from Fashion
Dec 04, 2020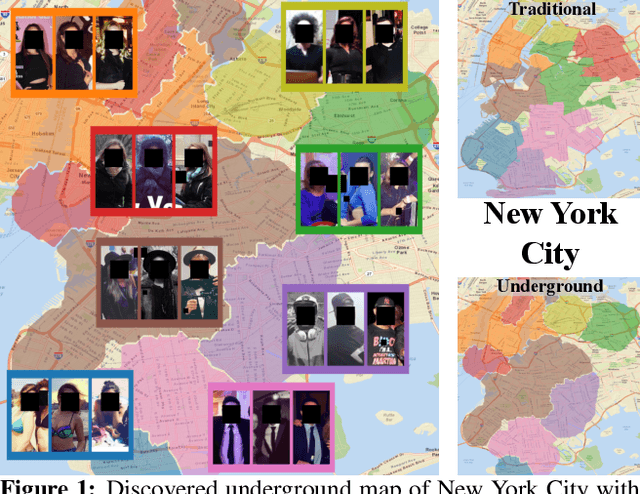
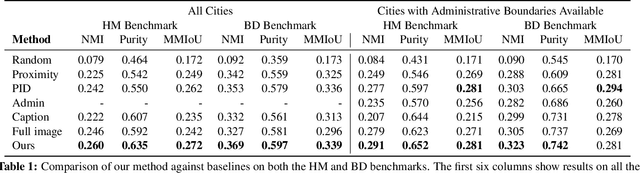
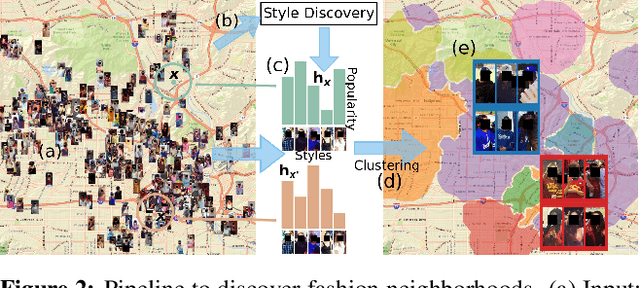
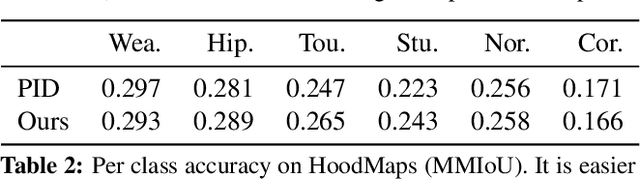
The fashion sense -- meaning the clothing styles people wear -- in a geographical region can reveal information about that region. For example, it can reflect the kind of activities people do there, or the type of crowds that frequently visit the region (e.g., tourist hot spot, student neighborhood, business center). We propose a method to automatically create underground neighborhood maps of cities by analyzing how people dress. Using publicly available images from across a city, our method finds neighborhoods with a similar fashion sense and segments the map without supervision. For 37 cities worldwide, we show promising results in creating good underground maps, as evaluated using experiments with human judges and underground map benchmarks derived from non-image data. Our approach further allows detecting distinct neighborhoods (what is the most unique region of LA?) and answering analogy questions between cities (what is the "Downtown LA" of Bogota?).
GeoStyle: Discovering Fashion Trends and Events
Aug 29, 2019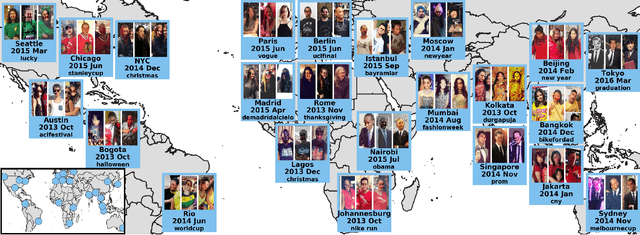

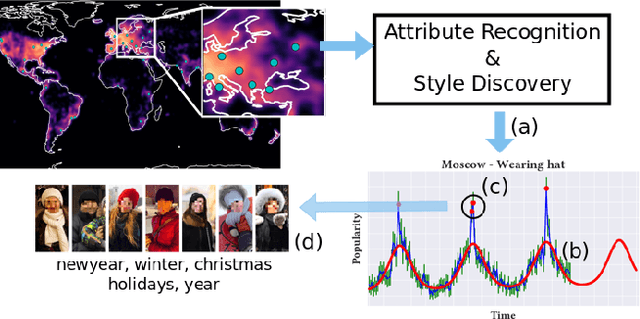
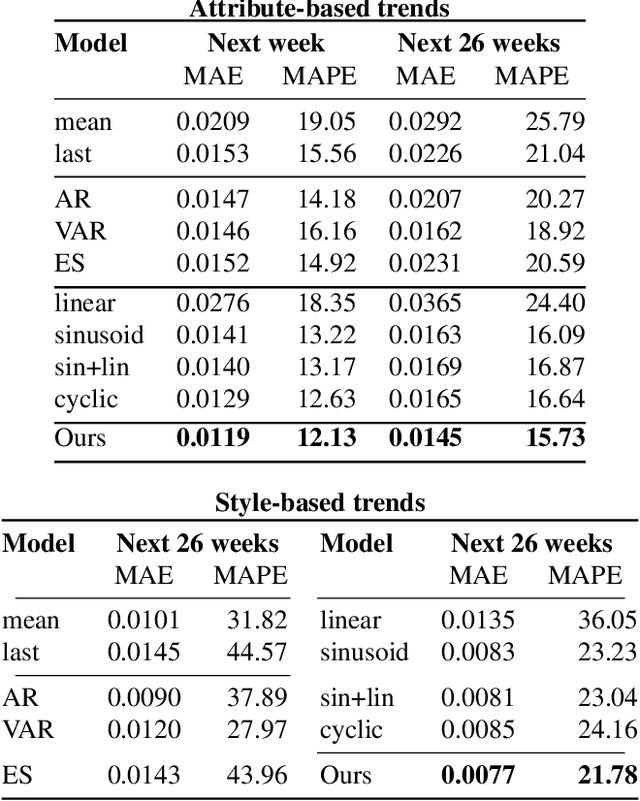
Understanding fashion styles and trends is of great potential interest to retailers and consumers alike. The photos people upload to social media are a historical and public data source of how people dress across the world and at different times. While we now have tools to automatically recognize the clothing and style attributes of what people are wearing in these photographs, we lack the ability to analyze spatial and temporal trends in these attributes or make predictions about the future. In this paper, we address this need by providing an automatic framework that analyzes large corpora of street imagery to (a) discover and forecast long-term trends of various fashion attributes as well as automatically discovered styles, and (b) identify spatio-temporally localized events that affect what people wear. We show that our framework makes long term trend forecasts that are >20% more accurate than the prior art, and identifies hundreds of socially meaningful events that impact fashion across the globe.
A Deep Recurrent Framework for Cleaning Motion Capture Data
Dec 09, 2017
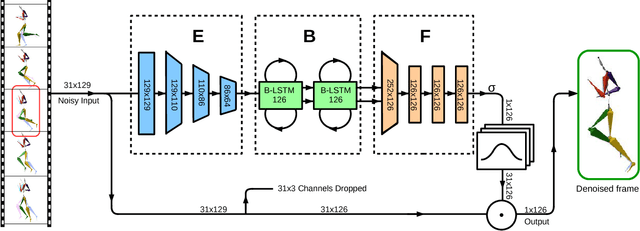
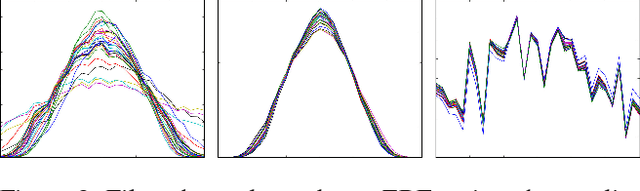
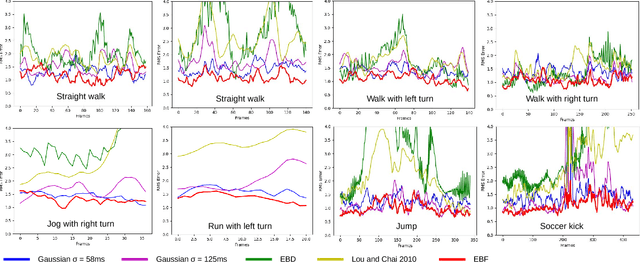
We present a deep, bidirectional, recurrent framework for cleaning noisy and incomplete motion capture data. It exploits temporal coherence and joint correlations to infer adaptive filters for each joint in each frame. A single model can be trained to denoise a heterogeneous mix of action types, under substantial amounts of noise. A signal that has both noise and gaps is preprocessed with a second bidirectional network that synthesizes missing frames from surrounding context. The approach handles a wide variety of noise types and long gaps, does not rely on knowledge of the noise distribution, and operates in a streaming setting. We validate our approach through extensive evaluations on noise both in joint angles and in joint positions, and show that it improves upon various alternatives.