 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVahid Tarokh
Neural McKean-Vlasov Processes: Distributional Dependence in Diffusion Processes
Apr 15, 2024
McKean-Vlasov stochastic differential equations (MV-SDEs) provide a mathematical description of the behavior of an infinite number of interacting particles by imposing a dependence on the particle density. As such, we study the influence of explicitly including distributional information in the parameterization of the SDE. We propose a series of semi-parametric methods for representing MV-SDEs, and corresponding estimators for inferring parameters from data based on the properties of the MV-SDE. We analyze the characteristics of the different architectures and estimators, and consider their applicability in relevant machine learning problems. We empirically compare the performance of the different architectures and estimators on real and synthetic datasets for time series and probabilistic modeling. The results suggest that explicitly including distributional dependence in the parameterization of the SDE is effective in modeling temporal data with interaction under an exchangeability assumption while maintaining strong performance for standard It\^o-SDEs due to the richer class of probability flows associated with MV-SDEs.
Large Deviation Analysis of Score-based Hypothesis Testing
Feb 03, 2024Score-based statistical models play an important role in modern machine learning, statistics, and signal processing. For hypothesis testing, a score-based hypothesis test is proposed in \cite{wu2022score}. We analyze the performance of this score-based hypothesis testing procedure and derive upper bounds on the probabilities of its Type I and II errors. We prove that the exponents of our error bounds are asymptotically (in the number of samples) tight for the case of simple null and alternative hypotheses. We calculate these error exponents explicitly in specific cases and provide numerical studies for various other scenarios of interest.
Data-Driven Target Localization: Benchmarking Gradient Descent Using the Cramér-Rao Bound
Jan 20, 2024In modern radar systems, precise target localization using azimuth and velocity estimation is paramount. Traditional unbiased estimation methods have leveraged gradient descent algorithms to reach the theoretical limits of the Cram\'er Rao Bound (CRB) for the error of the parameter estimates. In this study, we present a data-driven neural network approach that outperforms these traditional techniques, demonstrating improved accuracies in target azimuth and velocity estimation. Using a representative simulated scenario, we show that our proposed neural network model consistently achieves improved parameter estimates due to its inherently biased nature, yielding a diminished mean squared error (MSE). Our findings underscore the potential of employing deep learning methods in radar systems, paving the way for more accurate localization in cluttered and dynamic environments.
Random Linear Projections Loss for Hyperplane-Based Optimization in Regression Neural Networks
Nov 21, 2023Despite their popularity across a wide range of domains, regression neural networks are prone to overfitting complex datasets. In this work, we propose a loss function termed Random Linear Projections (RLP) loss, which is empirically shown to mitigate overfitting. With RLP loss, the distance between sets of hyperplanes connecting fixed-size subsets of the neural network's feature-prediction pairs and feature-label pairs is minimized. The intuition behind this loss derives from the notion that if two functions share the same hyperplanes connecting all subsets of feature-label pairs, then these functions must necessarily be equivalent. Our empirical studies, conducted across benchmark datasets and representative synthetic examples, demonstrate the improvements of the proposed RLP loss over mean squared error (MSE). Specifically, neural networks trained with the RLP loss achieve better performance while requiring fewer data samples and are more robust to additive noise. We provide theoretical analysis supporting our empirical findings.
Counterfactual Data Augmentation with Contrastive Learning
Nov 07, 2023Statistical disparity between distinct treatment groups is one of the most significant challenges for estimating Conditional Average Treatment Effects (CATE). To address this, we introduce a model-agnostic data augmentation method that imputes the counterfactual outcomes for a selected subset of individuals. Specifically, we utilize contrastive learning to learn a representation space and a similarity measure such that in the learned representation space close individuals identified by the learned similarity measure have similar potential outcomes. This property ensures reliable imputation of counterfactual outcomes for the individuals with close neighbors from the alternative treatment group. By augmenting the original dataset with these reliable imputations, we can effectively reduce the discrepancy between different treatment groups, while inducing minimal imputation error. The augmented dataset is subsequently employed to train CATE estimation models. Theoretical analysis and experimental studies on synthetic and semi-synthetic benchmarks demonstrate that our method achieves significant improvements in both performance and robustness to overfitting across state-of-the-art models.
Off-Policy Evaluation for Human Feedback
Oct 14, 2023Off-policy evaluation (OPE) is important for closing the gap between offline training and evaluation of reinforcement learning (RL), by estimating performance and/or rank of target (evaluation) policies using offline trajectories only. It can improve the safety and efficiency of data collection and policy testing procedures in situations where online deployments are expensive, such as healthcare. However, existing OPE methods fall short in estimating human feedback (HF) signals, as HF may be conditioned over multiple underlying factors and is only sparsely available; as opposed to the agent-defined environmental rewards (used in policy optimization), which are usually determined over parametric functions or distributions. Consequently, the nature of HF signals makes extrapolating accurate OPE estimations to be challenging. To resolve this, we introduce an OPE for HF (OPEHF) framework that revives existing OPE methods in order to accurately evaluate the HF signals. Specifically, we develop an immediate human reward (IHR) reconstruction approach, regularized by environmental knowledge distilled in a latent space that captures the underlying dynamics of state transitions as well as issuing HF signals. Our approach has been tested over two real-world experiments, adaptive in-vivo neurostimulation and intelligent tutoring, as well as in a simulation environment (visual Q&A). Results show that our approach significantly improves the performance toward estimating HF signals accurately, compared to directly applying (variants of) existing OPE methods.
PrACTiS: Perceiver-Attentional Copulas for Time Series
Oct 03, 2023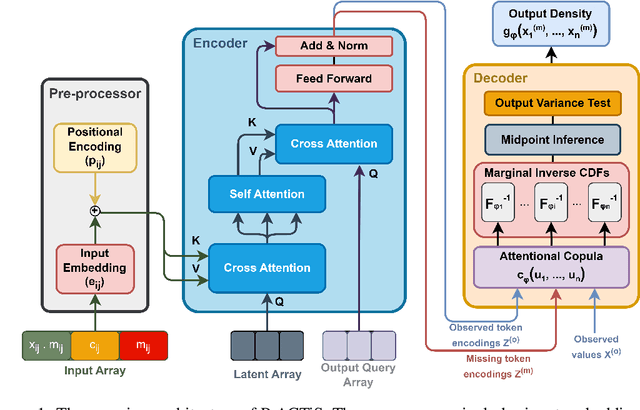
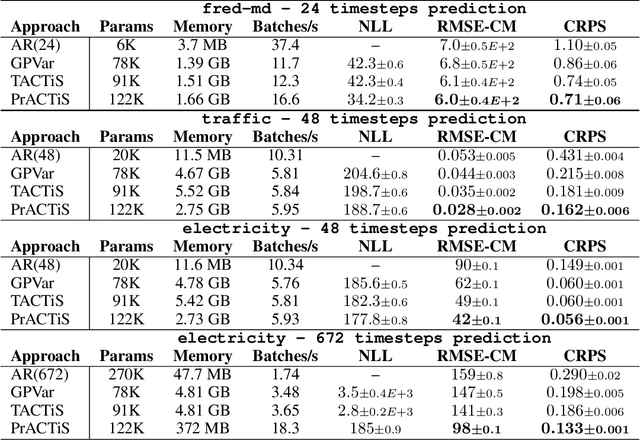
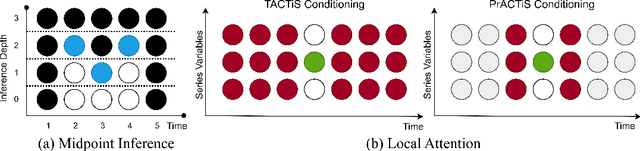

Transformers incorporating copula structures have demonstrated remarkable performance in time series prediction. However, their heavy reliance on self-attention mechanisms demands substantial computational resources, thus limiting their practical utility across a wide range of tasks. In this work, we present a model that combines the perceiver architecture with a copula structure to enhance time-series forecasting. By leveraging the perceiver as the encoder, we efficiently transform complex, high-dimensional, multimodal data into a compact latent space, thereby significantly reducing computational demands. To further reduce complexity, we introduce midpoint inference and local attention mechanisms, enabling the model to capture dependencies within imputed samples effectively. Subsequently, we deploy the copula-based attention and output variance testing mechanism to capture the joint distribution of missing data, while simultaneously mitigating error propagation during prediction. Our experimental results on the unimodal and multimodal benchmarks showcase a consistent 20\% improvement over the state-of-the-art methods, while utilizing less than half of available memory resources.
Individual Treatment Effects in Extreme Regimes
Jun 20, 2023Understanding individual treatment effects in extreme regimes is important for characterizing risks associated with different interventions. This is hindered by the fact that extreme regime data may be hard to collect, as it is scarcely observed in practice. In addressing this issue, we propose a new framework for estimating the individual treatment effect in extreme regimes (ITE$_2$). Specifically, we quantify this effect by the changes in the tail decay rates of potential outcomes in the presence or absence of the treatment. Subsequently, we establish conditions under which ITE$_2$ may be calculated and develop algorithms for its computation. We demonstrate the efficacy of our proposed method on various synthetic and semi-synthetic datasets.