 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeronica Morfi
Learning to detect an animal sound from five examples
May 22, 2023
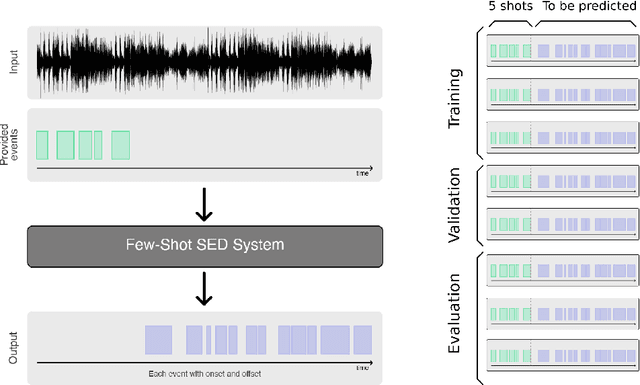
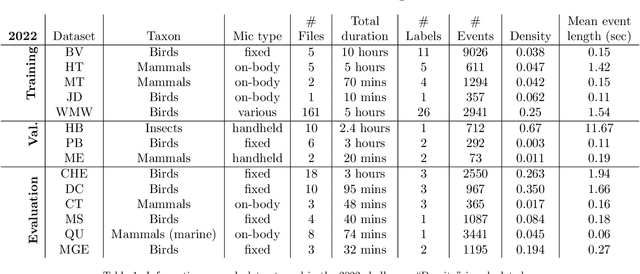
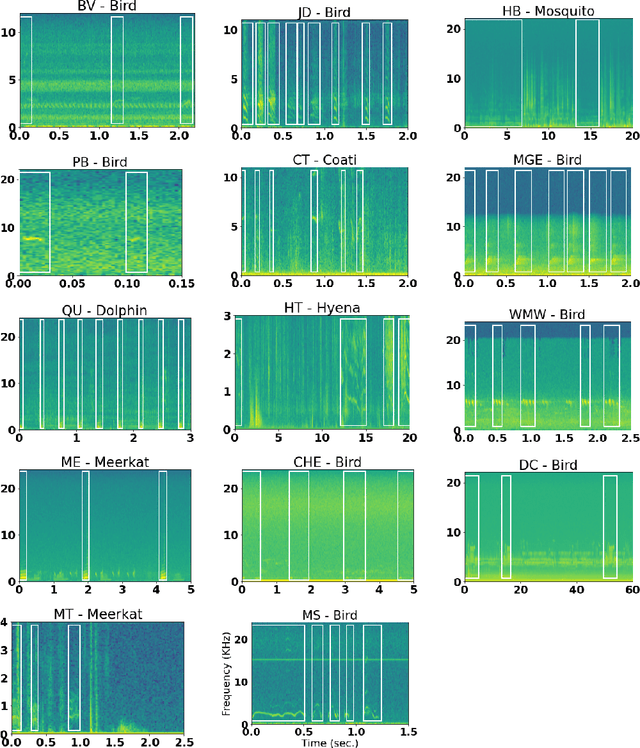
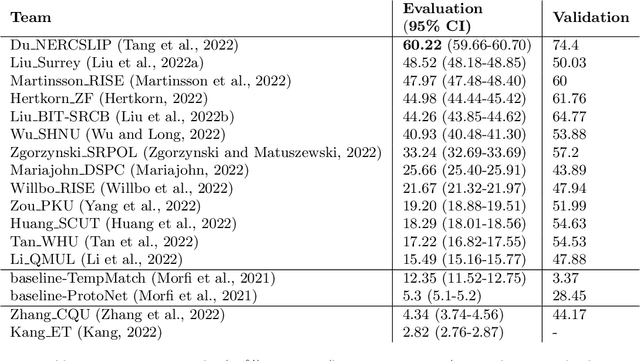
Automatic detection and classification of animal sounds has many applications in biodiversity monitoring and animal behaviour. In the past twenty years, the volume of digitised wildlife sound available has massively increased, and automatic classification through deep learning now shows strong results. However, bioacoustics is not a single task but a vast range of small-scale tasks (such as individual ID, call type, emotional indication) with wide variety in data characteristics, and most bioacoustic tasks do not come with strongly-labelled training data. The standard paradigm of supervised learning, focussed on a single large-scale dataset and/or a generic pre-trained algorithm, is insufficient. In this work we recast bioacoustic sound event detection within the AI framework of few-shot learning. We adapt this framework to sound event detection, such that a system can be given the annotated start/end times of as few as 5 events, and can then detect events in long-duration audio -- even when the sound category was not known at the time of algorithm training. We introduce a collection of open datasets designed to strongly test a system's ability to perform few-shot sound event detections, and we present the results of a public contest to address the task. We show that prototypical networks are a strong-performing method, when enhanced with adaptations for general characteristics of animal sounds. We demonstrate that widely-varying sound event durations are an important factor in performance, as well as non-stationarity, i.e. gradual changes in conditions throughout the duration of a recording. For fine-grained bioacoustic recognition tasks without massive annotated training data, our results demonstrate that few-shot sound event detection is a powerful new method, strongly outperforming traditional signal-processing detection methods in the fully automated scenario.
An evaluation of data augmentation methods for sound scene geotagging
Oct 09, 2021
Sound scene geotagging is a new topic of research which has evolved from acoustic scene classification. It is motivated by the idea of audio surveillance. Not content with only describing a scene in a recording, a machine which can locate where the recording was captured would be of use to many. In this paper we explore a series of common audio data augmentation methods to evaluate which best improves the accuracy of audio geotagging classifiers. Our work improves on the state-of-the-art city geotagging method by 23% in terms of classification accuracy.
Data-Efficient Weakly Supervised Learning for Low-Resource Audio Event Detection Using Deep Learning
Oct 26, 2018


We propose a method to perform audio event detection under the common constraint that only limited training data are available. In training a deep learning system to perform audio event detection, two practical problems arise. Firstly, most datasets are "weakly labelled" having only a list of events present in each recording without any temporal information for training. Secondly, deep neural networks need a very large amount of labelled training data to achieve good quality performance, yet in practice it is difficult to collect enough samples for most classes of interest. In this paper, we propose a data-efficient training of a stacked convolutional and recurrent neural network. This neural network is trained in a multi instance learning setting for which we introduce a new loss function that leads to improved training compared to the usual approaches for weakly supervised learning. We successfully test our approach on two low-resource datasets that lack temporal labels.
Deep Learning for Audio Transcription on Low-Resource Datasets
Jul 11, 2018



In training a deep learning system to perform audio transcription, two practical problems may arise. Firstly, most datasets are weakly labelled, having only a list of events present in each recording without any temporal information for training. Secondly, deep neural networks need a very large amount of labelled training data to achieve good quality performance, yet in practice it is difficult to collect enough samples for most classes of interest. In this paper, we propose factorising the final task of audio transcription into multiple intermediate tasks in order to improve the training performance when dealing with this kind of low-resource datasets. We evaluate three data-efficient approaches of training a stacked convolutional and recurrent neural network for the intermediate tasks. Our results show that different methods of training have different advantages and disadvantages.