 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVivian Lai
Random Projection Layers for Multidimensional Time Series Forecasting
Feb 29, 2024
All-Multi-Layer Perceptron (all-MLP) mixer models have been shown to be effective for time series forecasting problems. However, when such a model is applied to high-dimensional time series (e.g., the time series in a spatial-temporal dataset), its performance is likely to degrade due to overfitting issues. In this paper, we propose an all-MLP time series forecasting architecture, referred to as RPMixer. Our method leverages the ensemble-like behavior of deep neural networks, where each individual block within the network acts like a base learner in an ensemble model, especially when identity mapping residual connections are incorporated. By integrating random projection layers into our model, we increase the diversity among the blocks' outputs, thereby enhancing the overall performance of RPMixer. Extensive experiments conducted on large-scale spatial-temporal forecasting benchmark datasets demonstrate that our proposed method outperforms alternative methods, including both spatial-temporal graph models and general forecasting models.
Towards Mitigating Dimensional Collapse of Representations in Collaborative Filtering
Dec 29, 2023Contrastive Learning (CL) has shown promising performance in collaborative filtering. The key idea is to generate augmentation-invariant embeddings by maximizing the Mutual Information between different augmented views of the same instance. However, we empirically observe that existing CL models suffer from the \textsl{dimensional collapse} issue, where user/item embeddings only span a low-dimension subspace of the entire feature space. This suppresses other dimensional information and weakens the distinguishability of embeddings. Here we propose a non-contrastive learning objective, named nCL, which explicitly mitigates dimensional collapse of representations in collaborative filtering. Our nCL aims to achieve geometric properties of \textsl{Alignment} and \textsl{Compactness} on the embedding space. In particular, the alignment tries to push together representations of positive-related user-item pairs, while compactness tends to find the optimal coding length of user/item embeddings, subject to a given distortion. More importantly, our nCL does not require data augmentation nor negative sampling during training, making it scalable to large datasets. Experimental results demonstrate the superiority of our nCL.
Ego-Network Transformer for Subsequence Classification in Time Series Data
Nov 05, 2023


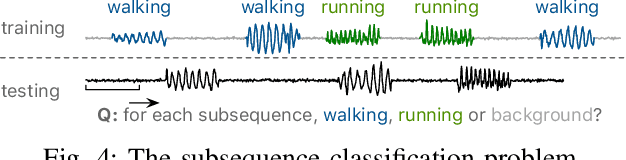
Time series classification is a widely studied problem in the field of time series data mining. Previous research has predominantly focused on scenarios where relevant or foreground subsequences have already been extracted, with each subsequence corresponding to a single label. However, real-world time series data often contain foreground subsequences that are intertwined with background subsequences. Successfully classifying these relevant subsequences requires not only distinguishing between different classes but also accurately identifying the foreground subsequences amidst the background. To address this challenge, we propose a novel subsequence classification method that represents each subsequence as an ego-network, providing crucial nearest neighbor information to the model. The ego-networks of all subsequences collectively form a time series subsequence graph, and we introduce an algorithm to efficiently construct this graph. Furthermore, we have demonstrated the significance of enforcing temporal consistency in the prediction of adjacent subsequences for the subsequence classification problem. To evaluate the effectiveness of our approach, we conducted experiments using 128 univariate and 30 multivariate time series datasets. The experimental results demonstrate the superior performance of our method compared to alternative approaches. Specifically, our method outperforms the baseline on 104 out of 158 datasets.
Temporal Treasure Hunt: Content-based Time Series Retrieval System for Discovering Insights
Nov 05, 2023Time series data is ubiquitous across various domains such as finance, healthcare, and manufacturing, but their properties can vary significantly depending on the domain they originate from. The ability to perform Content-based Time Series Retrieval (CTSR) is crucial for identifying unknown time series examples. However, existing CTSR works typically focus on retrieving time series from a single domain database, which can be inadequate if the user does not know the source of the query time series. This limitation motivates us to investigate the CTSR problem in a scenario where the database contains time series from multiple domains. To facilitate this investigation, we introduce a CTSR benchmark dataset that comprises time series data from a variety of domains, such as motion, power demand, and traffic. This dataset is sourced from a publicly available time series classification dataset archive, making it easily accessible to researchers in the field. We compare several popular methods for modeling and retrieving time series data using this benchmark dataset. Additionally, we propose a novel distance learning model that outperforms the existing methods. Overall, our study highlights the importance of addressing the CTSR problem across multiple domains and provides a useful benchmark dataset for future research.
An Efficient Content-based Time Series Retrieval System
Oct 05, 2023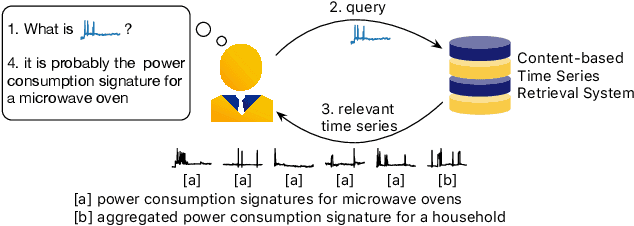
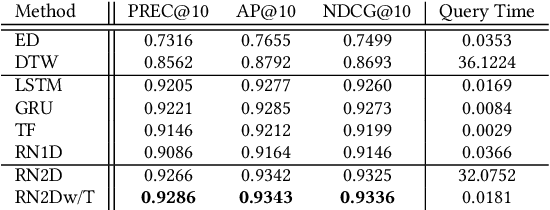
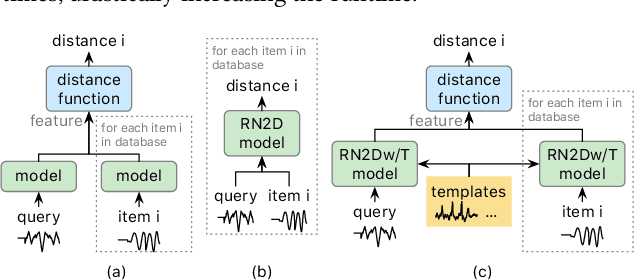
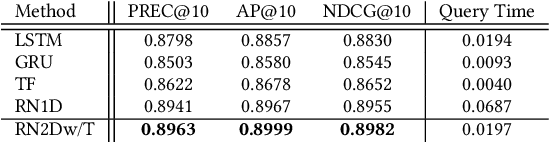
A Content-based Time Series Retrieval (CTSR) system is an information retrieval system for users to interact with time series emerged from multiple domains, such as finance, healthcare, and manufacturing. For example, users seeking to learn more about the source of a time series can submit the time series as a query to the CTSR system and retrieve a list of relevant time series with associated metadata. By analyzing the retrieved metadata, users can gather more information about the source of the time series. Because the CTSR system is required to work with time series data from diverse domains, it needs a high-capacity model to effectively measure the similarity between different time series. On top of that, the model within the CTSR system has to compute the similarity scores in an efficient manner as the users interact with the system in real-time. In this paper, we propose an effective and efficient CTSR model that outperforms alternative models, while still providing reasonable inference runtimes. To demonstrate the capability of the proposed method in solving business problems, we compare it against alternative models using our in-house transaction data. Our findings reveal that the proposed model is the most suitable solution compared to others for our transaction data problem.
Toward a Foundation Model for Time Series Data
Oct 05, 2023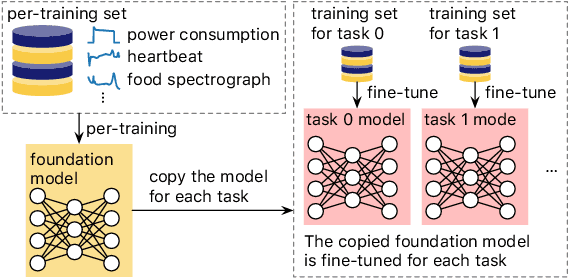
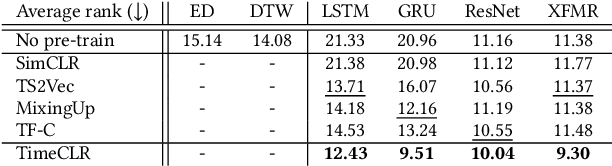
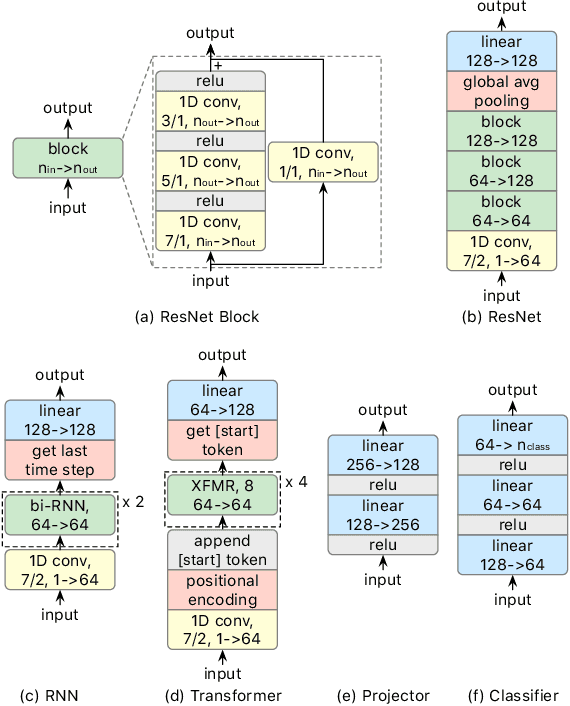
A foundation model is a machine learning model trained on a large and diverse set of data, typically using self-supervised learning-based pre-training techniques, that can be adapted to various downstream tasks. However, current research on time series pre-training has mostly focused on models pre-trained solely on data from a single domain, resulting in a lack of knowledge about other types of time series. However, current research on time series pre-training has predominantly focused on models trained exclusively on data from a single domain. As a result, these models possess domain-specific knowledge that may not be easily transferable to time series from other domains. In this paper, we aim to develop an effective time series foundation model by leveraging unlabeled samples from multiple domains. To achieve this, we repurposed the publicly available UCR Archive and evaluated four existing self-supervised learning-based pre-training methods, along with a novel method, on the datasets. We tested these methods using four popular neural network architectures for time series to understand how the pre-training methods interact with different network designs. Our experimental results show that pre-training improves downstream classification tasks by enhancing the convergence of the fine-tuning process. Furthermore, we found that the proposed pre-training method, when combined with the Transformer model, outperforms the alternatives.
Enhancing Transformers without Self-supervised Learning: A Loss Landscape Perspective in Sequential Recommendation
Aug 20, 2023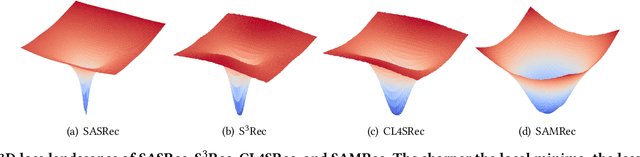
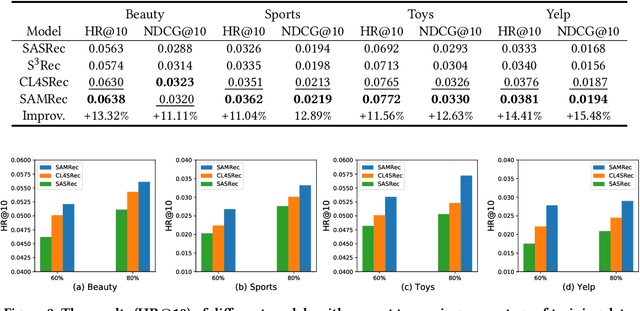
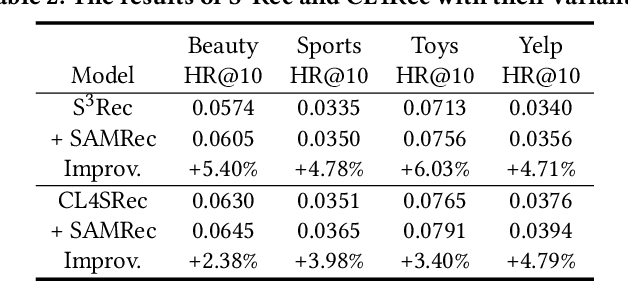
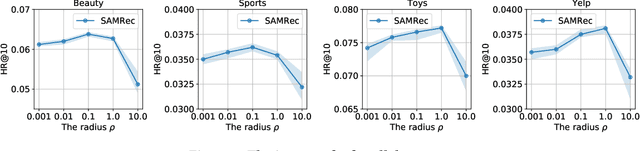
Transformer and its variants are a powerful class of architectures for sequential recommendation, owing to their ability of capturing a user's dynamic interests from their past interactions. Despite their success, Transformer-based models often require the optimization of a large number of parameters, making them difficult to train from sparse data in sequential recommendation. To address the problem of data sparsity, previous studies have utilized self-supervised learning to enhance Transformers, such as pre-training embeddings from item attributes or contrastive data augmentations. However, these approaches encounter several training issues, including initialization sensitivity, manual data augmentations, and large batch-size memory bottlenecks. In this work, we investigate Transformers from the perspective of loss geometry, aiming to enhance the models' data efficiency and generalization in sequential recommendation. We observe that Transformers (e.g., SASRec) can converge to extremely sharp local minima if not adequately regularized. Inspired by the recent Sharpness-Aware Minimization (SAM), we propose SAMRec, which significantly improves the accuracy and robustness of sequential recommendation. SAMRec performs comparably to state-of-the-art self-supervised Transformers, such as S$^3$Rec and CL4SRec, without the need for pre-training or strong data augmentations.
Adversarial Collaborative Filtering for Free
Aug 20, 2023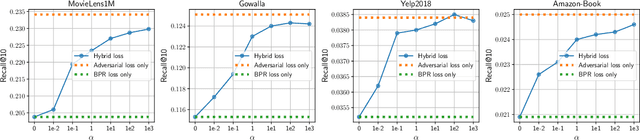
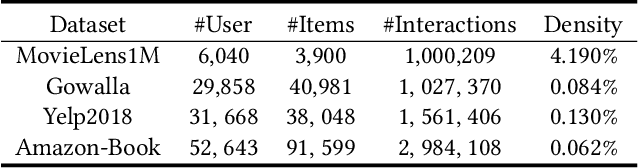
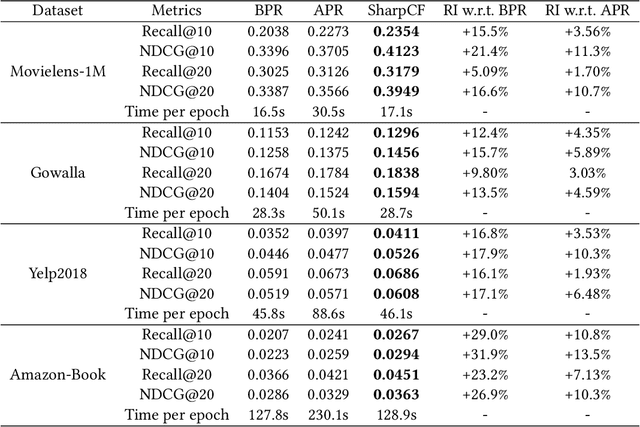
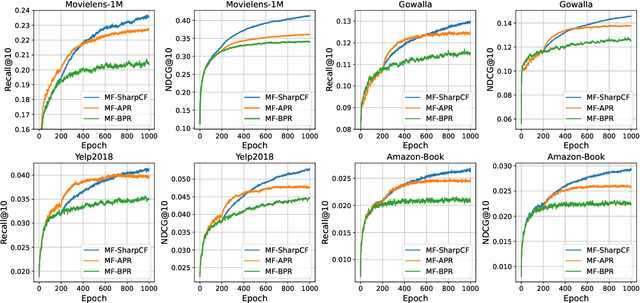
Collaborative Filtering (CF) has been successfully used to help users discover the items of interest. Nevertheless, existing CF methods suffer from noisy data issue, which negatively impacts the quality of recommendation. To tackle this problem, many prior studies leverage adversarial learning to regularize the representations of users/items, which improves both generalizability and robustness. Those methods often learn adversarial perturbations and model parameters under min-max optimization framework. However, there still have two major drawbacks: 1) Existing methods lack theoretical guarantees of why adding perturbations improve the model generalizability and robustness; 2) Solving min-max optimization is time-consuming. In addition to updating the model parameters, each iteration requires additional computations to update the perturbations, making them not scalable for industry-scale datasets. In this paper, we present Sharpness-aware Collaborative Filtering (SharpCF), a simple yet effective method that conducts adversarial training without extra computational cost over the base optimizer. To achieve this goal, we first revisit the existing adversarial collaborative filtering and discuss its connection with recent Sharpness-aware Minimization. This analysis shows that adversarial training actually seeks model parameters that lie in neighborhoods around the optimal model parameters having uniformly low loss values, resulting in better generalizability. To reduce the computational overhead, SharpCF introduces a novel trajectory loss to measure the alignment between current weights and past weights. Experimental results on real-world datasets demonstrate that our SharpCF achieves superior performance with almost zero additional computational cost comparing to adversarial training.
Sharpness-Aware Graph Collaborative Filtering
Jul 18, 2023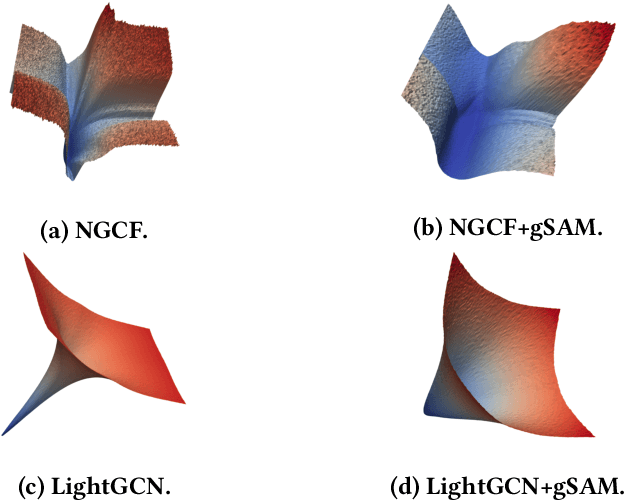
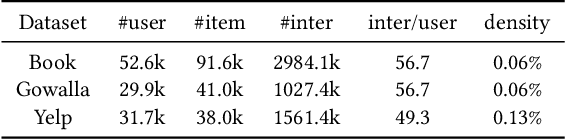
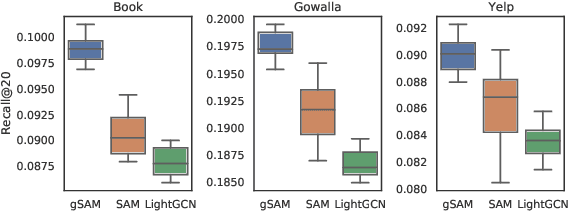
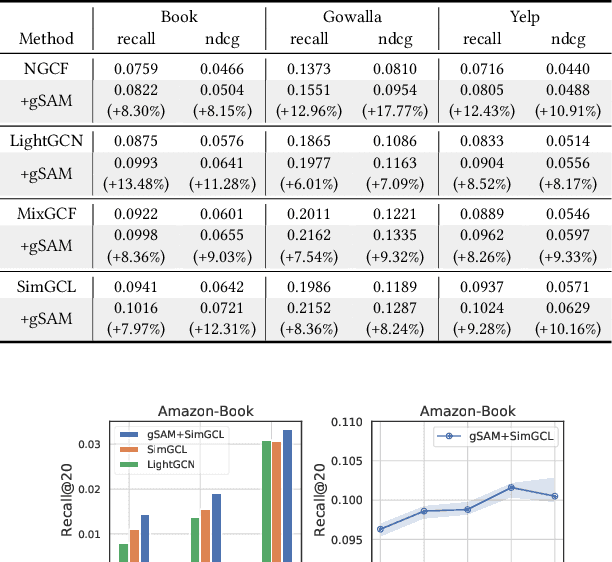
Graph Neural Networks (GNNs) have achieved impressive performance in collaborative filtering. However, GNNs tend to yield inferior performance when the distributions of training and test data are not aligned well. Also, training GNNs requires optimizing non-convex neural networks with an abundance of local and global minima, which may differ widely in their performance at test time. Thus, it is essential to choose the minima carefully. Here we propose an effective training schema, called {gSAM}, under the principle that the \textit{flatter} minima has a better generalization ability than the \textit{sharper} ones. To achieve this goal, gSAM regularizes the flatness of the weight loss landscape by forming a bi-level optimization: the outer problem conducts the standard model training while the inner problem helps the model jump out of the sharp minima. Experimental results show the superiority of our gSAM.
Evaluating NLG Evaluation Metrics: A Measurement Theory Perspective
May 24, 2023We address the fundamental challenge in Natural Language Generation (NLG) model evaluation, the design and validation of evaluation metrics. Recognizing the limitations of existing metrics and issues with human judgment, we propose using measurement theory, the foundation of test design, as a framework for conceptualizing and evaluating the validity and reliability of NLG evaluation metrics. This approach offers a systematic method for defining "good" metrics, developing robust metrics, and assessing metric performance. In this paper, we introduce core concepts in measurement theory in the context of NLG evaluation and key methods to evaluate the performance of NLG metrics. Through this framework, we aim to promote the design, evaluation, and interpretation of valid and reliable metrics, ultimately contributing to the advancement of robust and effective NLG models in real-world settings.