 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVivienne Sze
GMMap: Memory-Efficient Continuous Occupancy Map Using Gaussian Mixture Model
Jun 06, 2023
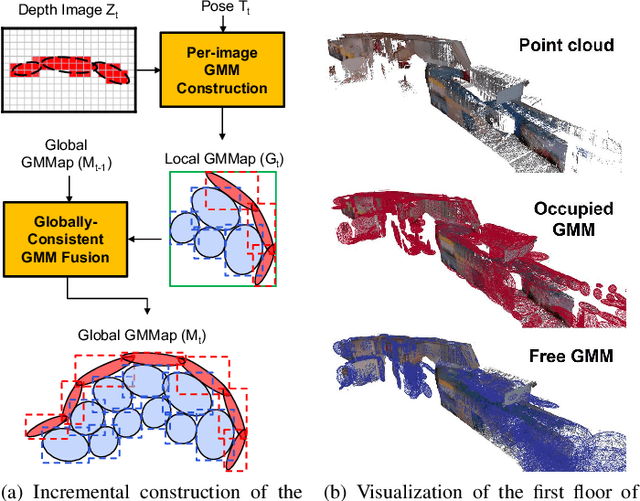

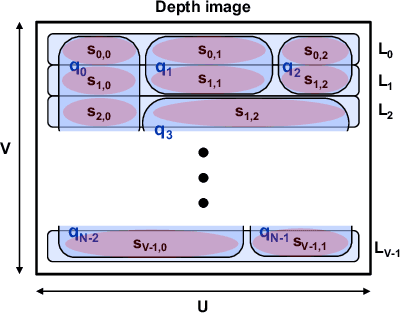
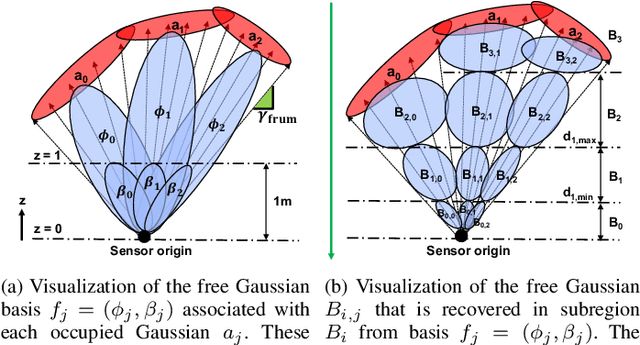
Energy consumption of memory accesses dominates the compute energy in energy-constrained robots which require a compact 3D map of the environment to achieve autonomy. Recent mapping frameworks only focused on reducing the map size while incurring significant memory usage during map construction due to multi-pass processing of each depth image. In this work, we present a memory-efficient continuous occupancy map, named GMMap, that accurately models the 3D environment using a Gaussian Mixture Model (GMM). Memory-efficient GMMap construction is enabled by the single-pass compression of depth images into local GMMs which are directly fused together into a globally-consistent map. By extending Gaussian Mixture Regression to model unexplored regions, occupancy probability is directly computed from Gaussians. Using a low-power ARM Cortex A57 CPU, GMMap can be constructed in real-time at up to 60 images per second. Compared with prior works, GMMap maintains high accuracy while reducing the map size by at least 56%, memory overhead by at least 88%, DRAM access by at least 78%, and energy consumption by at least 69%. Thus, GMMap enables real-time 3D mapping on energy-constrained robots.
HighLight: Efficient and Flexible DNN Acceleration with Hierarchical Structured Sparsity
May 22, 2023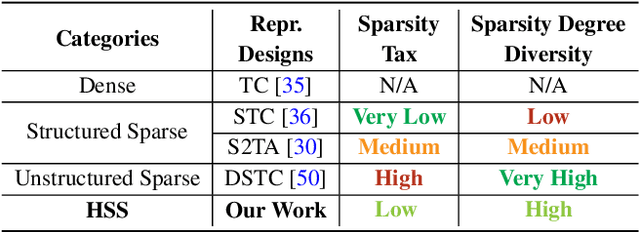

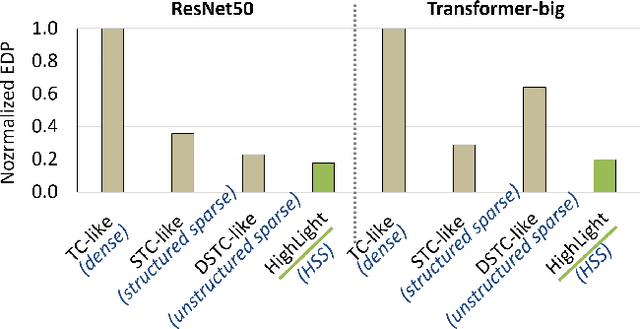
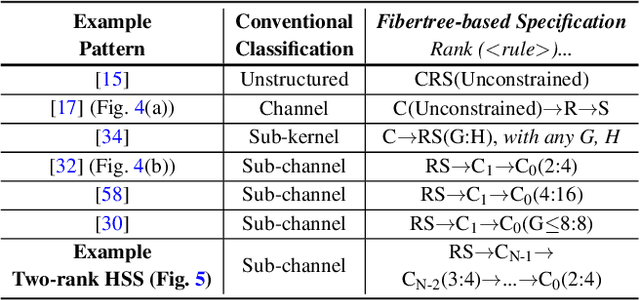
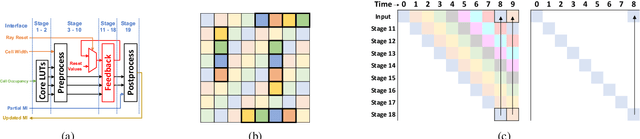
Due to complex interactions among various deep neural network (DNN) optimization techniques, modern DNNs can have weights and activations that are dense or sparse with diverse sparsity degrees. To offer a good trade-off between accuracy and hardware performance, an ideal DNN accelerator should have high flexibility to efficiently translate DNN sparsity into reductions in energy and/or latency without incurring significant complexity overhead. This paper introduces hierarchical structured sparsity (HSS), with the key insight that we can systematically represent diverse sparsity degrees by having them hierarchically composed from multiple simple sparsity patterns. As a result, HSS simplifies the underlying hardware since it only needs to support simple sparsity patterns; this significantly reduces the sparsity acceleration overhead, which improves efficiency. Motivated by such opportunities, we propose a simultaneously efficient and flexible accelerator, named HighLight, to accelerate DNNs that have diverse sparsity degrees (including dense). Due to the flexibility of HSS, different HSS patterns can be introduced to DNNs to meet different applications' accuracy requirements. Compared to existing works, HighLight achieves a geomean of up to 6.4x better energy-delay product (EDP) across workloads with diverse sparsity degrees, and always sits on the EDP-accuracy Pareto frontier for representative DNNs.
Efficient Computation of Map-scale Continuous Mutual Information on Chip in Real Time
Oct 07, 2022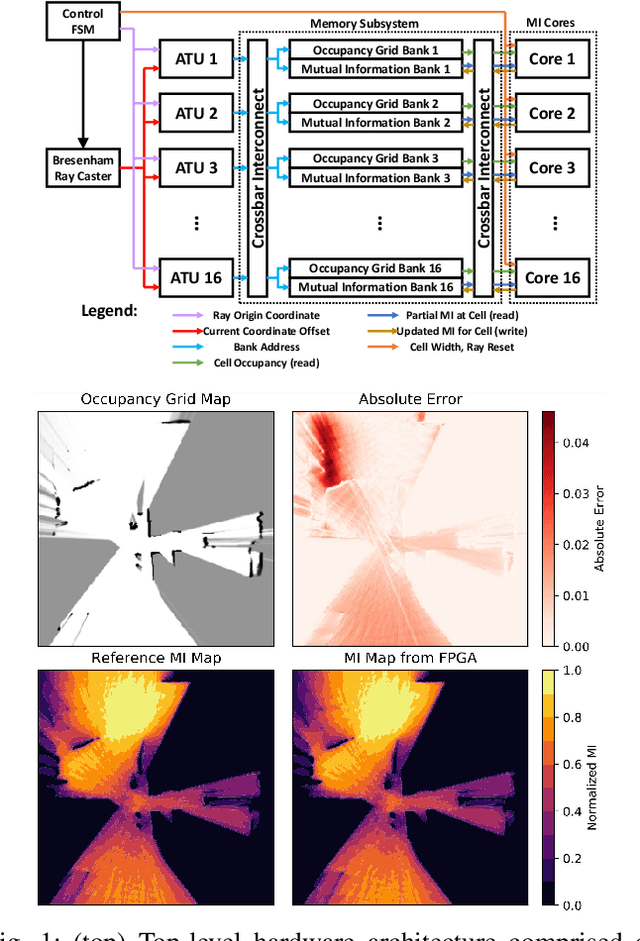
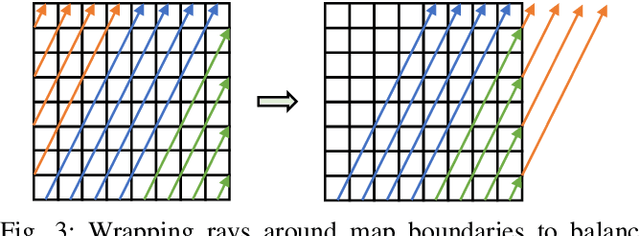
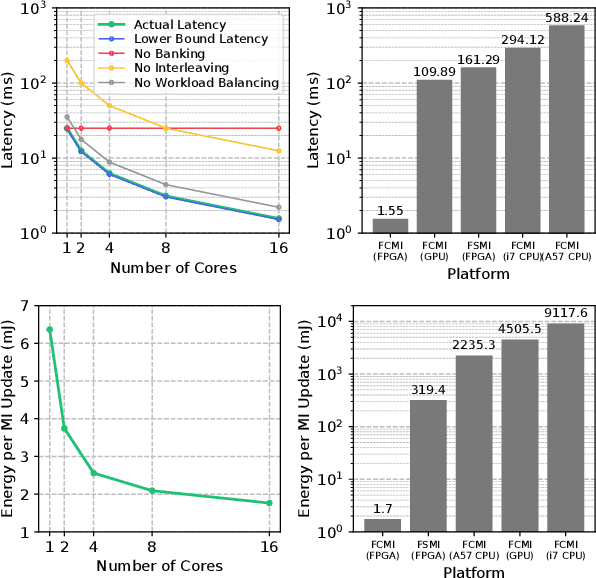
Exploration tasks are essential to many emerging robotics applications, ranging from search and rescue to space exploration. The planning problem for exploration requires determining the best locations for future measurements that will enhance the fidelity of the map, for example, by reducing its total entropy. A widely-studied technique involves computing the Mutual Information (MI) between the current map and future measurements, and utilizing this MI metric to decide the locations for future measurements. However, computing MI for reasonably-sized maps is slow and power hungry, which has been a bottleneck towards fast and efficient robotic exploration. In this paper, we introduce a new hardware accelerator architecture for MI computation that features a low-latency, energy-efficient MI compute core and an optimized memory subsystem that provides sufficient bandwidth to keep the cores fully utilized. The core employs interleaving to counter the recursive algorithm, and workload balancing and numerical approximations to reduce latency and energy consumption. We demonstrate this optimized architecture with a Field-Programmable Gate Array (FPGA) implementation, which can compute MI for all cells in an entire 201-by-201 occupancy grid ({\em e.g.}, representing a 20.1m-by-20.1m map at 0.1m resolution) in 1.55 ms while consuming 1.7 mJ of energy, thus finally rendering MI computation for the whole map real time and at a fraction of the energy cost of traditional compute platforms. For comparison, this particular FPGA implementation running on the Xilinx Zynq-7000 platform is two orders of magnitude faster and consumes three orders of magnitude less energy per MI map compute, when compared to a baseline GPU implementation running on an NVIDIA GeForce GTX 980 platform. The improvements are more pronounced when compared to CPU implementations of equivalent algorithms.
Gemino: Practical and Robust Neural Compression for Video Conferencing
Sep 22, 2022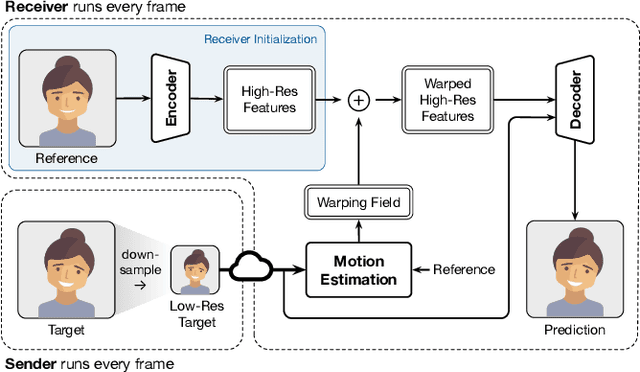
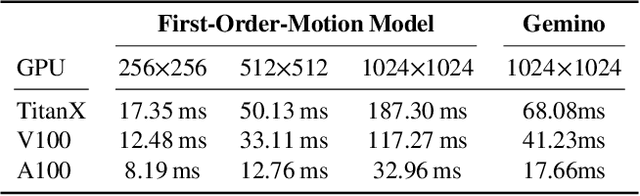


Video conferencing systems suffer from poor user experience when network conditions deteriorate because current video codecs simply cannot operate at extremely low bitrates. Recently, several neural alternatives have been proposed that reconstruct talking head videos at very low bitrates using sparse representations of each frame such as facial landmark information. However, these approaches produce poor reconstructions in scenarios with major movement or occlusions over the course of a call, and do not scale to higher resolutions. We design Gemino, a new neural compression system for video conferencing based on a novel high-frequency-conditional super-resolution pipeline. Gemino upsamples a very low-resolution version of each target frame while enhancing high-frequency details (e.g., skin texture, hair, etc.) based on information extracted from a single high-resolution reference image. We use a multi-scale architecture that runs different components of the model at different resolutions, allowing it to scale to resolutions comparable to 720p, and we personalize the model to learn specific details of each person, achieving much better fidelity at low bitrates. We implement Gemino atop aiortc, an open-source Python implementation of WebRTC, and show that it operates on 1024x1024 videos in real-time on a A100 GPU, and achieves 2.9x lower bitrate than traditional video codecs for the same perceptual quality.
Developing a Series of AI Challenges for the United States Department of the Air Force
Jul 14, 2022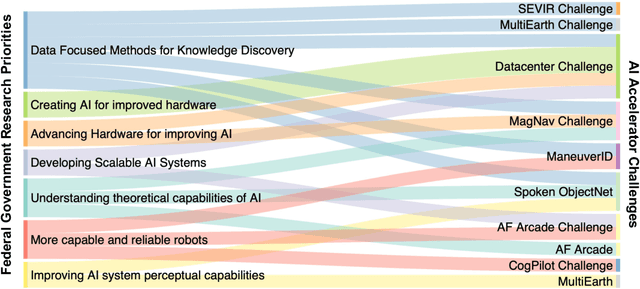


Through a series of federal initiatives and orders, the U.S. Government has been making a concerted effort to ensure American leadership in AI. These broad strategy documents have influenced organizations such as the United States Department of the Air Force (DAF). The DAF-MIT AI Accelerator is an initiative between the DAF and MIT to bridge the gap between AI researchers and DAF mission requirements. Several projects supported by the DAF-MIT AI Accelerator are developing public challenge problems that address numerous Federal AI research priorities. These challenges target priorities by making large, AI-ready datasets publicly available, incentivizing open-source solutions, and creating a demand signal for dual use technologies that can stimulate further research. In this article, we describe these public challenges being developed and how their application contributes to scientific advances.
Sparseloop: An Analytical Approach To Sparse Tensor Accelerator Modeling
May 12, 2022
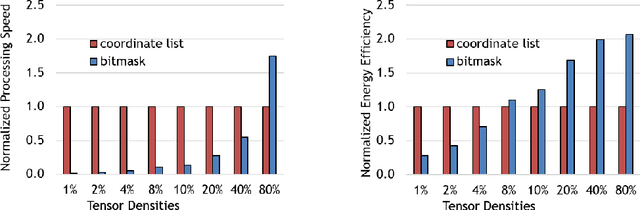
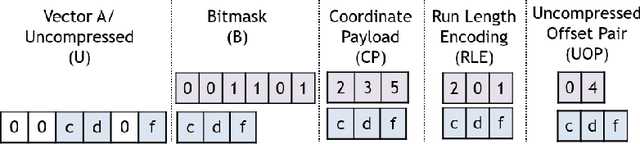

In recent years, many accelerators have been proposed to efficiently process sparse tensor algebra applications (e.g., sparse neural networks). However, these proposals are single points in a large and diverse design space. The lack of systematic description and modeling support for these sparse tensor accelerators impedes hardware designers from efficient and effective design space exploration. This paper first presents a unified taxonomy to systematically describe the diverse sparse tensor accelerator design space. Based on the proposed taxonomy, it then introduces Sparseloop, the first fast, accurate, and flexible analytical modeling framework to enable early-stage evaluation and exploration of sparse tensor accelerators. Sparseloop comprehends a large set of architecture specifications, including various dataflows and sparse acceleration features (e.g., elimination of zero-based compute). Using these specifications, Sparseloop evaluates a design's processing speed and energy efficiency while accounting for data movement and compute incurred by the employed dataflow as well as the savings and overhead introduced by the sparse acceleration features using stochastic tensor density models. Across representative accelerators and workloads, Sparseloop achieves over 2000 times faster modeling speed than cycle-level simulations, maintains relative performance trends, and achieves 0.1% to 8% average error. With a case study, we demonstrate Sparseloop's ability to help reveal important insights for designing sparse tensor accelerators (e.g., it is important to co-design orthogonal design aspects).
Searching for Efficient Multi-Stage Vision Transformers
Sep 01, 2021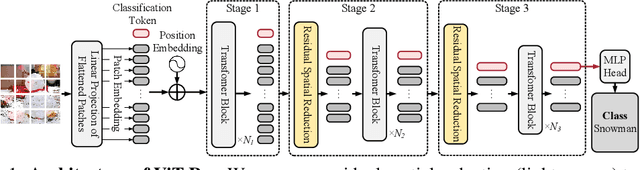


Vision Transformer (ViT) demonstrates that Transformer for natural language processing can be applied to computer vision tasks and result in comparable performance to convolutional neural networks (CNN), which have been studied and adopted in computer vision for years. This naturally raises the question of how the performance of ViT can be advanced with design techniques of CNN. To this end, we propose to incorporate two techniques and present ViT-ResNAS, an efficient multi-stage ViT architecture designed with neural architecture search (NAS). First, we propose residual spatial reduction to decrease sequence lengths for deeper layers and utilize a multi-stage architecture. When reducing lengths, we add skip connections to improve performance and stabilize training deeper networks. Second, we propose weight-sharing NAS with multi-architectural sampling. We enlarge a network and utilize its sub-networks to define a search space. A super-network covering all sub-networks is then trained for fast evaluation of their performance. To efficiently train the super-network, we propose to sample and train multiple sub-networks with one forward-backward pass. After that, evolutionary search is performed to discover high-performance network architectures. Experiments on ImageNet demonstrate that ViT-ResNAS achieves better accuracy-MACs and accuracy-throughput trade-offs than the original DeiT and other strong baselines of ViT. Code is available at https://github.com/yilunliao/vit-search.
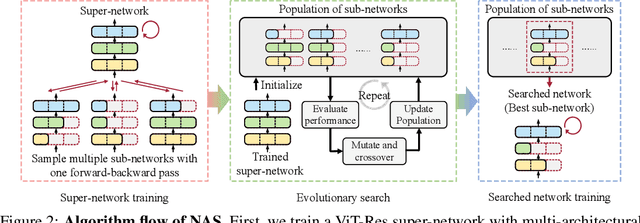
NetAdaptV2: Efficient Neural Architecture Search with Fast Super-Network Training and Architecture Optimization
Mar 31, 2021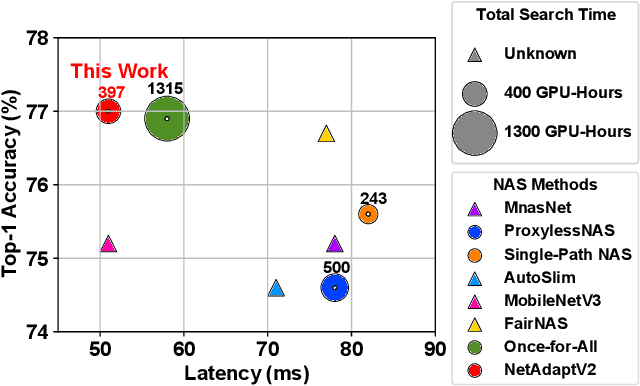
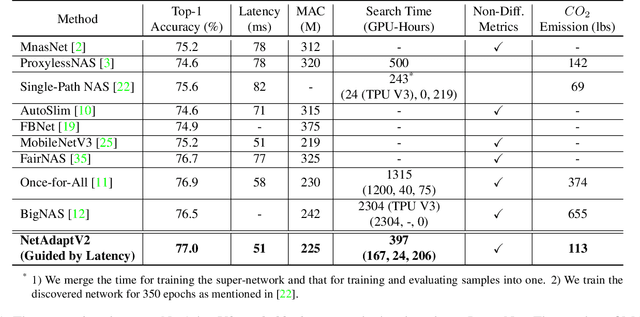

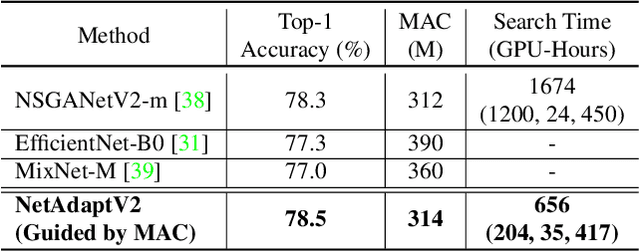
Neural architecture search (NAS) typically consists of three main steps: training a super-network, training and evaluating sampled deep neural networks (DNNs), and training the discovered DNN. Most of the existing efforts speed up some steps at the cost of a significant slowdown of other steps or sacrificing the support of non-differentiable search metrics. The unbalanced reduction in the time spent per step limits the total search time reduction, and the inability to support non-differentiable search metrics limits the performance of discovered DNNs. In this paper, we present NetAdaptV2 with three innovations to better balance the time spent for each step while supporting non-differentiable search metrics. First, we propose channel-level bypass connections that merge network depth and layer width into a single search dimension to reduce the time for training and evaluating sampled DNNs. Second, ordered dropout is proposed to train multiple DNNs in a single forward-backward pass to decrease the time for training a super-network. Third, we propose the multi-layer coordinate descent optimizer that considers the interplay of multiple layers in each iteration of optimization to improve the performance of discovered DNNs while supporting non-differentiable search metrics. With these innovations, NetAdaptV2 reduces the total search time by up to $5.8\times$ on ImageNet and $2.4\times$ on NYU Depth V2, respectively, and discovers DNNs with better accuracy-latency/accuracy-MAC trade-offs than state-of-the-art NAS works. Moreover, the discovered DNN outperforms NAS-discovered MobileNetV3 by 1.8% higher top-1 accuracy with the same latency. The project website is http://netadapt.mit.edu.
Depth Map Estimation of Dynamic Scenes Using Prior Depth Information
Feb 02, 2020
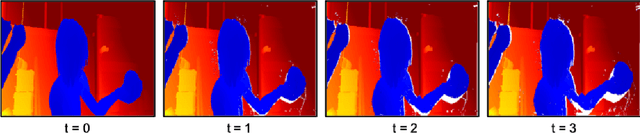

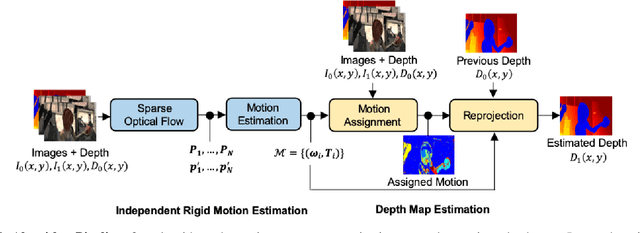
Depth information is useful for many applications. Active depth sensors are appealing because they obtain dense and accurate depth maps. However, due to issues that range from power constraints to multi-sensor interference, these sensors cannot always be continuously used. To overcome this limitation, we propose an algorithm that estimates depth maps using concurrently collected images and a previously measured depth map for dynamic scenes, where both the camera and objects in the scene may be independently moving. To estimate depth in these scenarios, our algorithm models the dynamic scene motion using independent and rigid motions. It then uses the previous depth map to efficiently estimate these rigid motions and obtain a new depth map. Our goal is to balance the acquisition of depth between the active depth sensor and computation, without incurring a large computational cost. Thus, we leverage the prior depth information to avoid computationally expensive operations like dense optical flow estimation or segmentation used in similar approaches. Our approach can obtain dense depth maps at up to real-time (30 FPS) on a standard laptop computer, which is orders of magnitude faster than similar approaches. When evaluated using RGB-D datasets of various dynamic scenes, our approach estimates depth maps with a mean relative error of 2.5% while reducing the active depth sensor usage by over 90%.
Design Considerations for Efficient Deep Neural Networks on Processing-in-Memory Accelerators
Dec 18, 2019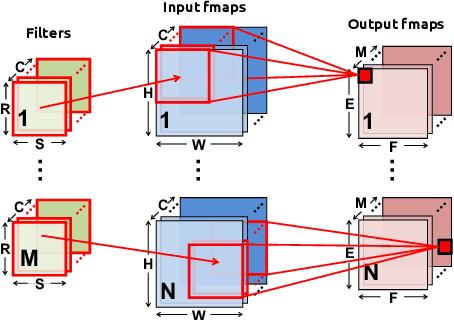
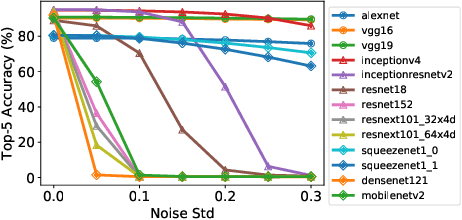
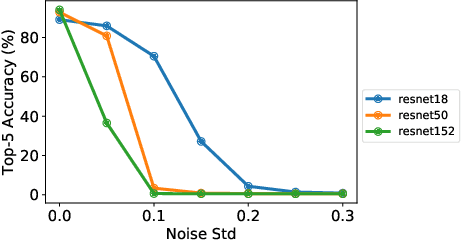
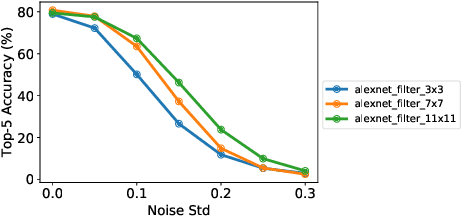
This paper describes various design considerations for deep neural networks that enable them to operate efficiently and accurately on processing-in-memory accelerators. We highlight important properties of these accelerators and the resulting design considerations using experiments conducted on various state-of-the-art deep neural networks with the large-scale ImageNet dataset.