 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSertac Karaman
NVINS: Robust Visual Inertial Navigation Fused with NeRF-augmented Camera Pose Regressor and Uncertainty Quantification
Apr 01, 2024
In recent years, Neural Radiance Fields (NeRF) have emerged as a powerful tool for 3D reconstruction and novel view synthesis. However, the computational cost of NeRF rendering and degradation in quality due to the presence of artifacts pose significant challenges for its application in real-time and robust robotic tasks, especially on embedded systems. This paper introduces a novel framework that integrates NeRF-derived localization information with Visual-Inertial Odometry(VIO) to provide a robust solution for robotic navigation in a real-time. By training an absolute pose regression network with augmented image data rendered from a NeRF and quantifying its uncertainty, our approach effectively counters positional drift and enhances system reliability. We also establish a mathematically sound foundation for combining visual inertial navigation with camera localization neural networks, considering uncertainty under a Bayesian framework. Experimental validation in the photorealistic simulation environment demonstrates significant improvements in accuracy compared to a conventional VIO approach.
Multi-Fidelity Reinforcement Learning for Time-Optimal Quadrotor Re-planning
Mar 13, 2024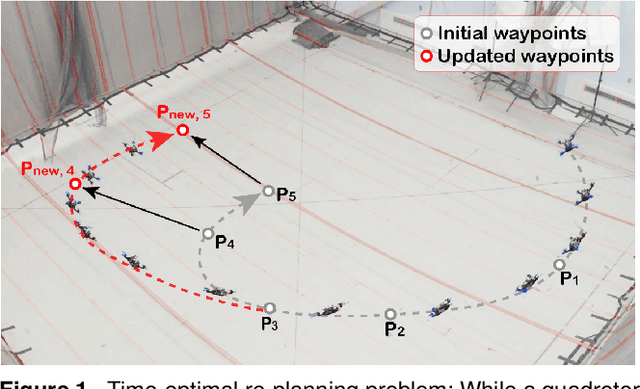
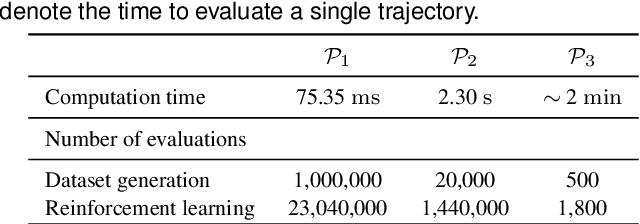
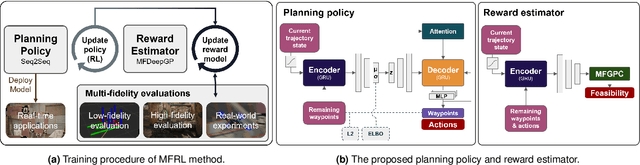
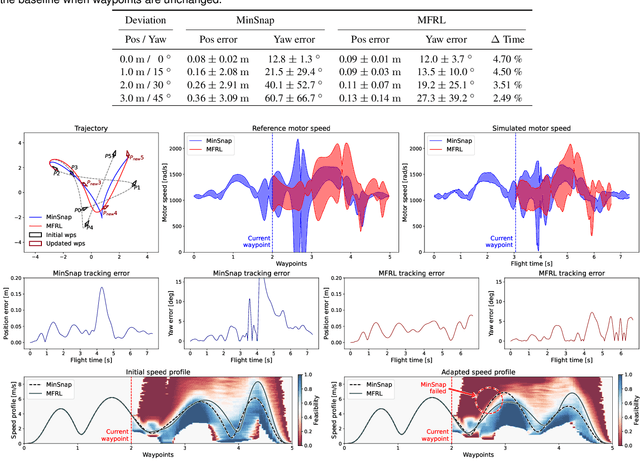
High-speed online trajectory planning for UAVs poses a significant challenge due to the need for precise modeling of complex dynamics while also being constrained by computational limitations. This paper presents a multi-fidelity reinforcement learning method (MFRL) that aims to effectively create a realistic dynamics model and simultaneously train a planning policy that can be readily deployed in real-time applications. The proposed method involves the co-training of a planning policy and a reward estimator; the latter predicts the performance of the policy's output and is trained efficiently through multi-fidelity Bayesian optimization. This optimization approach models the correlation between different fidelity levels, thereby constructing a high-fidelity model based on a low-fidelity foundation, which enables the accurate development of the reward model with limited high-fidelity experiments. The framework is further extended to include real-world flight experiments in reinforcement learning training, allowing the reward model to precisely reflect real-world constraints and broadening the policy's applicability to real-world scenarios. We present rigorous evaluations by training and testing the planning policy in both simulated and real-world environments. The resulting trained policy not only generates faster and more reliable trajectories compared to the baseline snap minimization method, but it also achieves trajectory updates in 2 ms on average, while the baseline method takes several minutes.
Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Models
Oct 26, 2023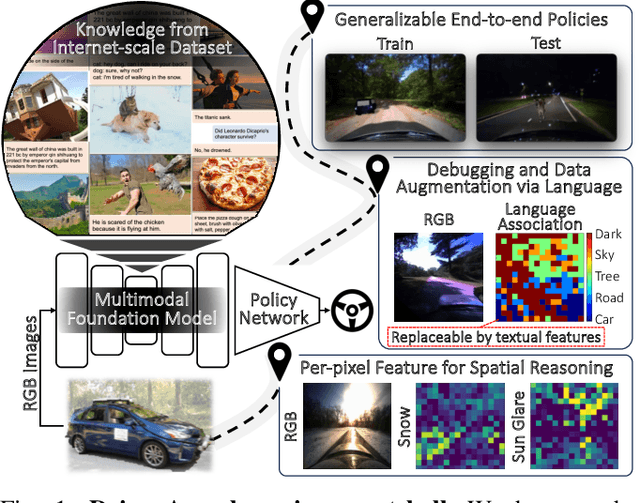
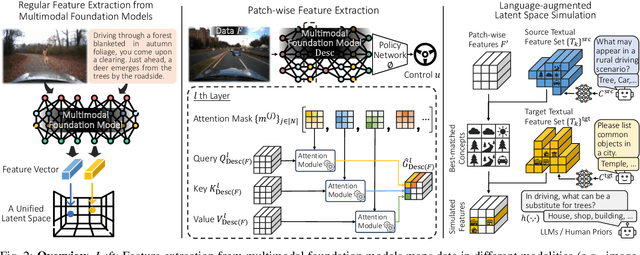
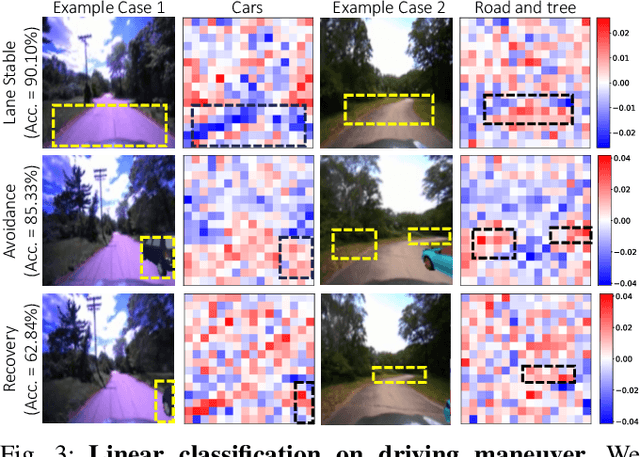
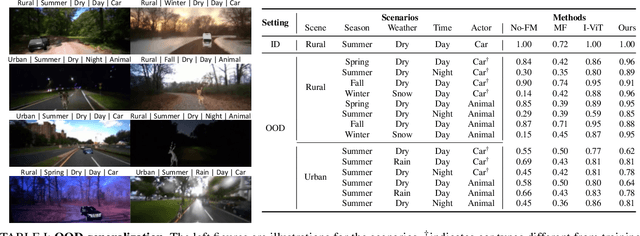
As autonomous driving technology matures, end-to-end methodologies have emerged as a leading strategy, promising seamless integration from perception to control via deep learning. However, existing systems grapple with challenges such as unexpected open set environments and the complexity of black-box models. At the same time, the evolution of deep learning introduces larger, multimodal foundational models, offering multi-modal visual and textual understanding. In this paper, we harness these multimodal foundation models to enhance the robustness and adaptability of autonomous driving systems, enabling out-of-distribution, end-to-end, multimodal, and more explainable autonomy. Specifically, we present an approach to apply end-to-end open-set (any environment/scene) autonomous driving that is capable of providing driving decisions from representations queryable by image and text. To do so, we introduce a method to extract nuanced spatial (pixel/patch-aligned) features from transformers to enable the encapsulation of both spatial and semantic features. Our approach (i) demonstrates unparalleled results in diverse tests while achieving significantly greater robustness in out-of-distribution situations, and (ii) allows the incorporation of latent space simulation (via text) for improved training (data augmentation via text) and policy debugging. We encourage the reader to check our explainer video at https://www.youtube.com/watch?v=4n-DJf8vXxo&feature=youtu.be and to view the code and demos on our project webpage at https://drive-anywhere.github.io/.
GMMap: Memory-Efficient Continuous Occupancy Map Using Gaussian Mixture Model
Jun 06, 2023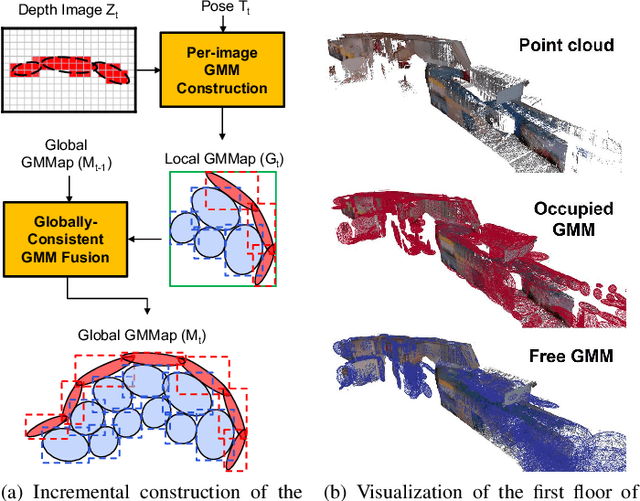

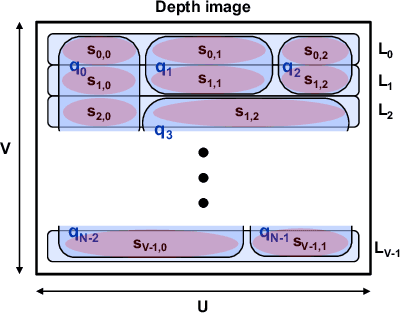
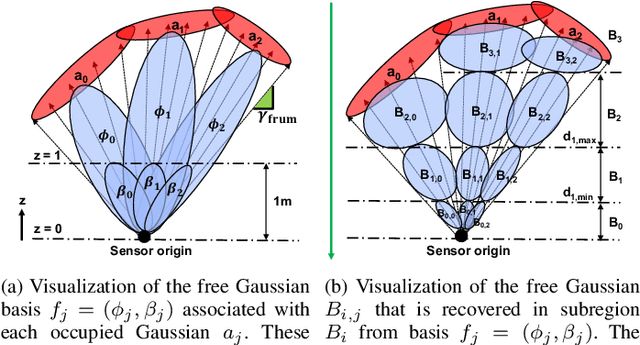
Energy consumption of memory accesses dominates the compute energy in energy-constrained robots which require a compact 3D map of the environment to achieve autonomy. Recent mapping frameworks only focused on reducing the map size while incurring significant memory usage during map construction due to multi-pass processing of each depth image. In this work, we present a memory-efficient continuous occupancy map, named GMMap, that accurately models the 3D environment using a Gaussian Mixture Model (GMM). Memory-efficient GMMap construction is enabled by the single-pass compression of depth images into local GMMs which are directly fused together into a globally-consistent map. By extending Gaussian Mixture Regression to model unexplored regions, occupancy probability is directly computed from Gaussians. Using a low-power ARM Cortex A57 CPU, GMMap can be constructed in real-time at up to 60 images per second. Compared with prior works, GMMap maintains high accuracy while reducing the map size by at least 56%, memory overhead by at least 88%, DRAM access by at least 78%, and energy consumption by at least 69%. Thus, GMMap enables real-time 3D mapping on energy-constrained robots.
Learning When to Ask for Help: Transferring Human Knowledge through Part-Time Demonstration
May 25, 2023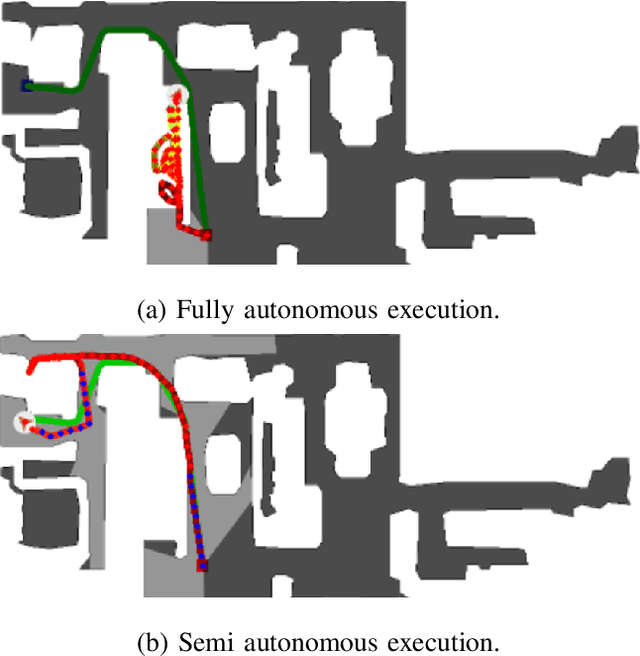
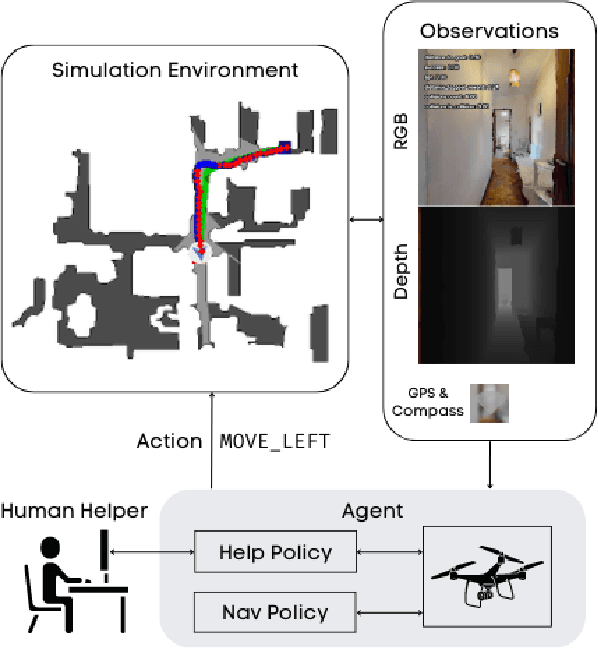
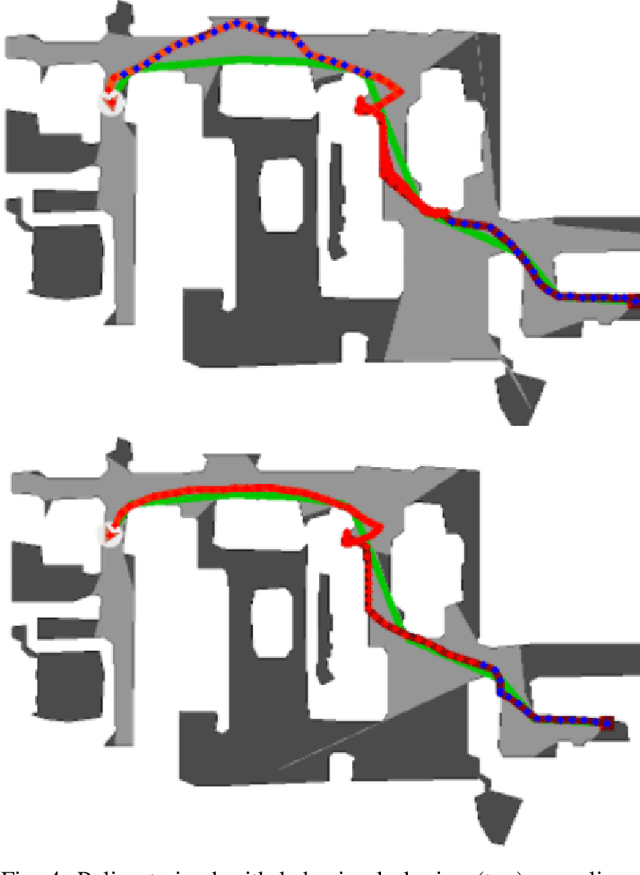
Robots operating alongside humans often encounter unfamiliar environments that make autonomous task completion challenging. Though improving models and increasing dataset size can enhance a robot's performance in unseen environments, dataset generation and model refinement may be impractical in every unfamiliar environment. Approaches that utilize human demonstration through manual operation can aid in generalizing to these unfamiliar environments, but often require significant human effort and expertise to achieve satisfactory task performance. To address these challenges, we propose leveraging part-time human interaction for redirection of robots during failed task execution. We train a lightweight help policy that allows robots to learn when to proceed autonomously or request human assistance at times of uncertainty. By incorporating part-time human intervention, robots recover quickly from their mistakes. Our best performing policy yields a 20 percent increase in path-length weighted success with only a 21 percent human interaction ratio. This approach provides a practical means for robots to interact and learn from humans in real-world settings, facilitating effective task completion without the need for significant human intervention.
Multi-Abstractive Neural Controller: An Efficient Hierarchical Control Architecture for Interactive Driving
May 24, 2023
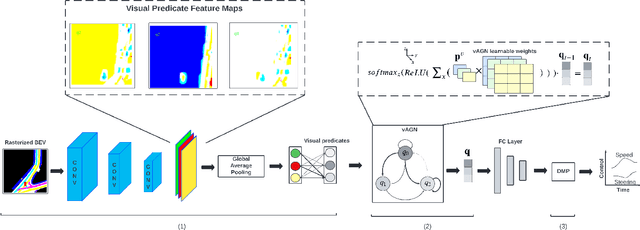
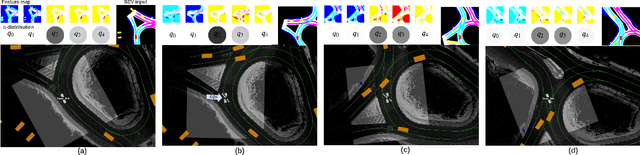
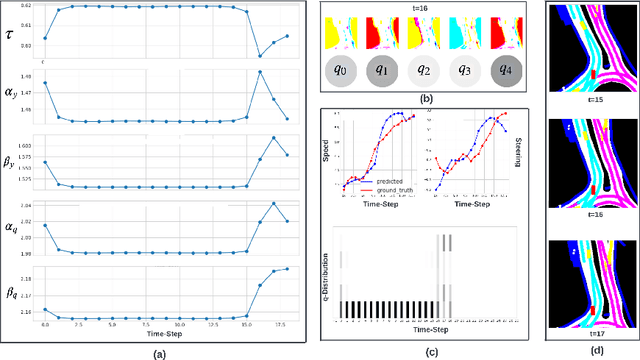
As learning-based methods make their way from perception systems to planning/control stacks, robot control systems have started to enjoy the benefits that data-driven methods provide. Because control systems directly affect the motion of the robot, data-driven methods, especially black box approaches, need to be used with caution considering aspects such as stability and interpretability. In this paper, we describe a differentiable and hierarchical control architecture. The proposed representation, called \textit{multi-abstractive neural controller}, uses the input image to control the transitions within a novel discrete behavior planner (referred to as the visual automaton generative network, or \textit{vAGN}). The output of a vAGN controls the parameters of a set of dynamic movement primitives which provides the system controls. We train this neural controller with real-world driving data via behavior cloning and show improved explainability, sample efficiency, and similarity to human driving.
Studying the Impact of Semi-Cooperative Drivers on Overall Highway Flow
Apr 23, 2023
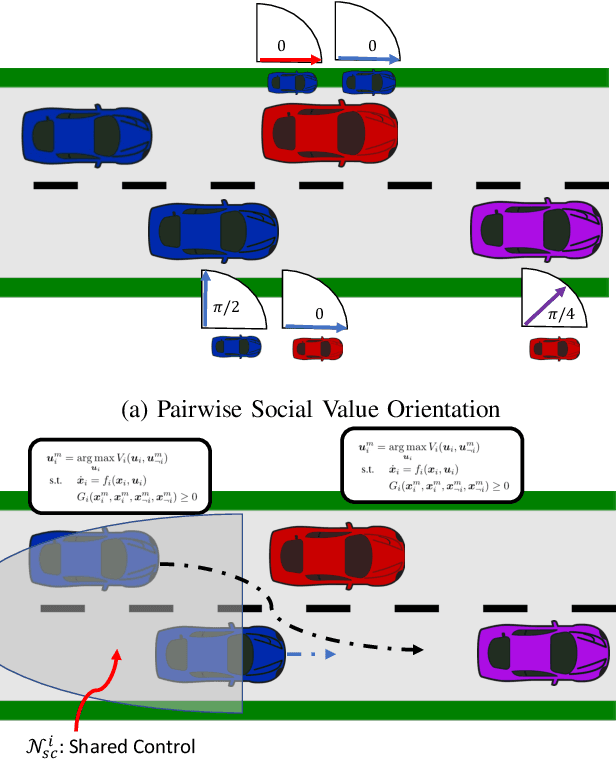
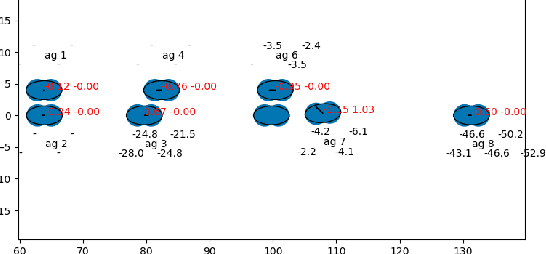

Semi-cooperative behaviors are intrinsic properties of human drivers and should be considered for autonomous driving. In addition, new autonomous planners can consider the social value orientation (SVO) of human drivers to generate socially-compliant trajectories. Yet the overall impact on traffic flow for this new class of planners remain to be understood. In this work, we present study of implicit semi-cooperative driving where agents deploy a game-theoretic version of iterative best response assuming knowledge of the SVOs of other agents. We simulate nominal traffic flow and investigate whether the proportion of prosocial agents on the road impact individual or system-wide driving performance. Experiments show that the proportion of prosocial agents has a minor impact on overall traffic flow and that benefits of semi-cooperation disproportionally affect egoistic and high-speed drivers.
Infrastructure-based End-to-End Learning and Prevention of Driver Failure
Mar 21, 2023

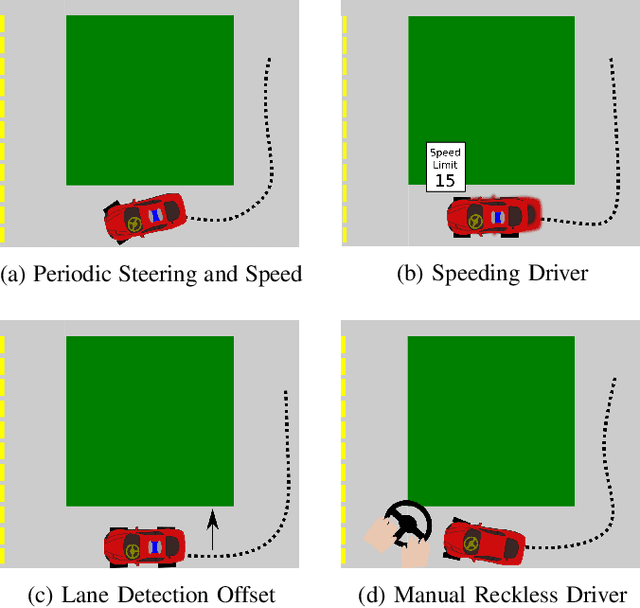
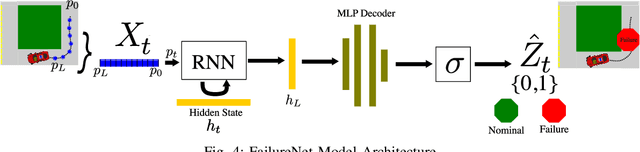
Intelligent intersection managers can improve safety by detecting dangerous drivers or failure modes in autonomous vehicles, warning oncoming vehicles as they approach an intersection. In this work, we present FailureNet, a recurrent neural network trained end-to-end on trajectories of both nominal and reckless drivers in a scaled miniature city. FailureNet observes the poses of vehicles as they approach an intersection and detects whether a failure is present in the autonomy stack, warning cross-traffic of potentially dangerous drivers. FailureNet can accurately identify control failures, upstream perception errors, and speeding drivers, distinguishing them from nominal driving. The network is trained and deployed with autonomous vehicles in the MiniCity. Compared to speed or frequency-based predictors, FailureNet's recurrent neural network structure provides improved predictive power, yielding upwards of 84% accuracy when deployed on hardware.
Agility and Target Distribution in the Dynamic Stochastic Traveling Salesman Problem
Feb 01, 2023An important variant of the classic Traveling Salesman Problem (TSP) is the Dynamic TSP, in which a system with dynamic constraints is tasked with visiting a set of n target locations (in any order) in the shortest amount of time. Such tasks arise naturally in many robotic motion planning problems, particularly in exploration, surveillance and reconnaissance, and classical TSP algorithms on graphs are typically inapplicable in this setting. An important question about such problems is: if the target points are random, what is the length of the tour (either in expectation or as a concentration bound) as n grows? This problem is the Dynamic Stochastic TSP (DSTSP), and has been studied both for specific important vehicle models and for general dynamic systems; however, in general only the order of growth is known. In this work, we explore the connection between the distribution from which the targets are drawn and the dynamics of the system, yielding a more precise lower bound on tour length as well as a matching upper bound for the case of symmetric (or driftless) systems. We then extend the symmetric dynamics results to the case when the points are selected by a (non-random) adversary whose goal is to maximize the length, thus showing worst-case bounds on the tour length.
Learning and Predicting Multimodal Vehicle Action Distributions in a Unified Probabilistic Model Without Labels
Dec 14, 2022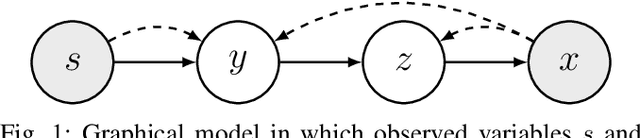
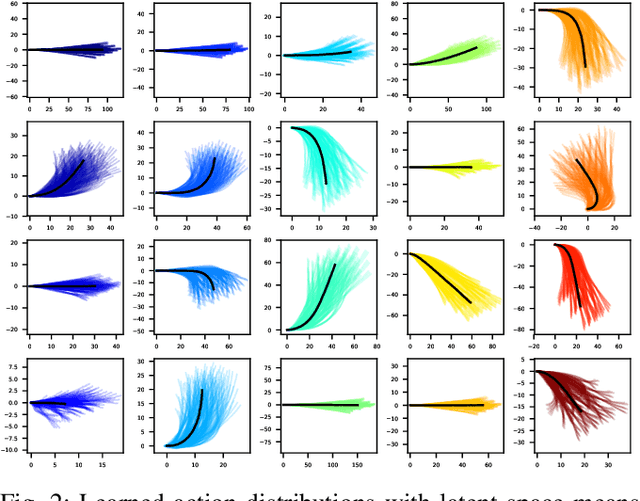


We present a unified probabilistic model that learns a representative set of discrete vehicle actions and predicts the probability of each action given a particular scenario. Our model also enables us to estimate the distribution over continuous trajectories conditioned on a scenario, representing what each discrete action would look like if executed in that scenario. While our primary objective is to learn representative action sets, these capabilities combine to produce accurate multimodal trajectory predictions as a byproduct. Although our learned action representations closely resemble semantically meaningful categories (e.g., "go straight", "turn left", etc.), our method is entirely self-supervised and does not utilize any manually generated labels or categories. Our method builds upon recent advances in variational inference and deep unsupervised clustering, resulting in full distribution estimates based on deterministic model evaluations.