 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuy Rosman
Blending Data-Driven Priors in Dynamic Games
Feb 23, 2024
As intelligent robots like autonomous vehicles become increasingly deployed in the presence of people, the extent to which these systems should leverage model-based game-theoretic planners versus data-driven policies for safe, interaction-aware motion planning remains an open question. Existing dynamic game formulations assume all agents are task-driven and behave optimally. However, in reality, humans tend to deviate from the decisions prescribed by these models, and their behavior is better approximated under a noisy-rational paradigm. In this work, we investigate a principled methodology to blend a data-driven reference policy with an optimization-based game-theoretic policy. We formulate KLGame, a type of non-cooperative dynamic game with Kullback-Leibler (KL) regularization with respect to a general, stochastic, and possibly multi-modal reference policy. Our method incorporates, for each decision maker, a tunable parameter that permits modulation between task-driven and data-driven behaviors. We propose an efficient algorithm for computing multimodal approximate feedback Nash equilibrium strategies of KLGame in real time. Through a series of simulated and real-world autonomous driving scenarios, we demonstrate that KLGame policies can more effectively incorporate guidance from the reference policy and account for noisily-rational human behaviors versus non-regularized baselines.
Hypergraph-Transformer (HGT) for Interactive Event Prediction in Laparoscopic and Robotic Surgery
Feb 03, 2024Understanding and anticipating intraoperative events and actions is critical for intraoperative assistance and decision-making during minimally invasive surgery. Automated prediction of events, actions, and the following consequences is addressed through various computational approaches with the objective of augmenting surgeons' perception and decision-making capabilities. We propose a predictive neural network that is capable of understanding and predicting critical interactive aspects of surgical workflow from intra-abdominal video, while flexibly leveraging surgical knowledge graphs. The approach incorporates a hypergraph-transformer (HGT) structure that encodes expert knowledge into the network design and predicts the hidden embedding of the graph. We verify our approach on established surgical datasets and applications, including the detection and prediction of action triplets, and the achievement of the Critical View of Safety (CVS). Moreover, we address specific, safety-related tasks, such as predicting the clipping of cystic duct or artery without prior achievement of the CVS. Our results demonstrate the superiority of our approach compared to unstructured alternatives.
Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Models
Oct 26, 2023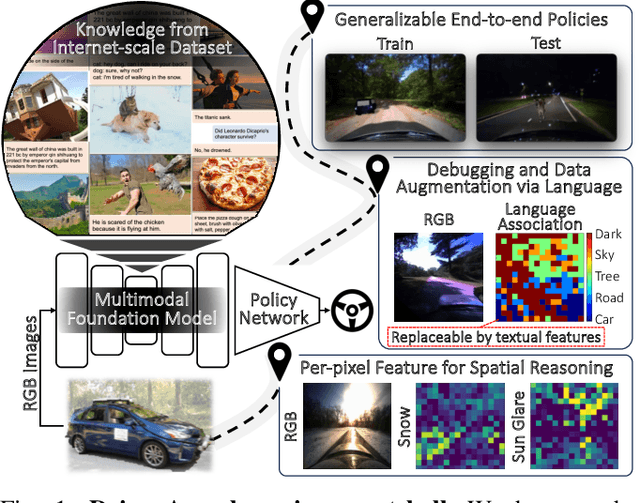
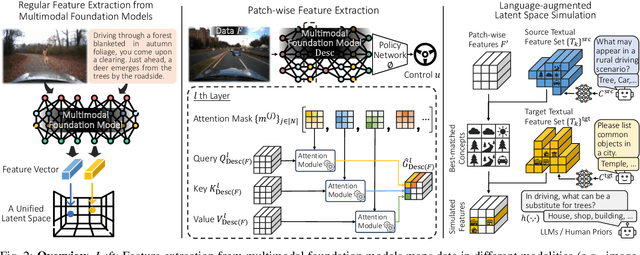
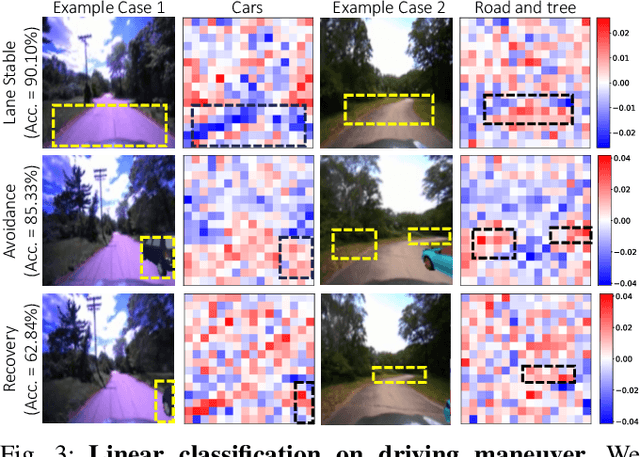
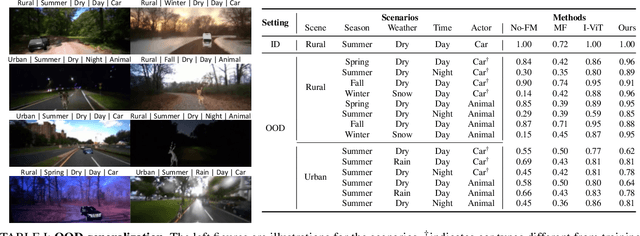
As autonomous driving technology matures, end-to-end methodologies have emerged as a leading strategy, promising seamless integration from perception to control via deep learning. However, existing systems grapple with challenges such as unexpected open set environments and the complexity of black-box models. At the same time, the evolution of deep learning introduces larger, multimodal foundational models, offering multi-modal visual and textual understanding. In this paper, we harness these multimodal foundation models to enhance the robustness and adaptability of autonomous driving systems, enabling out-of-distribution, end-to-end, multimodal, and more explainable autonomy. Specifically, we present an approach to apply end-to-end open-set (any environment/scene) autonomous driving that is capable of providing driving decisions from representations queryable by image and text. To do so, we introduce a method to extract nuanced spatial (pixel/patch-aligned) features from transformers to enable the encapsulation of both spatial and semantic features. Our approach (i) demonstrates unparalleled results in diverse tests while achieving significantly greater robustness in out-of-distribution situations, and (ii) allows the incorporation of latent space simulation (via text) for improved training (data augmentation via text) and policy debugging. We encourage the reader to check our explainer video at https://www.youtube.com/watch?v=4n-DJf8vXxo&feature=youtu.be and to view the code and demos on our project webpage at https://drive-anywhere.github.io/.
GAME-UP: Game-Aware Mode Enumeration and Understanding for Trajectory Prediction
May 28, 2023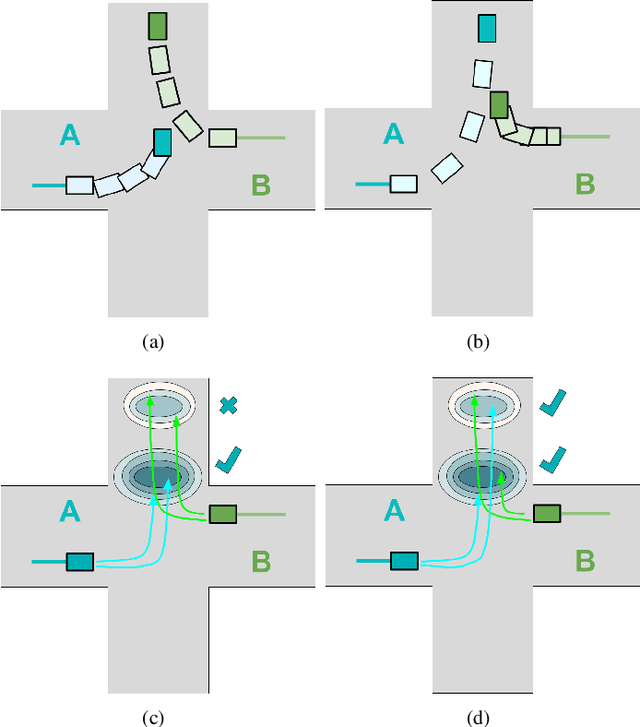
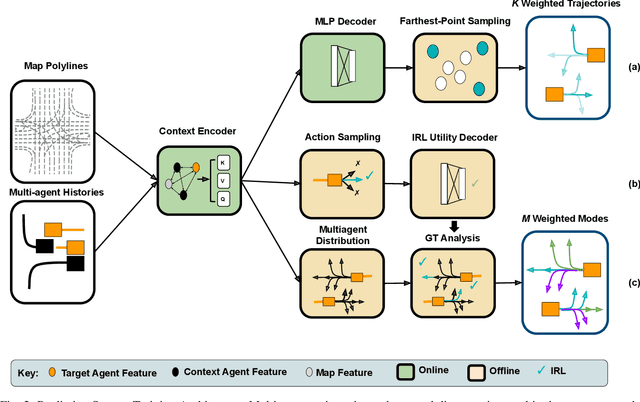
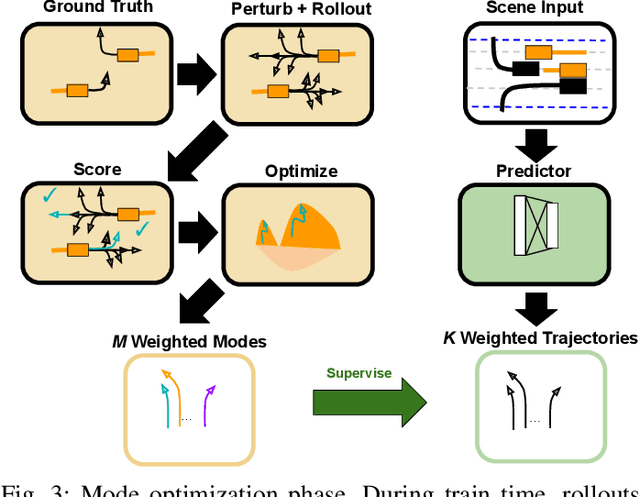
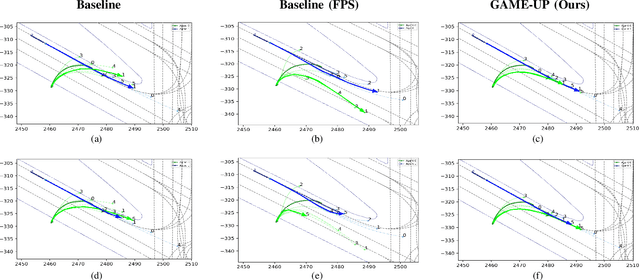
Interactions between road agents present a significant challenge in trajectory prediction, especially in cases involving multiple agents. Because existing diversity-aware predictors do not account for the interactive nature of multi-agent predictions, they may miss these important interaction outcomes. In this paper, we propose GAME-UP, a framework for trajectory prediction that leverages game-theoretic inverse reinforcement learning to improve coverage of multi-modal predictions. We use a training-time game-theoretic numerical analysis as an auxiliary loss resulting in improved coverage and accuracy without presuming a taxonomy of actions for the agents. We demonstrate our approach on the interactive subset of Waymo Open Motion Dataset, including three subsets involving scenarios with high interaction complexity. Experiment results show that our predictor produces accurate predictions while covering twice as many possible interactions versus a baseline model.
Multi-Abstractive Neural Controller: An Efficient Hierarchical Control Architecture for Interactive Driving
May 24, 2023
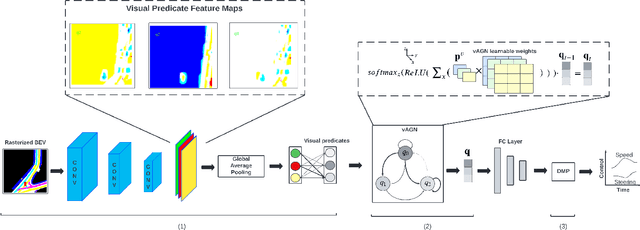
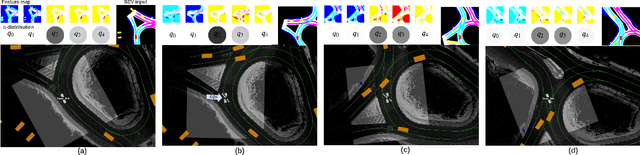
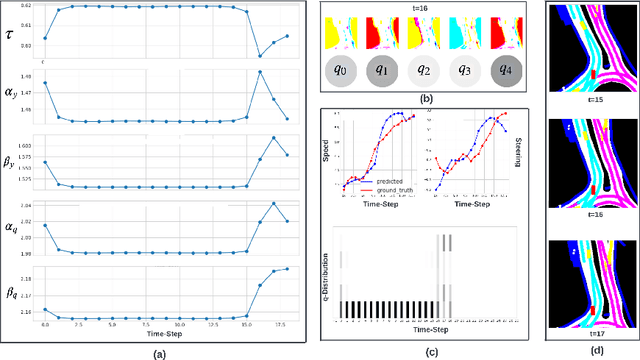
As learning-based methods make their way from perception systems to planning/control stacks, robot control systems have started to enjoy the benefits that data-driven methods provide. Because control systems directly affect the motion of the robot, data-driven methods, especially black box approaches, need to be used with caution considering aspects such as stability and interpretability. In this paper, we describe a differentiable and hierarchical control architecture. The proposed representation, called \textit{multi-abstractive neural controller}, uses the input image to control the transitions within a novel discrete behavior planner (referred to as the visual automaton generative network, or \textit{vAGN}). The output of a vAGN controls the parameters of a set of dynamic movement primitives which provides the system controls. We train this neural controller with real-world driving data via behavior cloning and show improved explainability, sample efficiency, and similarity to human driving.
Specification-Guided Data Aggregation for Semantically Aware Imitation Learning
Mar 29, 2023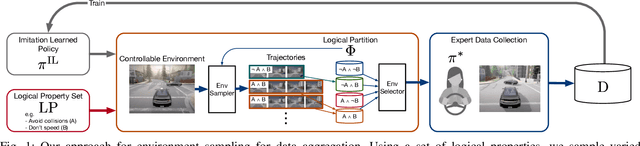
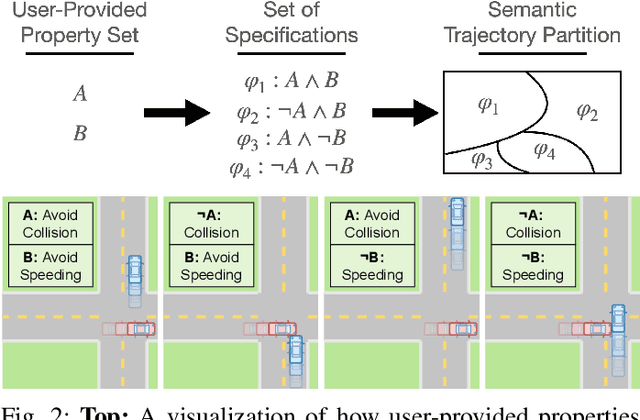
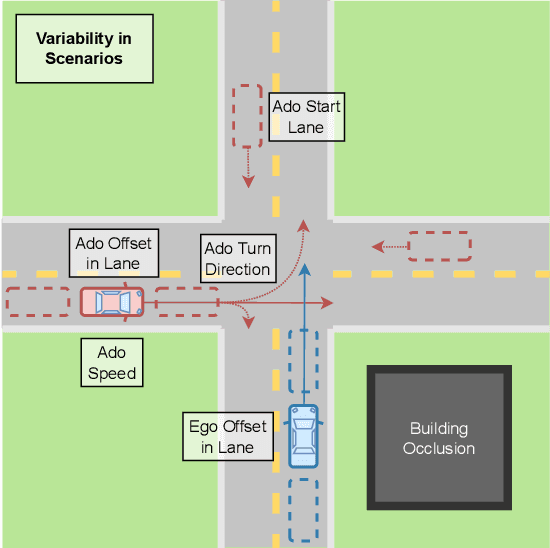
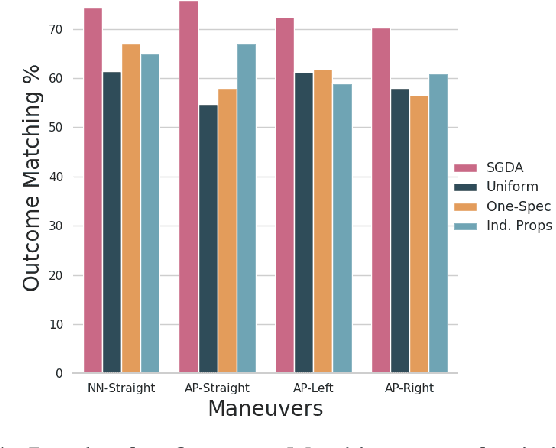
Advancements in simulation and formal methods-guided environment sampling have enabled the rigorous evaluation of machine learning models in a number of safety-critical scenarios, such as autonomous driving. Application of these environment sampling techniques towards improving the learned models themselves has yet to be fully exploited. In this work, we introduce a novel method for improving imitation-learned models in a semantically aware fashion by leveraging specification-guided sampling techniques as a means of aggregating expert data in new environments. Specifically, we create a set of formal specifications as a means of partitioning the space of possible environments into semantically similar regions, and identify elements of this partition where our learned imitation behaves most differently from the expert. We then aggregate expert data on environments in these identified regions, leading to more accurate imitation of the expert's behavior semantics. We instantiate our approach in a series of experiments in the CARLA driving simulator, and demonstrate that our approach leads to models that are more accurate than those learned with other environment sampling methods.
MPOGames: Efficient Multimodal Partially Observable Dynamic Games
Oct 19, 2022
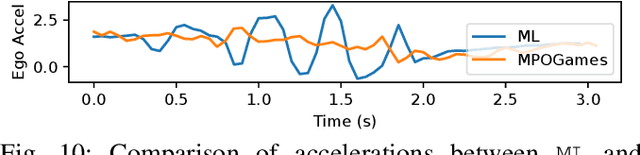

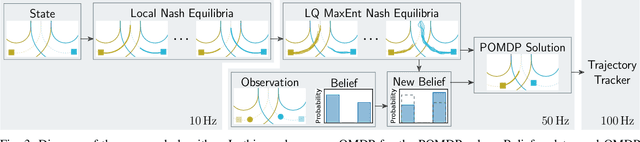
Game theoretic methods have become popular for planning and prediction in situations involving rich multi-agent interactions. However, these methods often assume the existence of a single local Nash equilibria and are hence unable to handle uncertainty in the intentions of different agents. While maximum entropy (MaxEnt) dynamic games try to address this issue, practical approaches solve for MaxEnt Nash equilibria using linear-quadratic approximations which are restricted to unimodal responses and unsuitable for scenarios with multiple local Nash equilibria. By reformulating the problem as a POMDP, we propose MPOGames, a method for efficiently solving MaxEnt dynamic games that captures the interactions between local Nash equilibria. We show the importance of uncertainty-aware game theoretic methods via a two-agent merge case study. Finally, we prove the real-time capabilities of our approach with hardware experiments on a 1/10th scale car platform.
Leveraging Smooth Attention Prior for Multi-Agent Trajectory Prediction
Mar 19, 2022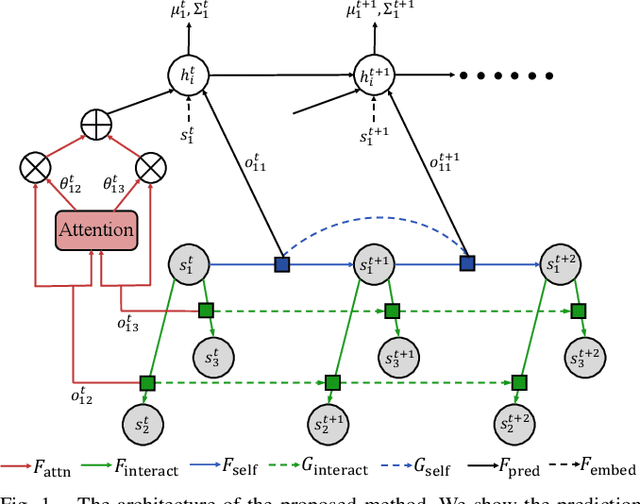
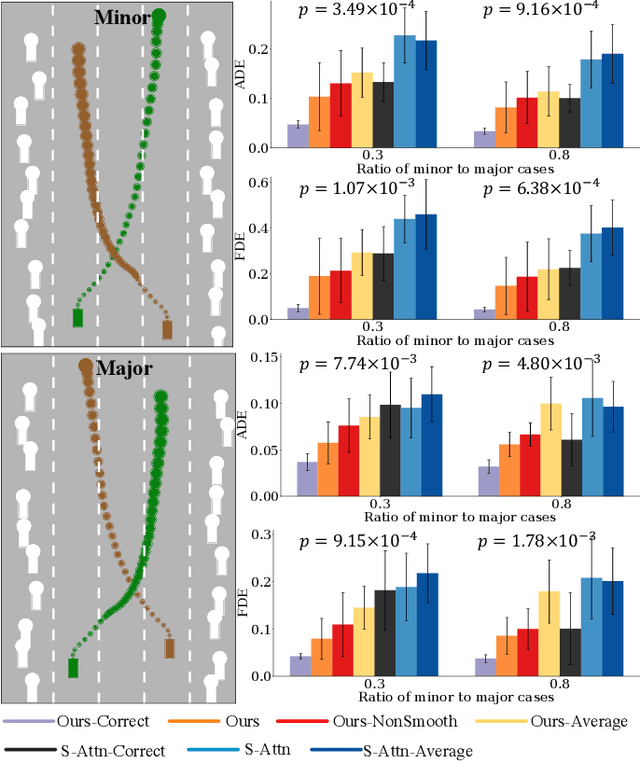
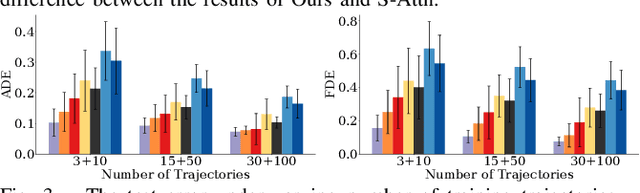
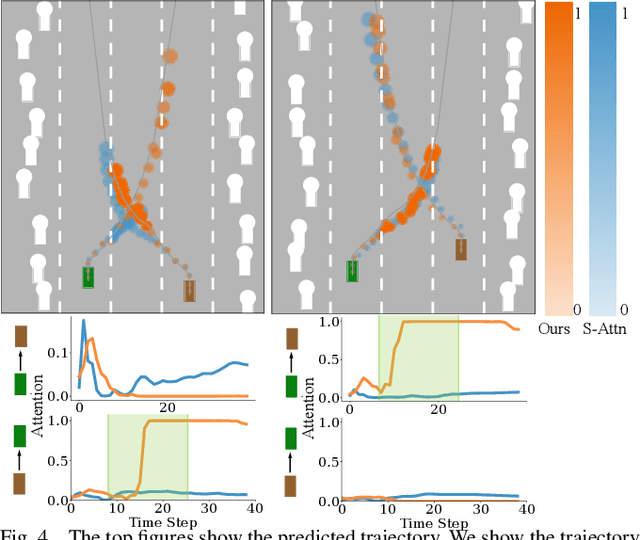
Multi-agent interactions are important to model for forecasting other agents' behaviors and trajectories. At a certain time, to forecast a reasonable future trajectory, each agent needs to pay attention to the interactions with only a small group of most relevant agents instead of unnecessarily paying attention to all the other agents. However, existing attention modeling works ignore that human attention in driving does not change rapidly, and may introduce fluctuating attention across time steps. In this paper, we formulate an attention model for multi-agent interactions based on a total variation temporal smoothness prior and propose a trajectory prediction architecture that leverages the knowledge of these attended interactions. We demonstrate how the total variation attention prior along with the new sequence prediction loss terms leads to smoother attention and more sample-efficient learning of multi-agent trajectory prediction, and show its advantages in terms of prediction accuracy by comparing it with the state-of-the-art approaches on both synthetic and naturalistic driving data. We demonstrate the performance of our algorithm for trajectory prediction on the INTERACTION dataset on our website.
* 8 pages
Concept Graph Neural Networks for Surgical Video Understanding
Feb 27, 2022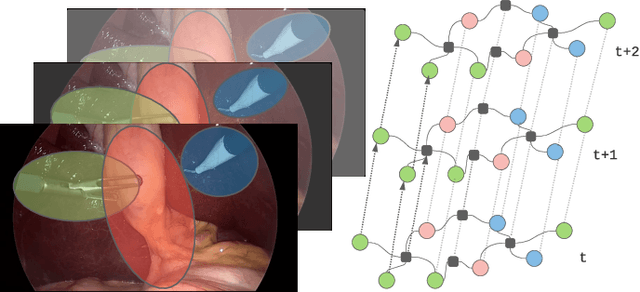
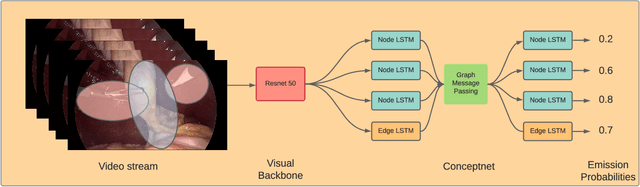
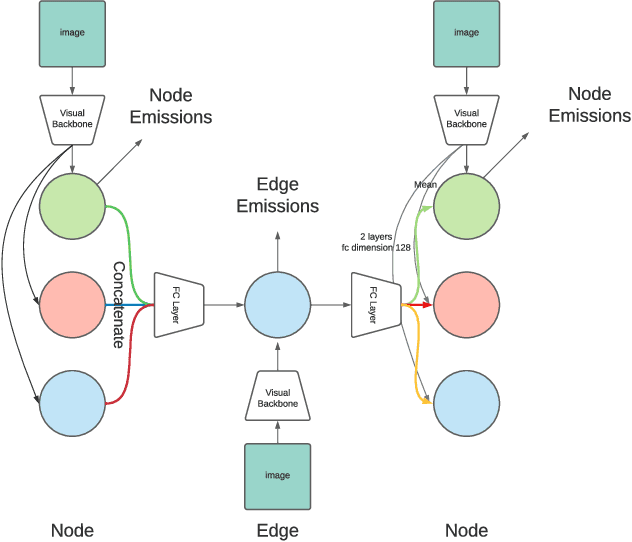
We constantly integrate our knowledge and understanding of the world to enhance our interpretation of what we see. This ability is crucial in application domains which entail reasoning about multiple entities and concepts, such as AI-augmented surgery. In this paper, we propose a novel way of integrating conceptual knowledge into temporal analysis tasks via temporal concept graph networks. In the proposed networks, a global knowledge graph is incorporated into the temporal analysis of surgical instances, learning the meaning of concepts and relations as they apply to the data. We demonstrate our results in surgical video data for tasks such as verification of critical view of safety, as well as estimation of Parkland grading scale. The results show that our method improves the recognition and detection of complex benchmarks as well as enables other analytic applications of interest.
Trajectory Prediction with Linguistic Representations
Oct 19, 2021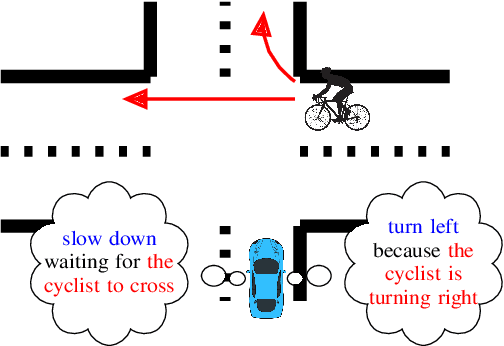
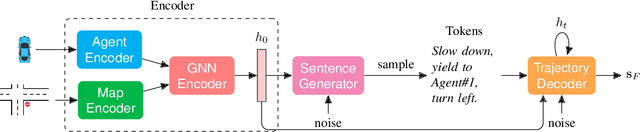
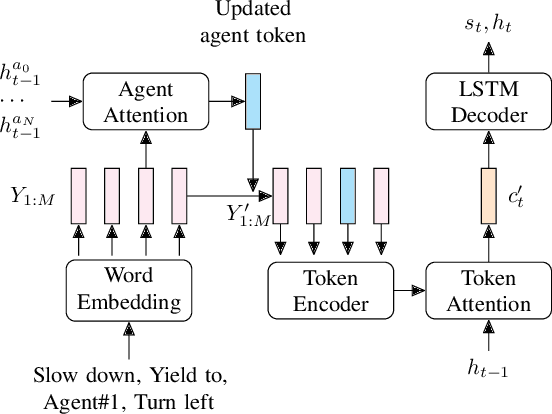

Language allows humans to build mental models that interpret what is happening around them resulting in more accurate long-term predictions. We present a novel trajectory prediction model that uses linguistic intermediate representations to forecast trajectories, and is trained using trajectory samples with partially annotated captions. The model learns the meaning of each of the words without direct per-word supervision. At inference time, it generates a linguistic description of trajectories which captures maneuvers and interactions over an extended time interval. This generated description is used to refine predictions of the trajectories of multiple agents. We train and validate our model on the Argoverse dataset, and demonstrate improved accuracy results in trajectory prediction. In addition, our model is more interpretable: it presents part of its reasoning in plain language as captions, which can aid model development and can aid in building confidence in the model before deploying it.