 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYen-Ling Kuo
A Transformer-Based Model for the Prediction of Human Gaze Behavior on Videos
Apr 10, 2024
Eye-tracking applications that utilize the human gaze in video understanding tasks have become increasingly important. To effectively automate the process of video analysis based on eye-tracking data, it is important to accurately replicate human gaze behavior. However, this task presents significant challenges due to the inherent complexity and ambiguity of human gaze patterns. In this work, we introduce a novel method for simulating human gaze behavior. Our approach uses a transformer-based reinforcement learning algorithm to train an agent that acts as a human observer, with the primary role of watching videos and simulating human gaze behavior. We employed an eye-tracking dataset gathered from videos generated by the VirtualHome simulator, with a primary focus on activity recognition. Our experimental results demonstrate the effectiveness of our gaze prediction method by highlighting its capability to replicate human gaze behavior and its applicability for downstream tasks where real human-gaze is used as input.
Gaze-Guided Graph Neural Network for Action Anticipation Conditioned on Intention
Apr 10, 2024Humans utilize their gaze to concentrate on essential information while perceiving and interpreting intentions in videos. Incorporating human gaze into computational algorithms can significantly enhance model performance in video understanding tasks. In this work, we address a challenging and innovative task in video understanding: predicting the actions of an agent in a video based on a partial video. We introduce the Gaze-guided Action Anticipation algorithm, which establishes a visual-semantic graph from the video input. Our method utilizes a Graph Neural Network to recognize the agent's intention and predict the action sequence to fulfill this intention. To assess the efficiency of our approach, we collect a dataset containing household activities generated in the VirtualHome environment, accompanied by human gaze data of viewing videos. Our method outperforms state-of-the-art techniques, achieving a 7\% improvement in accuracy for 18-class intention recognition. This highlights the efficiency of our method in learning important features from human gaze data.
MMToM-QA: Multimodal Theory of Mind Question Answering
Jan 16, 2024Theory of Mind (ToM), the ability to understand people's minds, is an essential ingredient for developing machines with human-level social intelligence. Recent machine learning models, particularly large language models, seem to show some aspects of ToM understanding. However, existing ToM benchmarks use unimodal datasets - either video or text. Human ToM, on the other hand, is more than video or text understanding. People can flexibly reason about another person's mind based on conceptual representations (e.g., goals, beliefs, plans) extracted from any available data, which can include visual cues, linguistic narratives, or both. To address this, we introduce a multimodal Theory of Mind question answering (MMToM-QA) benchmark. MMToM-QA comprehensively evaluates machine ToM both on multimodal data and on different kinds of unimodal data about a person's activity in a household environment. To engineer multimodal ToM capacity, we propose a novel method, BIP-ALM (Bayesian Inverse Planning Accelerated by Language Models). BIP-ALM extracts unified representations from multimodal data and utilizes language models for scalable Bayesian inverse planning. We conducted a systematic comparison of human performance, BIP-ALM, and state-of-the-art models, including GPT-4. The experiments demonstrate that large language models and large multimodal models still lack robust ToM capacity. BIP-ALM, on the other hand, shows promising results, by leveraging the power of both model-based mental inference and language models.
Neural Amortized Inference for Nested Multi-agent Reasoning
Aug 21, 2023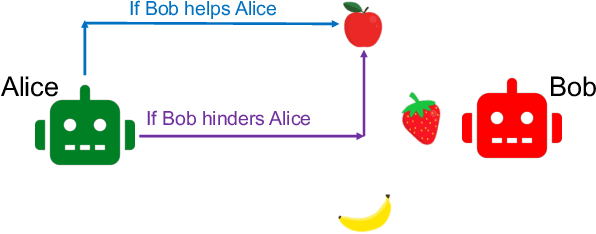


Multi-agent interactions, such as communication, teaching, and bluffing, often rely on higher-order social inference, i.e., understanding how others infer oneself. Such intricate reasoning can be effectively modeled through nested multi-agent reasoning. Nonetheless, the computational complexity escalates exponentially with each level of reasoning, posing a significant challenge. However, humans effortlessly perform complex social inferences as part of their daily lives. To bridge the gap between human-like inference capabilities and computational limitations, we propose a novel approach: leveraging neural networks to amortize high-order social inference, thereby expediting nested multi-agent reasoning. We evaluate our method in two challenging multi-agent interaction domains. The experimental results demonstrate that our method is computationally efficient while exhibiting minimal degradation in accuracy.
GAME-UP: Game-Aware Mode Enumeration and Understanding for Trajectory Prediction
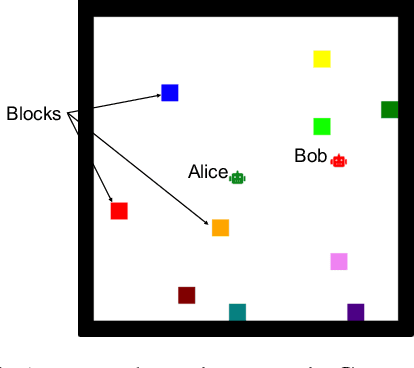
May 28, 2023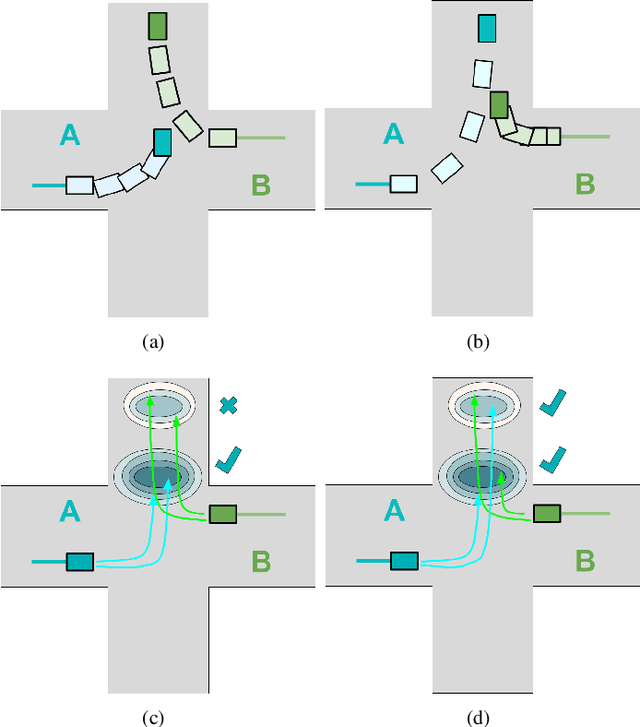
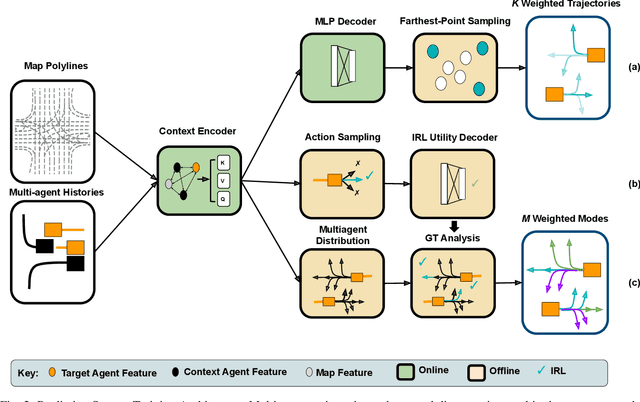
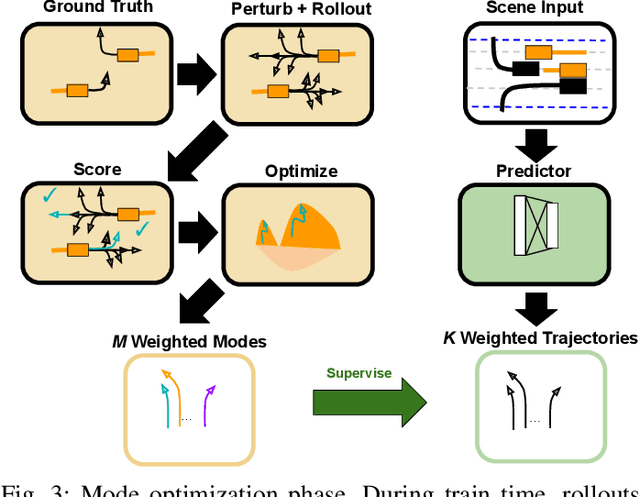
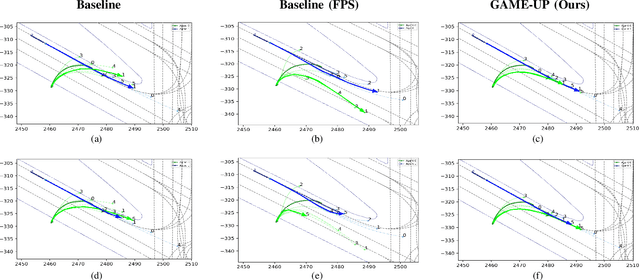
Interactions between road agents present a significant challenge in trajectory prediction, especially in cases involving multiple agents. Because existing diversity-aware predictors do not account for the interactive nature of multi-agent predictions, they may miss these important interaction outcomes. In this paper, we propose GAME-UP, a framework for trajectory prediction that leverages game-theoretic inverse reinforcement learning to improve coverage of multi-modal predictions. We use a training-time game-theoretic numerical analysis as an auxiliary loss resulting in improved coverage and accuracy without presuming a taxonomy of actions for the agents. We demonstrate our approach on the interactive subset of Waymo Open Motion Dataset, including three subsets involving scenarios with high interaction complexity. Experiment results show that our predictor produces accurate predictions while covering twice as many possible interactions versus a baseline model.
Summarize the Past to Predict the Future: Natural Language Descriptions of Context Boost Multimodal Object Interaction
Jan 22, 2023



We study the task of object interaction anticipation in egocentric videos. Successful prediction of future actions and objects requires an understanding of the spatio-temporal context formed by past actions and object relationships. We propose TransFusion, a multimodal transformer-based architecture, that effectively makes use of the representational power of language by summarizing past actions concisely. TransFusion leverages pre-trained image captioning models and summarizes the caption, focusing on past actions and objects. This action context together with a single input frame is processed by a multimodal fusion module to forecast the next object interactions. Our model enables more efficient end-to-end learning by replacing dense video features with language representations, allowing us to benefit from knowledge encoded in large pre-trained models. Experiments on Ego4D and EPIC-KITCHENS-100 show the effectiveness of our multimodal fusion model and the benefits of using language-based context summaries. Our method outperforms state-of-the-art approaches by 40.4% in overall mAP on the Ego4D test set. We show the generality of TransFusion via experiments on EPIC-KITCHENS-100. Video and code are available at: https://eth-ait.github.io/transfusion-proj/.
Reconstructing Action-Conditioned Human-Object Interactions Using Commonsense Knowledge Priors
Sep 06, 2022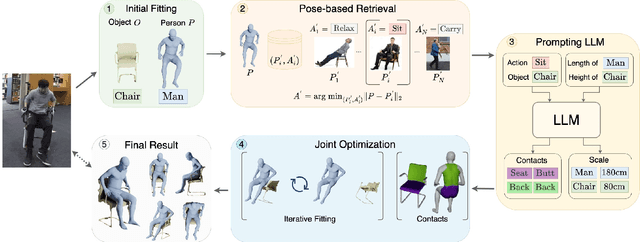
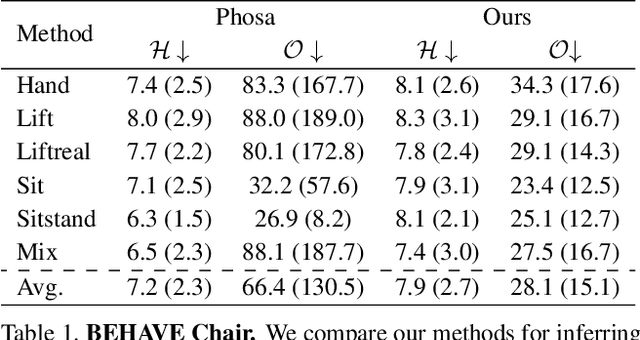
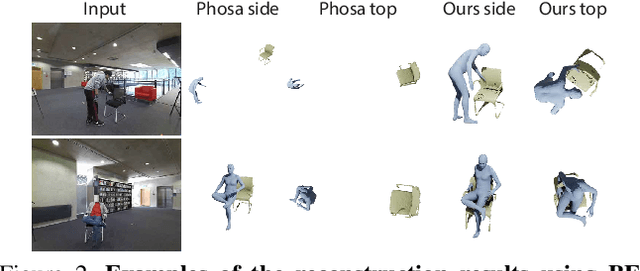
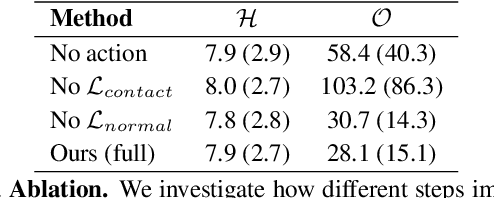
We present a method for inferring diverse 3D models of human-object interactions from images. Reasoning about how humans interact with objects in complex scenes from a single 2D image is a challenging task given ambiguities arising from the loss of information through projection. In addition, modeling 3D interactions requires the generalization ability towards diverse object categories and interaction types. We propose an action-conditioned modeling of interactions that allows us to infer diverse 3D arrangements of humans and objects without supervision on contact regions or 3D scene geometry. Our method extracts high-level commonsense knowledge from large language models (such as GPT-3), and applies them to perform 3D reasoning of human-object interactions. Our key insight is priors extracted from large language models can help in reasoning about human-object contacts from textural prompts only. We quantitatively evaluate the inferred 3D models on a large human-object interaction dataset and show how our method leads to better 3D reconstructions. We further qualitatively evaluate the effectiveness of our method on real images and demonstrate its generalizability towards interaction types and object categories.
Incorporating Rich Social Interactions Into MDPs
Oct 22, 2021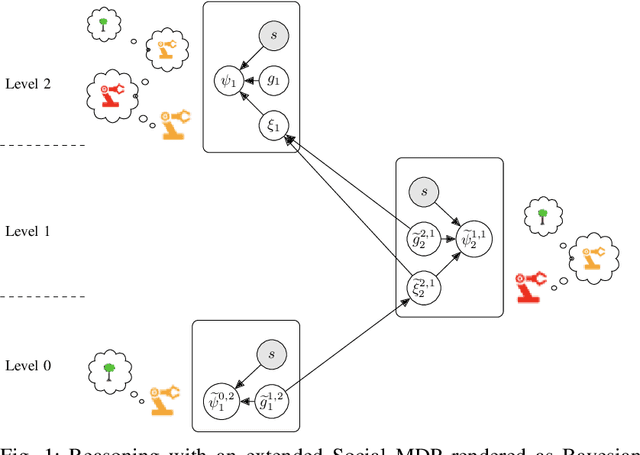
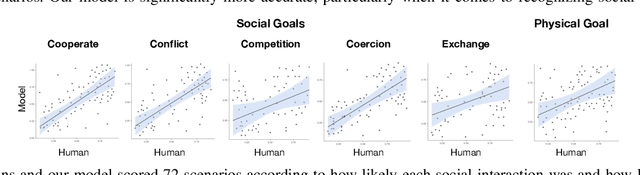
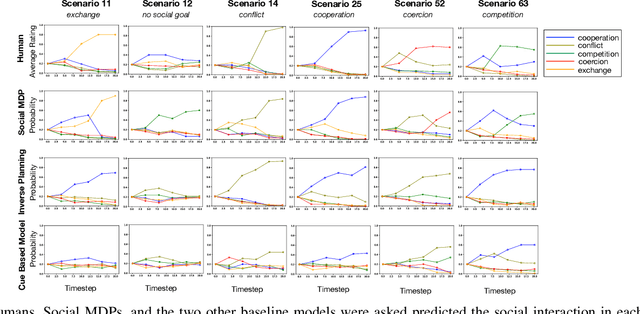

Much of what we do as humans is engage socially with other agents, a skill that robots must also eventually possess. We demonstrate that a rich theory of social interactions originating from microsociology and economics can be formalized by extending a nested MDP where agents reason about arbitrary functions of each other's hidden rewards. This extended Social MDP allows us to encode the five basic interactions that underlie microsociology: cooperation, conflict, coercion, competition, and exchange. The result is a robotic agent capable of executing social interactions zero-shot in new environments; like humans it can engage socially in novel ways even without a single example of that social interaction. Moreover, the judgments of these Social MDPs align closely with those of humans when considering which social interaction is taking place in an environment. This method both sheds light on the nature of social interactions, by providing concrete mathematical definitions, and brings rich social interactions into a mathematical framework that has proven to be natural for robotics, MDPs.
Trajectory Prediction with Linguistic Representations
Oct 19, 2021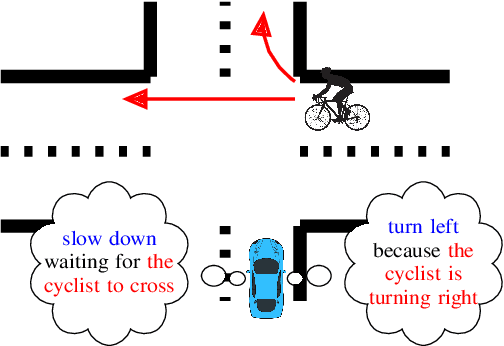
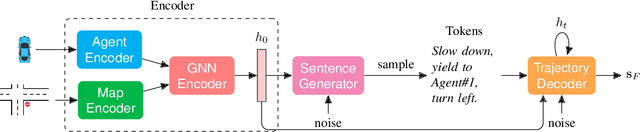
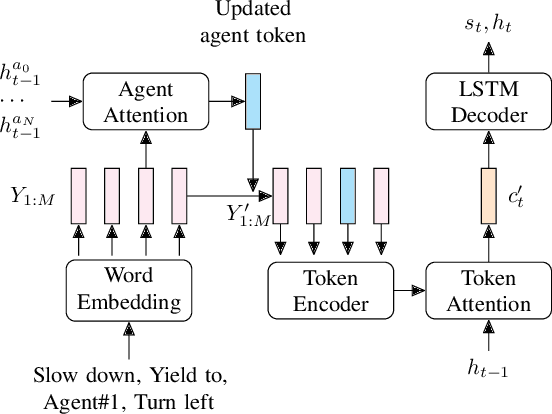

Language allows humans to build mental models that interpret what is happening around them resulting in more accurate long-term predictions. We present a novel trajectory prediction model that uses linguistic intermediate representations to forecast trajectories, and is trained using trajectory samples with partially annotated captions. The model learns the meaning of each of the words without direct per-word supervision. At inference time, it generates a linguistic description of trajectories which captures maneuvers and interactions over an extended time interval. This generated description is used to refine predictions of the trajectories of multiple agents. We train and validate our model on the Argoverse dataset, and demonstrate improved accuracy results in trajectory prediction. In addition, our model is more interpretable: it presents part of its reasoning in plain language as captions, which can aid model development and can aid in building confidence in the model before deploying it.
Learning a natural-language to LTL executable semantic parser for grounded robotics
Aug 11, 2020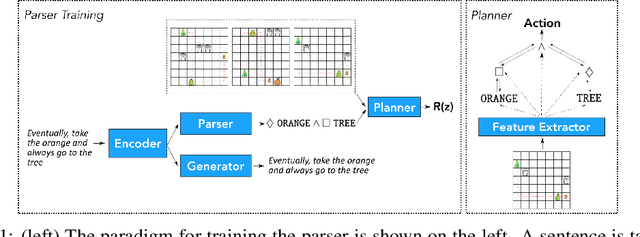
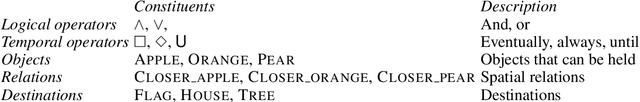
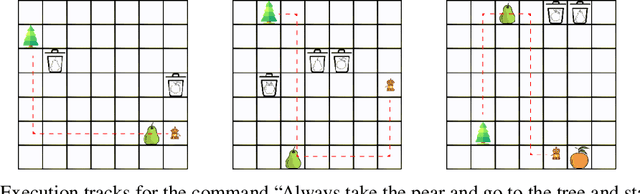
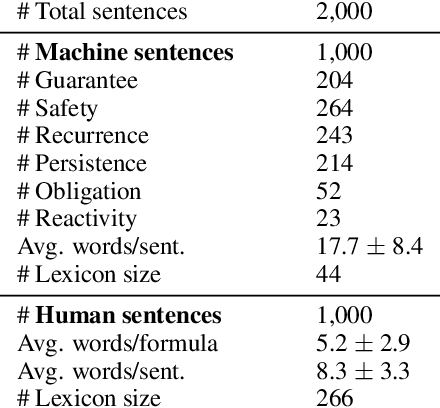
Children acquire their native language with apparent ease by observing how language is used in context and attempting to use it themselves. They do so without laborious annotations, negative examples, or even direct corrections. We take a step toward robots that can do the same by training a grounded semantic parser, which discovers latent linguistic representations that can be used for the execution of natural-language commands. In particular, we focus on the difficult domain of commands with a temporal aspect, whose semantics we capture with Linear Temporal Logic, LTL. Our parser is trained with pairs of sentences and executions as well as an executor. At training time, the parser hypothesizes a meaning representation for the input as a formula in LTL. Three competing pressures allow the parser to discover meaning from language. First, any hypothesized meaning for a sentence must be permissive enough to reflect all the annotated execution trajectories. Second, the executor -- a pretrained end-to-end LTL planner -- must find that the observed trajectories are likely executions of the meaning. Finally, a generator, which reconstructs the original input, encourages the model to find representations that conserve knowledge about the command. Together these ensure that the meaning is neither too general nor too specific. Our model generalizes well, being able to parse and execute both machine-generated and human-generated commands, with near-equal accuracy, despite the fact that the human-generated sentences are much more varied and complex with an open lexicon. The approach presented here is not specific to LTL; it can be applied to any domain where sentence meanings can be hypothesized and an executor can verify these meanings, thus opening the door to many applications for robotic agents.