 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYao Rong
Pre-training on High Definition X-ray Images: An Experimental Study
Apr 27, 2024
Existing X-ray based pre-trained vision models are usually conducted on a relatively small-scale dataset (less than 500k samples) with limited resolution (e.g., 224 $\times$ 224). However, the key to the success of self-supervised pre-training large models lies in massive training data, and maintaining high resolution in the field of X-ray images is the guarantee of effective solutions to difficult miscellaneous diseases. In this paper, we address these issues by proposing the first high-definition (1280 $\times$ 1280) X-ray based pre-trained foundation vision model on our newly collected large-scale dataset which contains more than 1 million X-ray images. Our model follows the masked auto-encoder framework which takes the tokens after mask processing (with a high rate) is used as input, and the masked image patches are reconstructed by the Transformer encoder-decoder network. More importantly, we introduce a novel context-aware masking strategy that utilizes the chest contour as a boundary for adaptive masking operations. We validate the effectiveness of our model on two downstream tasks, including X-ray report generation and disease recognition. Extensive experiments demonstrate that our pre-trained medical foundation vision model achieves comparable or even new state-of-the-art performance on downstream benchmark datasets. The source code and pre-trained models of this paper will be released on https://github.com/Event-AHU/Medical_Image_Analysis.
State Space Model for New-Generation Network Alternative to Transformers: A Survey
Apr 15, 2024In the post-deep learning era, the Transformer architecture has demonstrated its powerful performance across pre-trained big models and various downstream tasks. However, the enormous computational demands of this architecture have deterred many researchers. To further reduce the complexity of attention models, numerous efforts have been made to design more efficient methods. Among them, the State Space Model (SSM), as a possible replacement for the self-attention based Transformer model, has drawn more and more attention in recent years. In this paper, we give the first comprehensive review of these works and also provide experimental comparisons and analysis to better demonstrate the features and advantages of SSM. Specifically, we first give a detailed description of principles to help the readers quickly capture the key ideas of SSM. After that, we dive into the reviews of existing SSMs and their various applications, including natural language processing, computer vision, graph, multi-modal and multi-media, point cloud/event stream, time series data, and other domains. In addition, we give statistical comparisons and analysis of these models and hope it helps the readers to understand the effectiveness of different structures on various tasks. Then, we propose possible research points in this direction to better promote the development of the theoretical model and application of SSM. More related works will be continuously updated on the following GitHub: https://github.com/Event-AHU/Mamba_State_Space_Model_Paper_List.
Gaze-Guided Graph Neural Network for Action Anticipation Conditioned on Intention
Apr 10, 2024Humans utilize their gaze to concentrate on essential information while perceiving and interpreting intentions in videos. Incorporating human gaze into computational algorithms can significantly enhance model performance in video understanding tasks. In this work, we address a challenging and innovative task in video understanding: predicting the actions of an agent in a video based on a partial video. We introduce the Gaze-guided Action Anticipation algorithm, which establishes a visual-semantic graph from the video input. Our method utilizes a Graph Neural Network to recognize the agent's intention and predict the action sequence to fulfill this intention. To assess the efficiency of our approach, we collect a dataset containing household activities generated in the VirtualHome environment, accompanied by human gaze data of viewing videos. Our method outperforms state-of-the-art techniques, achieving a 7\% improvement in accuracy for 18-class intention recognition. This highlights the efficiency of our method in learning important features from human gaze data.
A Transformer-Based Model for the Prediction of Human Gaze Behavior on Videos
Apr 10, 2024Eye-tracking applications that utilize the human gaze in video understanding tasks have become increasingly important. To effectively automate the process of video analysis based on eye-tracking data, it is important to accurately replicate human gaze behavior. However, this task presents significant challenges due to the inherent complexity and ambiguity of human gaze patterns. In this work, we introduce a novel method for simulating human gaze behavior. Our approach uses a transformer-based reinforcement learning algorithm to train an agent that acts as a human observer, with the primary role of watching videos and simulating human gaze behavior. We employed an eye-tracking dataset gathered from videos generated by the VirtualHome simulator, with a primary focus on activity recognition. Our experimental results demonstrate the effectiveness of our gaze prediction method by highlighting its capability to replicate human gaze behavior and its applicability for downstream tasks where real human-gaze is used as input.
Stepwise Self-Consistent Mathematical Reasoning with Large Language Models
Feb 24, 2024Using Large Language Models for complex mathematical reasoning is difficult, primarily due to the complexity of multi-step reasoning. The main challenges of this process include (1) selecting critical intermediate results to advance the procedure, and (2) limited exploration of potential solutions. To address these issues, we introduce a novel algorithm, namely Stepwise Self-Consistent Chain-of-Thought (SSC-CoT). SSC-CoT employs a strategy of selecting intermediate steps based on the intersection of various reasoning chains. Additionally, SSC-CoT enables the model to discover critical intermediate steps by querying a knowledge graph comprising relevant domain knowledge. To validate SSC-CoT, we present a new dataset, TriMaster100, tailored for complex trigonometry problems. This dataset contains 100 questions, with each solution broken down into scored intermediate steps, facilitating a comprehensive evaluation of the mathematical reasoning process. On TriMaster100, SSC-CoT triples the effectiveness of the state-of-the-art methods. Furthermore, we benchmark SSC-CoT on the widely recognized complex mathematical question dataset, MATH level 5, and it surpasses the second-best method by 7.2% in accuracy. Code and the TriMaster100 dataset can be found at: https://github.com/zhao-zilong/ssc-cot.
I-CEE: Tailoring Explanations of Image Classifications Models to User Expertise
Dec 19, 2023Effectively explaining decisions of black-box machine learning models is critical to responsible deployment of AI systems that rely on them. Recognizing their importance, the field of explainable AI (XAI) provides several techniques to generate these explanations. Yet, there is relatively little emphasis on the user (the explainee) in this growing body of work and most XAI techniques generate "one-size-fits-all" explanations. To bridge this gap and achieve a step closer towards human-centered XAI, we present I-CEE, a framework that provides Image Classification Explanations tailored to User Expertise. Informed by existing work, I-CEE explains the decisions of image classification models by providing the user with an informative subset of training data (i.e., example images), corresponding local explanations, and model decisions. However, unlike prior work, I-CEE models the informativeness of the example images to depend on user expertise, resulting in different examples for different users. We posit that by tailoring the example set to user expertise, I-CEE can better facilitate users' understanding and simulatability of the model. To evaluate our approach, we conduct detailed experiments in both simulation and with human participants (N = 100) on multiple datasets. Experiments with simulated users show that I-CEE improves users' ability to accurately predict the model's decisions (simulatability) compared to baselines, providing promising preliminary results. Experiments with human participants demonstrate that our method significantly improves user simulatability accuracy, highlighting the importance of human-centered XAI
Unleashing the Power of CNN and Transformer for Balanced RGB-Event Video Recognition
Dec 18, 2023Pattern recognition based on RGB-Event data is a newly arising research topic and previous works usually learn their features using CNN or Transformer. As we know, CNN captures the local features well and the cascaded self-attention mechanisms are good at extracting the long-range global relations. It is intuitive to combine them for high-performance RGB-Event based video recognition, however, existing works fail to achieve a good balance between the accuracy and model parameters, as shown in Fig.~\ref{firstimage}. In this work, we propose a novel RGB-Event based recognition framework termed TSCFormer, which is a relatively lightweight CNN-Transformer model. Specifically, we mainly adopt the CNN as the backbone network to first encode both RGB and Event data. Meanwhile, we initialize global tokens as the input and fuse them with RGB and Event features using the BridgeFormer module. It captures the global long-range relations well between both modalities and maintains the simplicity of the whole model architecture at the same time. The enhanced features will be projected and fused into the RGB and Event CNN blocks, respectively, in an interactive manner using F2E and F2V modules. Similar operations are conducted for other CNN blocks to achieve adaptive fusion and local-global feature enhancement under different resolutions. Finally, we concatenate these three features and feed them into the classification head for pattern recognition. Extensive experiments on two large-scale RGB-Event benchmark datasets (PokerEvent and HARDVS) fully validated the effectiveness of our proposed TSCFormer. The source code and pre-trained models will be released at https://github.com/Event-AHU/TSCFormer.
SSTFormer: Bridging Spiking Neural Network and Memory Support Transformer for Frame-Event based Recognition
Aug 08, 2023



Event camera-based pattern recognition is a newly arising research topic in recent years. Current researchers usually transform the event streams into images, graphs, or voxels, and adopt deep neural networks for event-based classification. Although good performance can be achieved on simple event recognition datasets, however, their results may be still limited due to the following two issues. Firstly, they adopt spatial sparse event streams for recognition only, which may fail to capture the color and detailed texture information well. Secondly, they adopt either Spiking Neural Networks (SNN) for energy-efficient recognition with suboptimal results, or Artificial Neural Networks (ANN) for energy-intensive, high-performance recognition. However, seldom of them consider achieving a balance between these two aspects. In this paper, we formally propose to recognize patterns by fusing RGB frames and event streams simultaneously and propose a new RGB frame-event recognition framework to address the aforementioned issues. The proposed method contains four main modules, i.e., memory support Transformer network for RGB frame encoding, spiking neural network for raw event stream encoding, multi-modal bottleneck fusion module for RGB-Event feature aggregation, and prediction head. Due to the scarce of RGB-Event based classification dataset, we also propose a large-scale PokerEvent dataset which contains 114 classes, and 27102 frame-event pairs recorded using a DVS346 event camera. Extensive experiments on two RGB-Event based classification datasets fully validated the effectiveness of our proposed framework. We hope this work will boost the development of pattern recognition by fusing RGB frames and event streams. Both our dataset and source code of this work will be released at https://github.com/Event-AHU/SSTFormer.
Efficient GNN Explanation via Learning Removal-based Attribution
Jun 09, 2023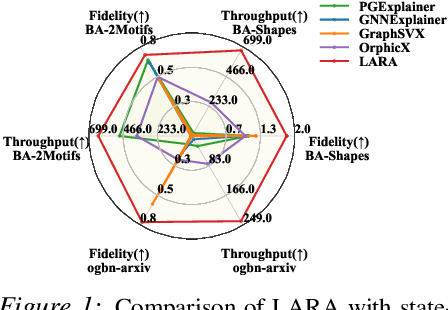

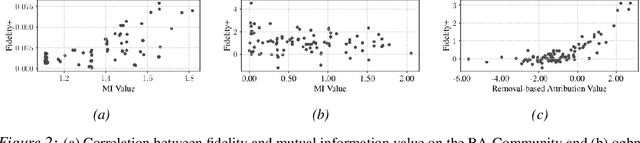
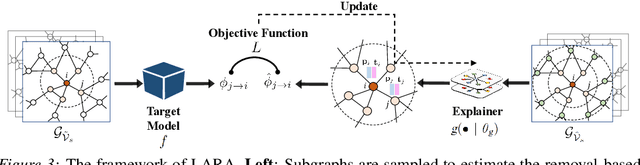
As Graph Neural Networks (GNNs) have been widely used in real-world applications, model explanations are required not only by users but also by legal regulations. However, simultaneously achieving high fidelity and low computational costs in generating explanations has been a challenge for current methods. In this work, we propose a framework of GNN explanation named LeArn Removal-based Attribution (LARA) to address this problem. Specifically, we introduce removal-based attribution and demonstrate its substantiated link to interpretability fidelity theoretically and experimentally. The explainer in LARA learns to generate removal-based attribution which enables providing explanations with high fidelity. A strategy of subgraph sampling is designed in LARA to improve the scalability of the training process. In the deployment, LARA can efficiently generate the explanation through a feed-forward pass. We benchmark our approach with other state-of-the-art GNN explanation methods on six datasets. Results highlight the effectiveness of our framework regarding both efficiency and fidelity. In particular, LARA is 3.5 times faster and achieves higher fidelity than the state-of-the-art method on the large dataset ogbn-arxiv (more than 160K nodes and 1M edges), showing its great potential in real-world applications. Our source code is available at https://anonymous.4open.science/r/LARA-10D8/README.md.
DynStatF: An Efficient Feature Fusion Strategy for LiDAR 3D Object Detection
May 24, 2023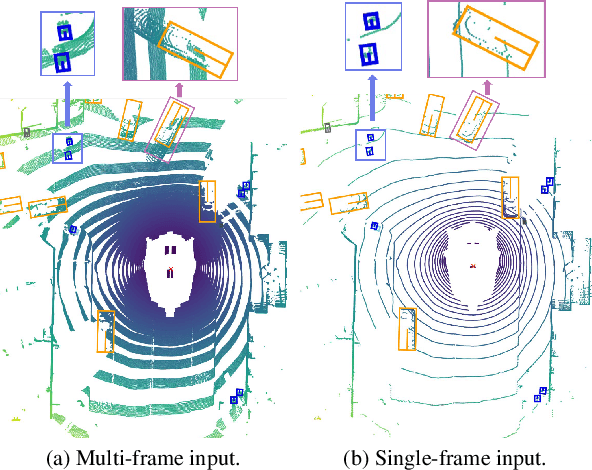
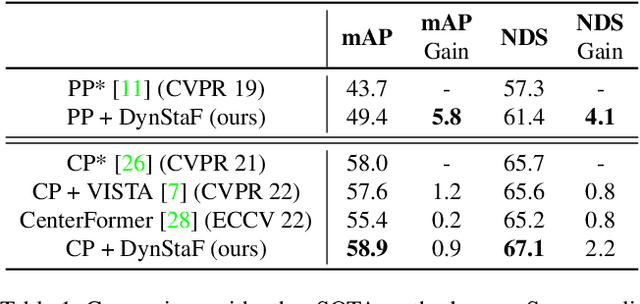
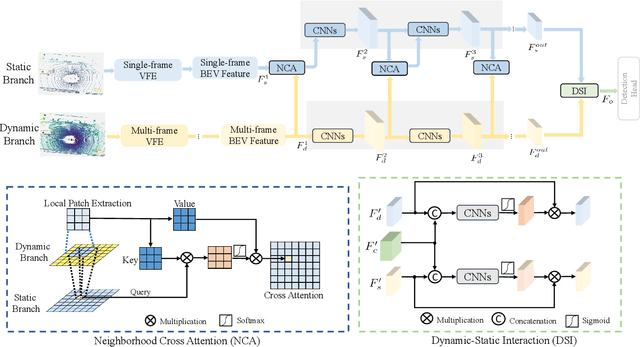

Augmenting LiDAR input with multiple previous frames provides richer semantic information and thus boosts performance in 3D object detection, However, crowded point clouds in multi-frames can hurt the precise position information due to the motion blur and inaccurate point projection. In this work, we propose a novel feature fusion strategy, DynStaF (Dynamic-Static Fusion), which enhances the rich semantic information provided by the multi-frame (dynamic branch) with the accurate location information from the current single-frame (static branch). To effectively extract and aggregate complimentary features, DynStaF contains two modules, Neighborhood Cross Attention (NCA) and Dynamic-Static Interaction (DSI), operating through a dual pathway architecture. NCA takes the features in the static branch as queries and the features in the dynamic branch as keys (values). When computing the attention, we address the sparsity of point clouds and take only neighborhood positions into consideration. NCA fuses two features at different feature map scales, followed by DSI providing the comprehensive interaction. To analyze our proposed strategy DynStaF, we conduct extensive experiments on the nuScenes dataset. On the test set, DynStaF increases the performance of PointPillars in NDS by a large margin from 57.7% to 61.6%. When combined with CenterPoint, our framework achieves 61.0% mAP and 67.7% NDS, leading to state-of-the-art performance without bells and whistles.