 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVyacheslav Kungurtsev
Group Distributionally Robust Dataset Distillation with Risk Minimization
Feb 07, 2024
Dataset distillation (DD) has emerged as a widely adopted technique for crafting a synthetic dataset that captures the essential information of a training dataset, facilitating the training of accurate neural models. Its applications span various domains, including transfer learning, federated learning, and neural architecture search. The most popular methods for constructing the synthetic data rely on matching the convergence properties of training the model with the synthetic dataset and the training dataset. However, targeting the training dataset must be thought of as auxiliary in the same sense that the training set is an approximate substitute for the population distribution, and the latter is the data of interest. Yet despite its popularity, an aspect that remains unexplored is the relationship of DD to its generalization, particularly across uncommon subgroups. That is, how can we ensure that a model trained on the synthetic dataset performs well when faced with samples from regions with low population density? Here, the representativeness and coverage of the dataset become salient over the guaranteed training error at inference. Drawing inspiration from distributionally robust optimization, we introduce an algorithm that combines clustering with the minimization of a risk measure on the loss to conduct DD. We provide a theoretical rationale for our approach and demonstrate its effective generalization and robustness across subgroups through numerical experiments.
Unlocking the Potential of Federated Learning: The Symphony of Dataset Distillation via Deep Generative Latents
Dec 03, 2023Data heterogeneity presents significant challenges for federated learning (FL). Recently, dataset distillation techniques have been introduced, and performed at the client level, to attempt to mitigate some of these challenges. In this paper, we propose a highly efficient FL dataset distillation framework on the server side, significantly reducing both the computational and communication demands on local devices while enhancing the clients' privacy. Unlike previous strategies that perform dataset distillation on local devices and upload synthetic data to the server, our technique enables the server to leverage prior knowledge from pre-trained deep generative models to synthesize essential data representations from a heterogeneous model architecture. This process allows local devices to train smaller surrogate models while enabling the training of a larger global model on the server, effectively minimizing resource utilization. We substantiate our claim with a theoretical analysis, demonstrating the asymptotic resemblance of the process to the hypothetical ideal of completely centralized training on a heterogeneous dataset. Empirical evidence from our comprehensive experiments indicates our method's superiority, delivering an accuracy enhancement of up to 40% over non-dataset-distillation techniques in highly heterogeneous FL contexts, and surpassing existing dataset-distillation methods by 18%. In addition to the high accuracy, our framework converges faster than the baselines because rather than the server trains on several sets of heterogeneous data distributions, it trains on a multi-modal distribution. Our code is available at https://github.com/FedDG23/FedDG-main.git
Efficient Dataset Distillation via Minimax Diffusion
Nov 27, 2023Dataset distillation reduces the storage and computational consumption of training a network by generating a small surrogate dataset that encapsulates rich information of the original large-scale one. However, previous distillation methods heavily rely on the sample-wise iterative optimization scheme. As the images-per-class (IPC) setting or image resolution grows larger, the necessary computation will demand overwhelming time and resources. In this work, we intend to incorporate generative diffusion techniques for computing the surrogate dataset. Observing that key factors for constructing an effective surrogate dataset are representativeness and diversity, we design additional minimax criteria in the generative training to enhance these facets for the generated images of diffusion models. We present a theoretical model of the process as hierarchical diffusion control demonstrating the flexibility of the diffusion process to target these criteria without jeopardizing the faithfulness of the sample to the desired distribution. The proposed method achieves state-of-the-art validation performance while demanding much less computational resources. Under the 100-IPC setting on ImageWoof, our method requires less than one-twentieth the distillation time of previous methods, yet yields even better performance. Source code available in https://github.com/vimar-gu/MinimaxDiffusion.
Quantum Solutions to the Privacy vs. Utility Tradeoff
Jul 06, 2023
In this work, we propose a novel architecture (and several variants thereof) based on quantum cryptographic primitives with provable privacy and security guarantees regarding membership inference attacks on generative models. Our architecture can be used on top of any existing classical or quantum generative models. We argue that the use of quantum gates associated with unitary operators provides inherent advantages compared to standard Differential Privacy based techniques for establishing guaranteed security from all polynomial-time adversaries.
A Stochastic-Gradient-based Interior-Point Algorithm for Solving Smooth Bound-Constrained Optimization Problems
Apr 28, 2023
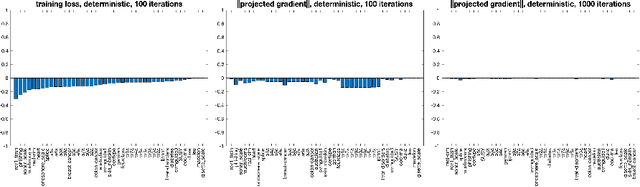
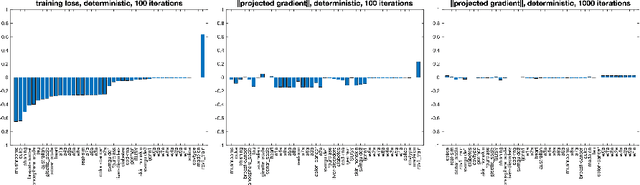
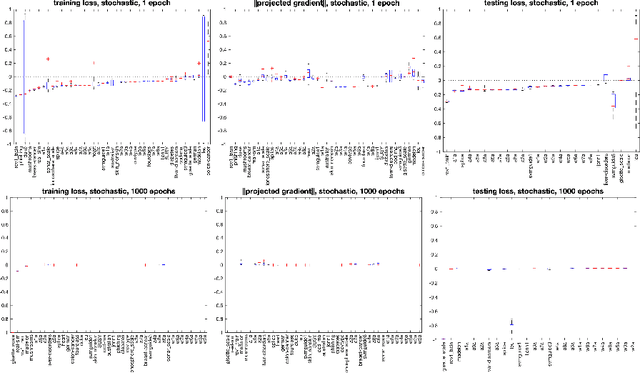
A stochastic-gradient-based interior-point algorithm for minimizing a continuously differentiable objective function (that may be nonconvex) subject to bound constraints is presented, analyzed, and demonstrated through experimental results. The algorithm is unique from other interior-point methods for solving smooth (nonconvex) optimization problems since the search directions are computed using stochastic gradient estimates. It is also unique in its use of inner neighborhoods of the feasible region -- defined by a positive and vanishing neighborhood-parameter sequence -- in which the iterates are forced to remain. It is shown that with a careful balance between the barrier, step-size, and neighborhood sequences, the proposed algorithm satisfies convergence guarantees in both deterministic and stochastic settings. The results of numerical experiments show that in both settings the algorithm can outperform a projected-(stochastic)-gradient method.
Riemannian Stochastic Approximation for Minimizing Tame Nonsmooth Objective Functions
Feb 08, 2023



In many learning applications, the parameters in a model are structurally constrained in a way that can be modeled as them lying on a Riemannian manifold. Riemannian optimization, wherein procedures to enforce an iterative minimizing sequence to be constrained to the manifold, is used to train such models. At the same time, tame geometry has become a significant topological description of nonsmooth functions that appear in the landscapes of training neural networks and other important models with structural compositions of continuous nonlinear functions with nonsmooth maps. In this paper, we study the properties of such stratifiable functions on a manifold and the behavior of retracted stochastic gradient descent, with diminishing stepsizes, for minimizing such functions.
When Do Curricula Work in Federated Learning?
Dec 24, 2022



An oft-cited open problem of federated learning is the existence of data heterogeneity at the clients. One pathway to understanding the drastic accuracy drop in federated learning is by scrutinizing the behavior of the clients' deep models on data with different levels of "difficulty", which has been left unaddressed. In this paper, we investigate a different and rarely studied dimension of FL: ordered learning. Specifically, we aim to investigate how ordered learning principles can contribute to alleviating the heterogeneity effects in FL. We present theoretical analysis and conduct extensive empirical studies on the efficacy of orderings spanning three kinds of learning: curriculum, anti-curriculum, and random curriculum. We find that curriculum learning largely alleviates non-IIDness. Interestingly, the more disparate the data distributions across clients the more they benefit from ordered learning. We provide analysis explaining this phenomenon, specifically indicating how curriculum training appears to make the objective landscape progressively less convex, suggesting fast converging iterations at the beginning of the training procedure. We derive quantitative results of convergence for both convex and nonconvex objectives by modeling the curriculum training on federated devices as local SGD with locally biased stochastic gradients. Also, inspired by ordered learning, we propose a novel client selection technique that benefits from the real-world disparity in the clients. Our proposed approach to client selection has a synergic effect when applied together with ordered learning in FL.
Jump-Diffusion Langevin Dynamics for Multimodal Posterior Sampling
Nov 02, 2022



Bayesian methods of sampling from a posterior distribution are becoming increasingly popular due to their ability to precisely display the uncertainty of a model fit. Classical methods based on iterative random sampling and posterior evaluation such as Metropolis-Hastings are known to have desirable long run mixing properties, however are slow to converge. Gradient based methods, such as Langevin Dynamics (and its stochastic gradient counterpart) exhibit favorable dimension-dependence and fast mixing times for log-concave, and "close" to log-concave distributions, however also have long escape times from local minimizers. Many contemporary applications such as Bayesian Neural Networks are both high-dimensional and highly multimodal. In this paper we investigate the performance of a hybrid Metropolis and Langevin sampling method akin to Jump Diffusion on a range of synthetic and real data, indicating that careful calibration of mixing sampling jumps with gradient based chains significantly outperforms both pure gradient-based or sampling based schemes.
Mean-field analysis for heavy ball methods: Dropout-stability, connectivity, and global convergence
Oct 13, 2022
The stochastic heavy ball method (SHB), also known as stochastic gradient descent (SGD) with Polyak's momentum, is widely used in training neural networks. However, despite the remarkable success of such algorithm in practice, its theoretical characterization remains limited. In this paper, we focus on neural networks with two and three layers and provide a rigorous understanding of the properties of the solutions found by SHB: \emph{(i)} stability after dropping out part of the neurons, \emph{(ii)} connectivity along a low-loss path, and \emph{(iii)} convergence to the global optimum. To achieve this goal, we take a mean-field view and relate the SHB dynamics to a certain partial differential equation in the limit of large network widths. This mean-field perspective has inspired a recent line of work focusing on SGD while, in contrast, our paper considers an algorithm with momentum. More specifically, after proving existence and uniqueness of the limit differential equations, we show convergence to the global optimum and give a quantitative bound between the mean-field limit and the SHB dynamics of a finite-width network. Armed with this last bound, we are able to establish the dropout-stability and connectivity of SHB solutions.
Efficient Distribution Similarity Identification in Clustered Federated Learning via Principal Angles Between Client Data Subspaces
Sep 21, 2022



Clustered federated learning (FL) has been shown to produce promising results by grouping clients into clusters. This is especially effective in scenarios where separate groups of clients have significant differences in the distributions of their local data. Existing clustered FL algorithms are essentially trying to group together clients with similar distributions so that clients in the same cluster can leverage each other's data to better perform federated learning. However, prior clustered FL algorithms attempt to learn these distribution similarities indirectly during training, which can be quite time consuming as many rounds of federated learning may be required until the formation of clusters is stabilized. In this paper, we propose a new approach to federated learning that directly aims to efficiently identify distribution similarities among clients by analyzing the principal angles between the client data subspaces. Each client applies a truncated singular value decomposition (SVD) step on its local data in a single-shot manner to derive a small set of principal vectors, which provides a signature that succinctly captures the main characteristics of the underlying distribution. This small set of principal vectors is provided to the server so that the server can directly identify distribution similarities among the clients to form clusters. This is achieved by comparing the similarities of the principal angles between the client data subspaces spanned by those principal vectors. The approach provides a simple, yet effective clustered FL framework that addresses a broad range of data heterogeneity issues beyond simpler forms of Non-IIDness like label skews. Our clustered FL approach also enables convergence guarantees for non-convex objectives. Our code is available at https://github.com/MMorafah/PACFL.