 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeixiang Xu
HAFFormer: A Hierarchical Attention-Free Framework for Alzheimer's Disease Detection From Spontaneous Speech
May 07, 2024
Automatically detecting Alzheimer's Disease (AD) from spontaneous speech plays an important role in its early diagnosis. Recent approaches highly rely on the Transformer architectures due to its efficiency in modelling long-range context dependencies. However, the quadratic increase in computational complexity associated with self-attention and the length of audio poses a challenge when deploying such models on edge devices. In this context, we construct a novel framework, namely Hierarchical Attention-Free Transformer (HAFFormer), to better deal with long speech for AD detection. Specifically, we employ an attention-free module of Multi-Scale Depthwise Convolution to replace the self-attention and thus avoid the expensive computation, and a GELU-based Gated Linear Unit to replace the feedforward layer, aiming to automatically filter out the redundant information. Moreover, we design a hierarchical structure to force it to learn a variety of information grains, from the frame level to the dialogue level. By conducting extensive experiments on the ADReSS-M dataset, the introduced HAFFormer can achieve competitive results (82.6% accuracy) with other recent work, but with significant computational complexity and model size reduction compared to the standard Transformer. This shows the efficiency of HAFFormer in dealing with long audio for AD detection.
Soft Threshold Ternary Networks
Apr 04, 2022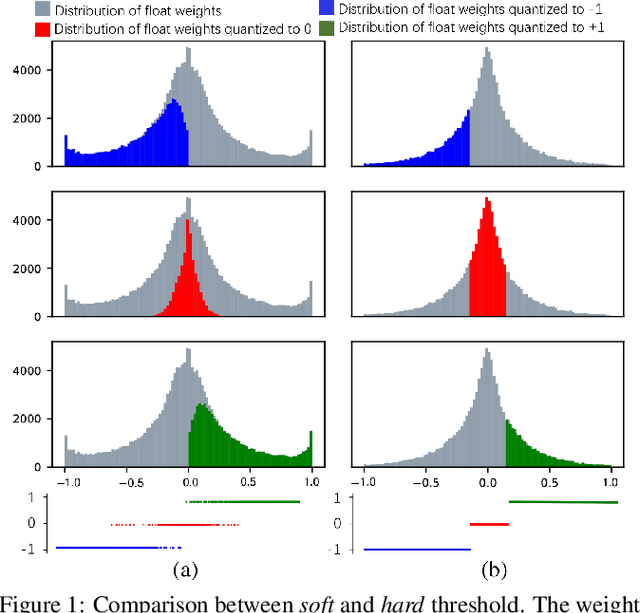

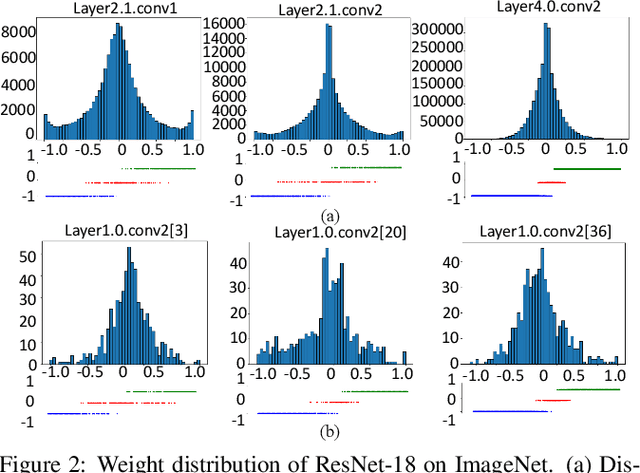

Large neural networks are difficult to deploy on mobile devices because of intensive computation and storage. To alleviate it, we study ternarization, a balance between efficiency and accuracy that quantizes both weights and activations into ternary values. In previous ternarized neural networks, a hard threshold {\Delta} is introduced to determine quantization intervals. Although the selection of {\Delta} greatly affects the training results, previous works estimate {\Delta} via an approximation or treat it as a hyper-parameter, which is suboptimal. In this paper, we present the Soft Threshold Ternary Networks (STTN), which enables the model to automatically determine quantization intervals instead of depending on a hard threshold. Concretely, we replace the original ternary kernel with the addition of two binary kernels at training time, where ternary values are determined by the combination of two corresponding binary values. At inference time, we add up the two binary kernels to obtain a single ternary kernel. Our method dramatically outperforms current state-of-the-arts, lowering the performance gap between full-precision networks and extreme low bit networks. Experiments on ImageNet with ResNet-18 (Top-1 66.2%) achieves new state-of-the-art. Update: In this version, we further fine-tune the experimental hyperparameters and training procedure. The latest STTN shows that ResNet-18 with ternary weights and ternary activations achieves up to 68.2% Top-1 accuracy on ImageNet. Code is available at: github.com/WeixiangXu/STTN.
Improving Binary Neural Networks through Fully Utilizing Latent Weights
Oct 12, 2021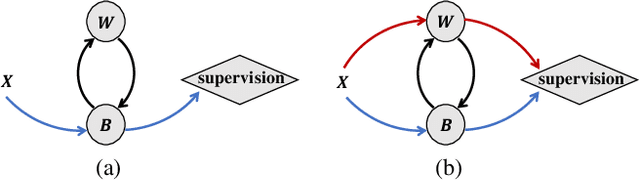

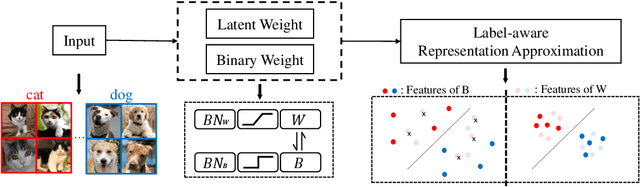
Binary Neural Networks (BNNs) rely on a real-valued auxiliary variable W to help binary training. However, pioneering binary works only use W to accumulate gradient updates during backward propagation, which can not fully exploit its power and may hinder novel advances in BNNs. In this work, we explore the role of W in training besides acting as a latent variable. Notably, we propose to add W into the computation graph, making it perform as a real-valued feature extractor to aid the binary training. We make different attempts on how to utilize the real-valued weights and propose a specialized supervision. Visualization experiments qualitatively verify the effectiveness of our approach in making it easier to distinguish between different categories. Quantitative experiments show that our approach outperforms current state-of-the-arts, further closing the performance gap between floating-point networks and BNNs. Evaluation on ImageNet with ResNet-18 (Top-1 63.4%), ResNet-34 (Top-1 67.0%) achieves new state-of-the-art.
Architecture Aware Latency Constrained Sparse Neural Networks
Sep 01, 2021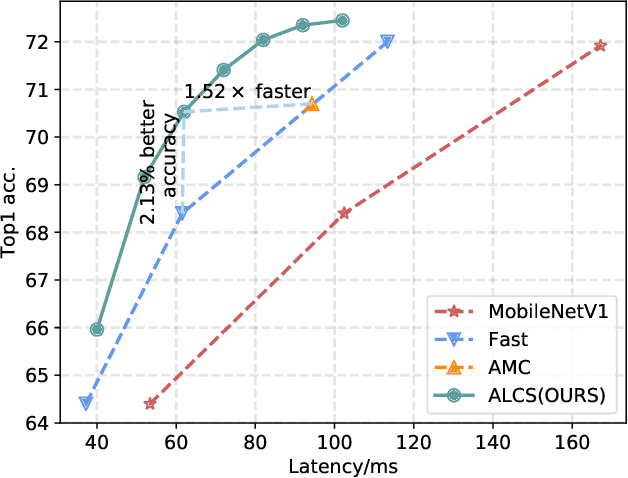
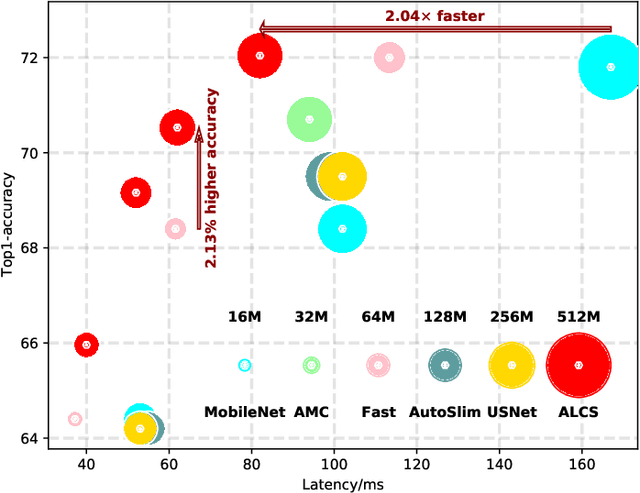
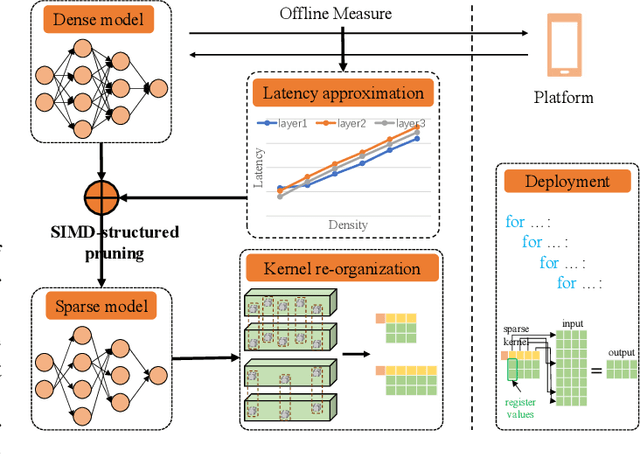
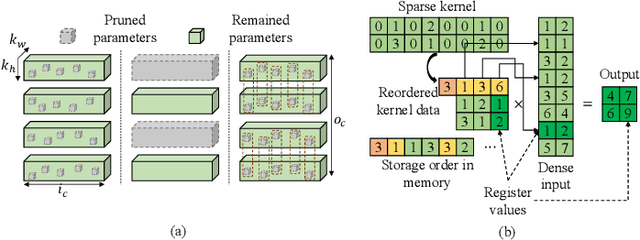
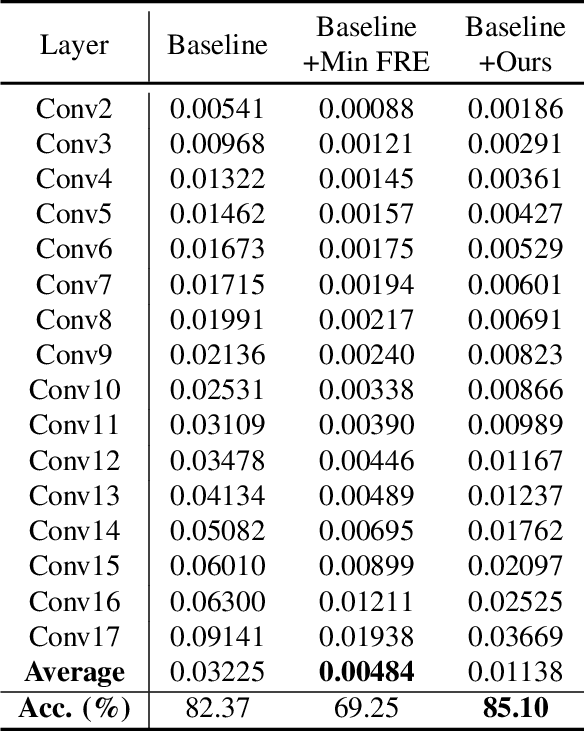
Acceleration of deep neural networks to meet a specific latency constraint is essential for their deployment on mobile devices. In this paper, we design an architecture aware latency constrained sparse (ALCS) framework to prune and accelerate CNN models. Taking modern mobile computation architectures into consideration, we propose Single Instruction Multiple Data (SIMD)-structured pruning, along with a novel sparse convolution algorithm for efficient computation. Besides, we propose to estimate the run time of sparse models with piece-wise linear interpolation. The whole latency constrained pruning task is formulated as a constrained optimization problem that can be efficiently solved with Alternating Direction Method of Multipliers (ADMM). Extensive experiments show that our system-algorithm co-design framework can achieve much better Pareto frontier among network accuracy and latency on resource-constrained mobile devices.