 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeiyan Shi
A Safe Harbor for AI Evaluation and Red Teaming
Mar 07, 2024

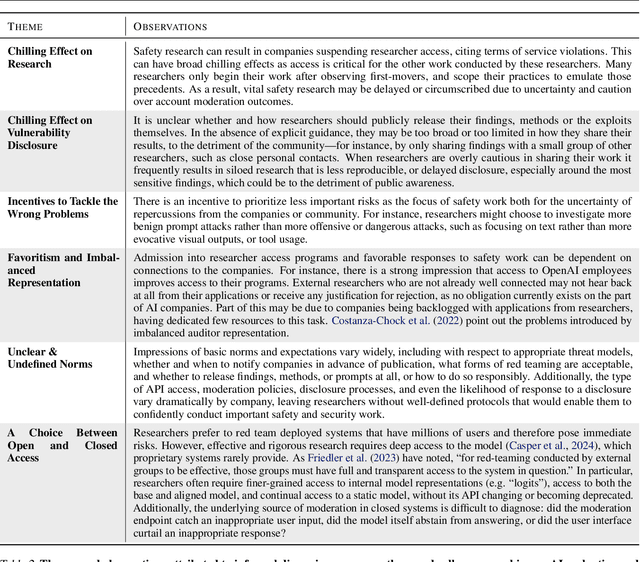

Independent evaluation and red teaming are critical for identifying the risks posed by generative AI systems. However, the terms of service and enforcement strategies used by prominent AI companies to deter model misuse have disincentives on good faith safety evaluations. This causes some researchers to fear that conducting such research or releasing their findings will result in account suspensions or legal reprisal. Although some companies offer researcher access programs, they are an inadequate substitute for independent research access, as they have limited community representation, receive inadequate funding, and lack independence from corporate incentives. We propose that major AI developers commit to providing a legal and technical safe harbor, indemnifying public interest safety research and protecting it from the threat of account suspensions or legal reprisal. These proposals emerged from our collective experience conducting safety, privacy, and trustworthiness research on generative AI systems, where norms and incentives could be better aligned with public interests, without exacerbating model misuse. We believe these commitments are a necessary step towards more inclusive and unimpeded community efforts to tackle the risks of generative AI.
The Mirrored Influence Hypothesis: Efficient Data Influence Estimation by Harnessing Forward Passes
Feb 14, 2024Large-scale black-box models have become ubiquitous across numerous applications. Understanding the influence of individual training data sources on predictions made by these models is crucial for improving their trustworthiness. Current influence estimation techniques involve computing gradients for every training point or repeated training on different subsets. These approaches face obvious computational challenges when scaled up to large datasets and models. In this paper, we introduce and explore the Mirrored Influence Hypothesis, highlighting a reciprocal nature of influence between training and test data. Specifically, it suggests that evaluating the influence of training data on test predictions can be reformulated as an equivalent, yet inverse problem: assessing how the predictions for training samples would be altered if the model were trained on specific test samples. Through both empirical and theoretical validations, we demonstrate the wide applicability of our hypothesis. Inspired by this, we introduce a new method for estimating the influence of training data, which requires calculating gradients for specific test samples, paired with a forward pass for each training point. This approach can capitalize on the common asymmetry in scenarios where the number of test samples under concurrent examination is much smaller than the scale of the training dataset, thus gaining a significant improvement in efficiency compared to existing approaches. We demonstrate the applicability of our method across a range of scenarios, including data attribution in diffusion models, data leakage detection, analysis of memorization, mislabeled data detection, and tracing behavior in language models. Our code will be made available at https://github.com/ruoxi-jia-group/Forward-INF.
How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge AI Safety by Humanizing LLMs
Jan 23, 2024Most traditional AI safety research has approached AI models as machines and centered on algorithm-focused attacks developed by security experts. As large language models (LLMs) become increasingly common and competent, non-expert users can also impose risks during daily interactions. This paper introduces a new perspective to jailbreak LLMs as human-like communicators, to explore this overlooked intersection between everyday language interaction and AI safety. Specifically, we study how to persuade LLMs to jailbreak them. First, we propose a persuasion taxonomy derived from decades of social science research. Then, we apply the taxonomy to automatically generate interpretable persuasive adversarial prompts (PAP) to jailbreak LLMs. Results show that persuasion significantly increases the jailbreak performance across all risk categories: PAP consistently achieves an attack success rate of over $92\%$ on Llama 2-7b Chat, GPT-3.5, and GPT-4 in $10$ trials, surpassing recent algorithm-focused attacks. On the defense side, we explore various mechanisms against PAP and, found a significant gap in existing defenses, and advocate for more fundamental mitigation for highly interactive LLMs
The Earth is Flat because...: Investigating LLMs' Belief towards Misinformation via Persuasive Conversation
Dec 29, 2023



Large Language Models (LLMs) encapsulate vast amounts of knowledge but still remain vulnerable to external misinformation. Existing research mainly studied this susceptibility behavior in a single-turn setting. However, belief can change during a multi-turn conversation, especially a persuasive one. Therefore, in this study, we delve into LLMs' susceptibility to persuasive conversations, particularly on factual questions that they can answer correctly. We first curate the Farm (i.e., Fact to Misinform) dataset, which contains factual questions paired with systematically generated persuasive misinformation. Then, we develop a testing framework to track LLMs' belief changes in a persuasive dialogue. Through extensive experiments, we find that LLMs' correct beliefs on factual knowledge can be easily manipulated by various persuasive strategies.
From Scroll to Misbelief: Modeling the Unobservable Susceptibility to Misinformation on Social Media
Nov 16, 2023Susceptibility to misinformation describes the extent to believe unverifiable claims, which is hidden in people's mental process and infeasible to observe. Existing susceptibility studies heavily rely on the self-reported beliefs, making any downstream applications on susceptability hard to scale. To address these limitations, in this work, we propose a computational model to infer users' susceptibility levels given their activities. Since user's susceptibility is a key indicator for their reposting behavior, we utilize the supervision from the observable sharing behavior to infer the underlying susceptibility tendency. The evaluation shows that our model yields estimations that are highly aligned with human judgment on users' susceptibility level comparisons. Building upon such large-scale susceptibility labeling, we further conduct a comprehensive analysis of how different social factors relate to susceptibility. We find that political leanings and psychological factors are associated with susceptibility in varying degrees.
Controllable Mixed-Initiative Dialogue Generation through Prompting
May 06, 2023
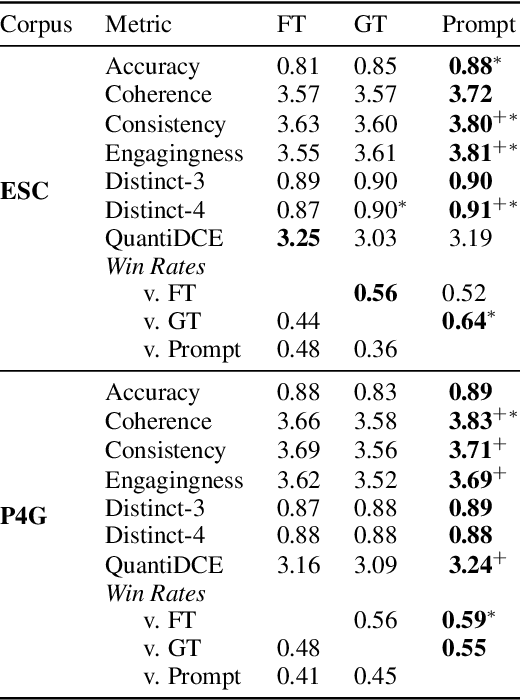


Mixed-initiative dialogue tasks involve repeated exchanges of information and conversational control. Conversational agents gain control by generating responses that follow particular dialogue intents or strategies, prescribed by a policy planner. The standard approach has been fine-tuning pre-trained language models to perform generation conditioned on these intents. However, these supervised generation models are limited by the cost and quality of data annotation. We instead prompt large language models as a drop-in replacement to fine-tuning on conditional generation. We formalize prompt construction for controllable mixed-initiative dialogue. Our findings show improvements over fine-tuning and ground truth responses according to human evaluation and automatic metrics for two tasks: PersuasionForGood and Emotional Support Conversations.
AutoReply: Detecting Nonsense in Dialogue Introspectively with Discriminative Replies
Nov 22, 2022
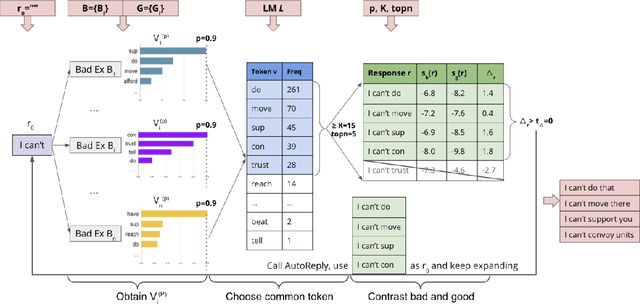
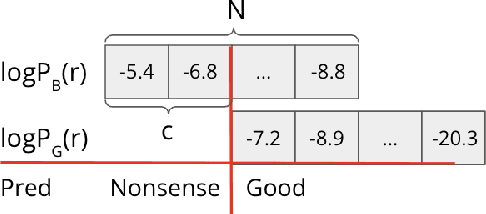

Existing approaches built separate classifiers to detect nonsense in dialogues. In this paper, we show that without external classifiers, dialogue models can detect errors in their own messages introspectively, by calculating the likelihood of replies that are indicative of poor messages. For example, if an agent believes its partner is likely to respond "I don't understand" to a candidate message, that message may not make sense, so an alternative message should be chosen. We evaluate our approach on a dataset from the game Diplomacy, which contains long dialogues richly grounded in the game state, on which existing models make many errors. We first show that hand-crafted replies can be effective for the task of detecting nonsense in applications as complex as Diplomacy. We then design AutoReply, an algorithm to search for such discriminative replies automatically, given a small number of annotated dialogue examples. We find that AutoReply-generated replies outperform handcrafted replies and perform on par with carefully fine-tuned large supervised models. Results also show that one single reply without much computation overheads can also detect dialogue nonsense reasonably well.
When Life Gives You Lemons, Make Cherryade: Converting Feedback from Bad Responses into Good Labels
Oct 28, 2022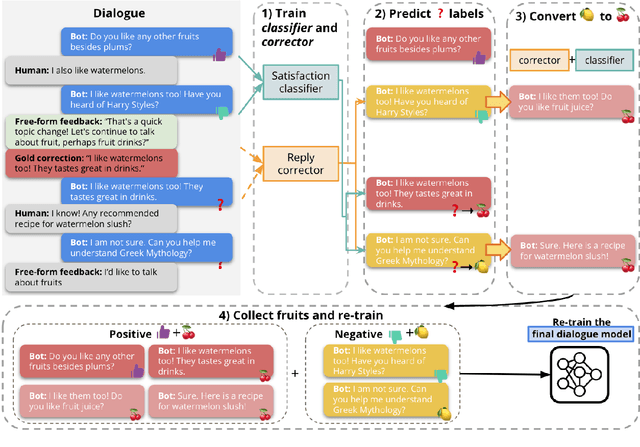
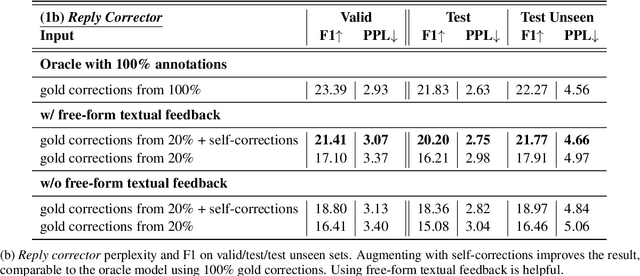
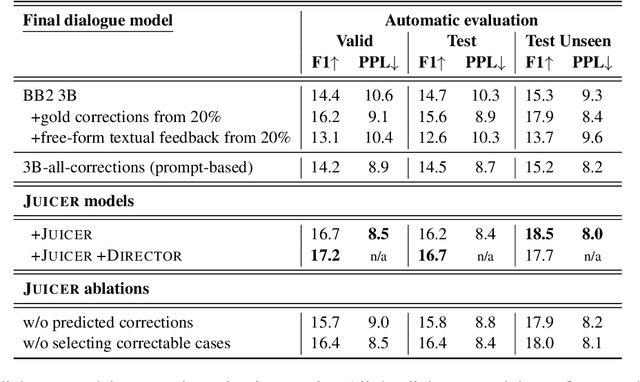

Deployed dialogue agents have the potential to integrate human feedback to continuously improve themselves. However, humans may not always provide explicit signals when the chatbot makes mistakes during interactions. In this work, we propose Juicer, a framework to make use of both binary and free-form textual human feedback. It works by: (i) extending sparse binary feedback by training a satisfaction classifier to label the unlabeled data; and (ii) training a reply corrector to map the bad replies to good ones. We find that augmenting training with model-corrected replies improves the final dialogue model, and we can further improve performance by using both positive and negative replies through the recently proposed Director model.
Social Influence Dialogue Systems: A Scoping Survey of the Efforts Towards Influence Capabilities of Dialogue Systems
Oct 11, 2022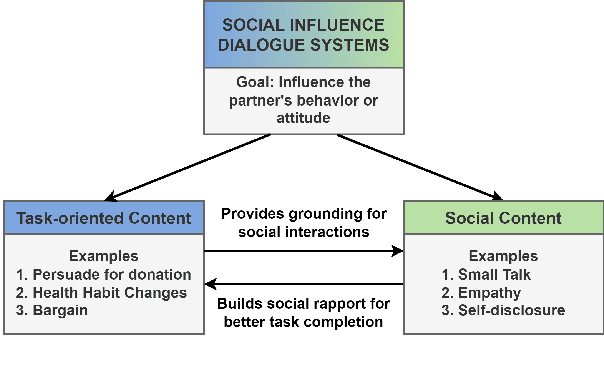
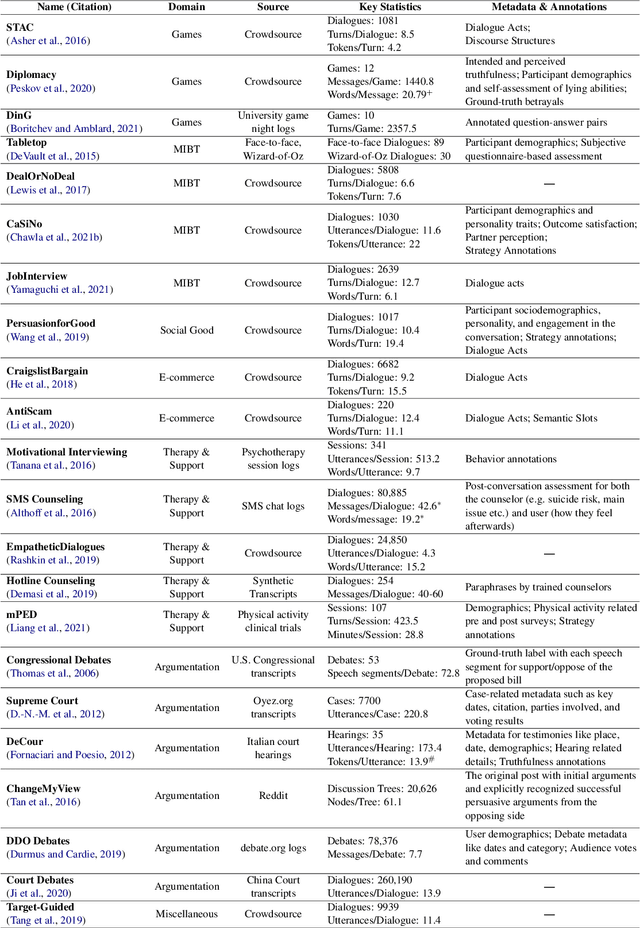
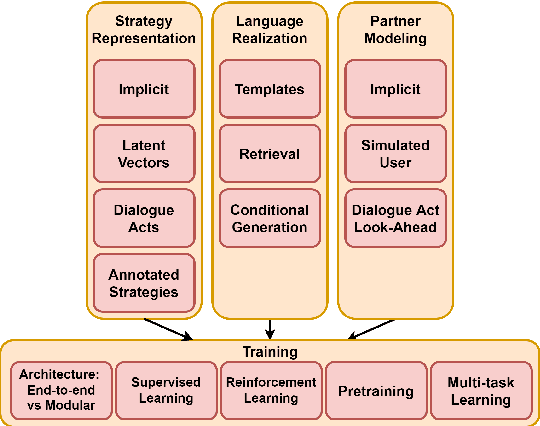
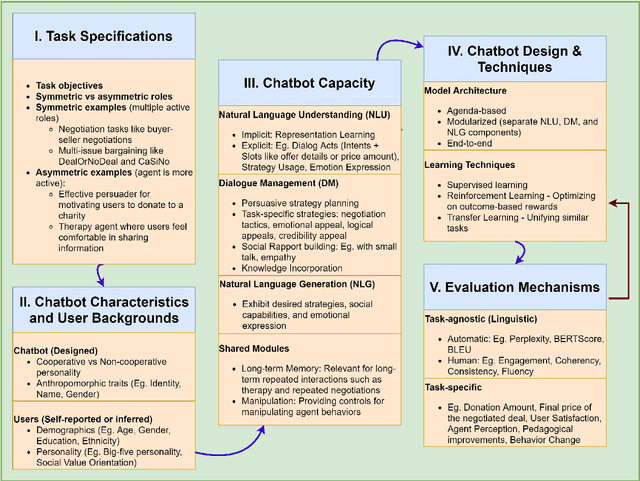
Dialogue systems capable of social influence such as persuasion, negotiation, and therapy, are essential for extending the use of technology to numerous realistic scenarios. However, existing research primarily focuses on either task-oriented or open-domain scenarios, a categorization that has been inadequate for capturing influence skills systematically. There exists no formal definition or category for dialogue systems with these skills and data-driven efforts in this direction are highly limited. In this work, we formally define and introduce the category of \emph{social influence dialogue systems} that influence users' cognitive and emotional responses, leading to changes in thoughts, opinions, and behaviors through natural conversations. We present a survey of various tasks, datasets, and methods, compiling the progress across seven diverse domains. We discuss the commonalities and differences between the examined systems, identify limitations, and recommend future directions. This study serves as a comprehensive reference for social influence dialogue systems to inspire more dedicated research and discussion in this emerging area.
Just Fine-tune Twice: Selective Differential Privacy for Large Language Models
Apr 15, 2022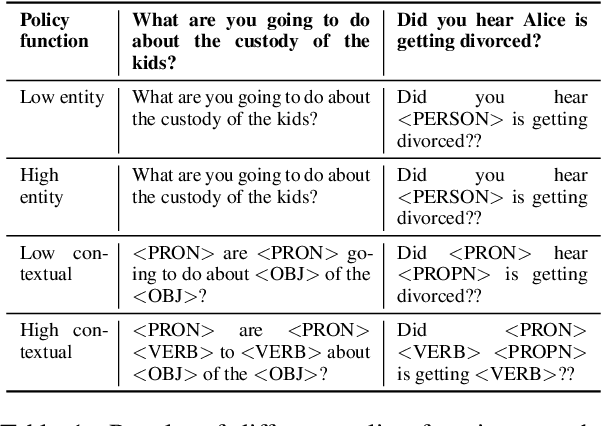
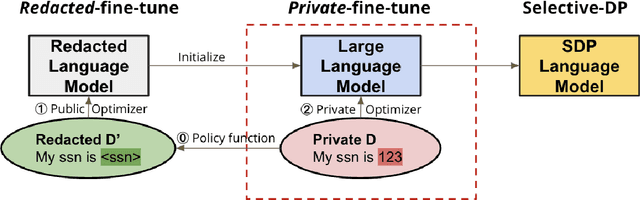
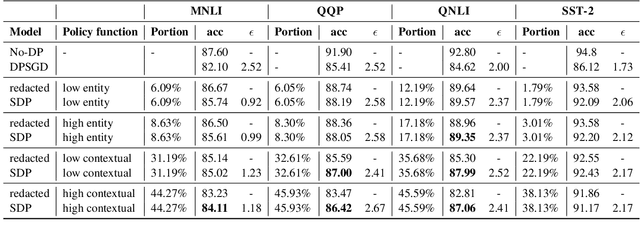
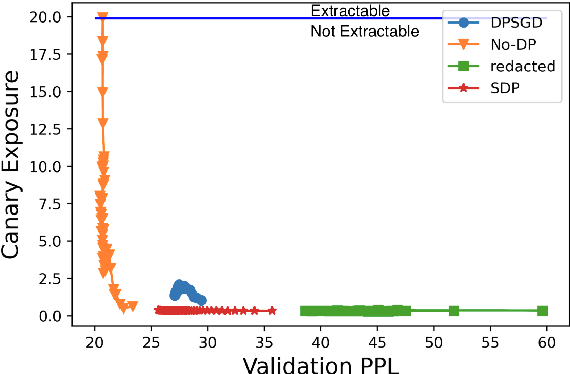
With the increasing adoption of NLP models in real-world products, it becomes more and more important to protect these models from privacy leakage. Because private information in language data is sparse, previous research formalized a Selective-Differential-Privacy (SDP) notion to provide protection for sensitive tokens detected by policy functions, and prove its effectiveness on RNN-based models. But the previous mechanism requires separating the private and public model parameters and thus cannot be applied on large attention-based models. In this paper, we propose a simple yet effective just-fine-tune-twice privacy mechanism to first fine-tune on in-domain redacted data and then on in-domain private data, to achieve SDP for large Transformer-based language models. We also design explicit and contextual policy functions to provide protections at different levels. Experiments show that our models achieve strong performance while staying robust to the canary insertion attack. We further show that even under low-resource settings with a small amount of in-domain data, SDP can still improve the model utility. We will release the code, data and models to facilitate future research.