 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianqi Zhang
Performance Analysis for Downlink Transmission in Multi-Connectivity Cellular V2X Networks
Apr 27, 2024




With the ever-increasing number of connected vehicles in the fifth-generation mobile communication networks (5G) and beyond 5G (B5G), ensuring the reliability and high-speed demand of cellular vehicle-to-everything (C-V2X) communication in scenarios where vehicles are moving at high speeds poses a significant challenge.Recently, multi-connectivity technology has become a promising network access paradigm for improving network performance and reliability for C-V2X in the 5G and B5G era. To this end, this paper proposes an analytical framework for the performance of downlink in multi-connectivity C-V2X networks. Specifically, by modeling the vehicles and base stations as one-dimensional Poisson point processes, we first derive and analyze the joint distance distribution of multi-connectivity. Then through leveraging the tools of stochastic geometry, the coverage probability and spectral efficiency are obtained based on the previous results for general multi-connectivity cases in C-V2X. Additionally, we evaluate the effect of path loss exponent and the density of downlink base station on system performance indicators. We demonstrate through extensive Monte Carlo simulations that multi-connectivity technology can effectively enhance network performance in C-V2X. Our findings have important implications for the research and application of multi-connectivity C-V2X in the 5G and B5G era.
The Earth is Flat because...: Investigating LLMs' Belief towards Misinformation via Persuasive Conversation
Dec 29, 2023



Large Language Models (LLMs) encapsulate vast amounts of knowledge but still remain vulnerable to external misinformation. Existing research mainly studied this susceptibility behavior in a single-turn setting. However, belief can change during a multi-turn conversation, especially a persuasive one. Therefore, in this study, we delve into LLMs' susceptibility to persuasive conversations, particularly on factual questions that they can answer correctly. We first curate the Farm (i.e., Fact to Misinform) dataset, which contains factual questions paired with systematically generated persuasive misinformation. Then, we develop a testing framework to track LLMs' belief changes in a persuasive dialogue. Through extensive experiments, we find that LLMs' correct beliefs on factual knowledge can be easily manipulated by various persuasive strategies.
SpecHD: Hyperdimensional Computing Framework for FPGA-based Mass Spectrometry Clustering
Nov 20, 2023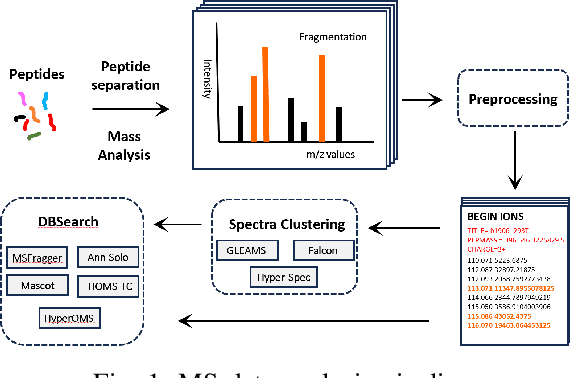
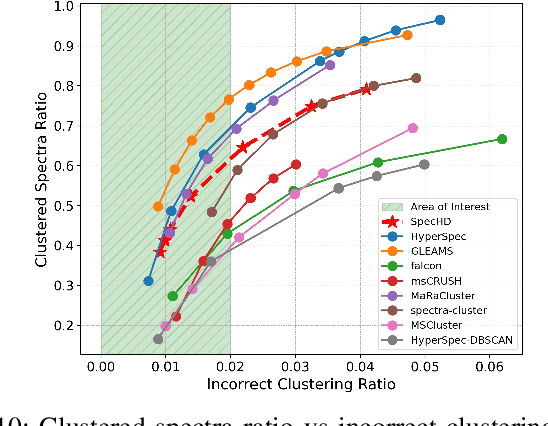
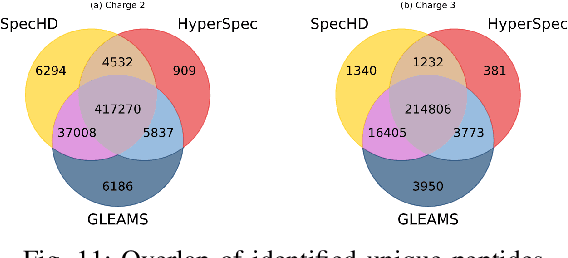
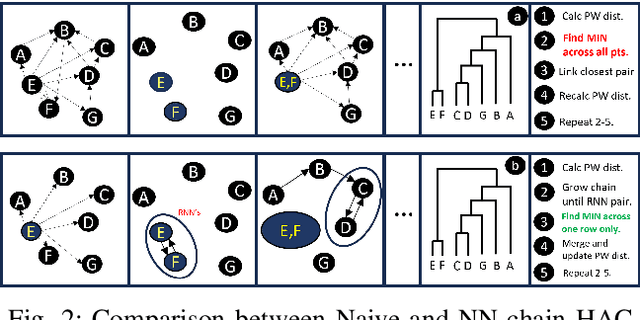
Mass spectrometry-based proteomics is a key enabler for personalized healthcare, providing a deep dive into the complex protein compositions of biological systems. This technology has vast applications in biotechnology and biomedicine but faces significant computational bottlenecks. Current methodologies often require multiple hours or even days to process extensive datasets, particularly in the domain of spectral clustering. To tackle these inefficiencies, we introduce SpecHD, a hyperdimensional computing (HDC) framework supplemented by an FPGA-accelerated architecture with integrated near-storage preprocessing. Utilizing streamlined binary operations in an HDC environment, SpecHD capitalizes on the low-latency and parallel capabilities of FPGAs. This approach markedly improves clustering speed and efficiency, serving as a catalyst for real-time, high-throughput data analysis in future healthcare applications. Our evaluations demonstrate that SpecHD not only maintains but often surpasses existing clustering quality metrics while drastically cutting computational time. Specifically, it can cluster a large-scale human proteome dataset-comprising 25 million MS/MS spectra and 131 GB of MS data-in just 5 minutes. With energy efficiency exceeding 31x and a speedup factor that spans a range of 6x to 54x over existing state of-the-art solutions, SpecHD emerges as a promising solution for the rapid analysis of mass spectrometry data with great implications for personalized healthcare.
Spectral Efficiency Analysis of Uplink-Downlink Decoupled Access in C-V2X Networks
Dec 12, 2022



The uplink (UL)/downlink (DL) decoupled access has been emerging as a novel access architecture to improve the performance gains in cellular networks. In this paper, we investigate the UL/DL decoupled access performance in cellular vehicle-to-everything (C-V2X). We propose a unified analytical framework for the UL/DL decoupled access in C-V2X from the perspective of spectral efficiency (SE). By modeling the UL/DL decoupled access C-V2X as a Cox process and leveraging the stochastic geometry, we obtain the joint association probability, the UL/DL distance distributions to serving base stations and the SE for the UL/DL decoupled access in C-V2X networks with different association cases. We conduct extensive Monte Carlo simulations to verify the accuracy of the proposed unified analytical framework, and the results show a better system average SE of UL/DL decoupled access in C-V2X.
A Novel Autonomous Robotics System for Aquaculture Environment Monitoring
Nov 08, 2022

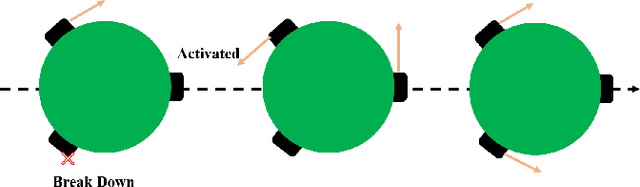
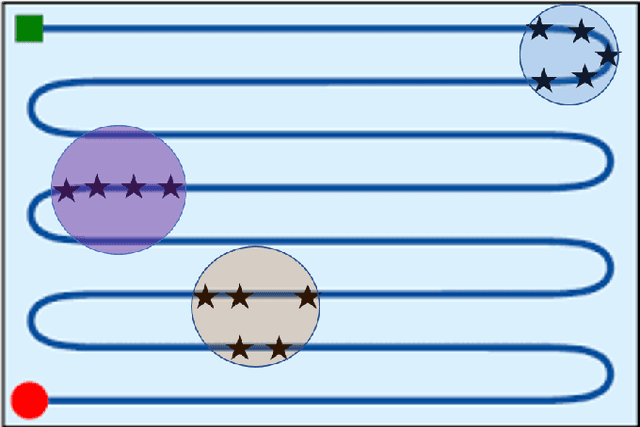
Implementing fully automatic unmanned surface vehicles (USVs) monitoring water quality is challenging since effectively collecting environmental data while keeping the platform stable and environmental-friendly is hard to approach. To address this problem, we construct a USV that can automatically navigate an efficient path to sample water quality parameters in order to monitor the aquatic environment. The detection device needs to be stable enough to resist a hostile environment or climates while enormous volumes will disturb the aquaculture environment. Meanwhile, planning an efficient path for information collecting needs to deal with the contradiction between the restriction of energy and the amount of information in the coverage region. To tackle with mentioned challenges, we provide a USV platform that can perfectly balance mobility, stability, and portability attributed to its special round-shape structure and redundancy motion design. For informative planning, we combined the TSP and CPP algorithms to construct an optimistic plan for collecting more data within a certain range and limiting energy restrictions.We designed a fish existence prediction scenario to verify the novel system in both simulation experiments and field experiments. The novel aquaculture environment monitoring system significantly reduces the burden of manual operation in the fishery inspection field. Additionally, the simplicity of the sensor setup and the minimal cost of the platform enables its other possible applications in aquatic exploration and commercial utilization.
VL-CheckList: Evaluating Pre-trained Vision-Language Models with Objects, Attributes and Relations
Jul 01, 2022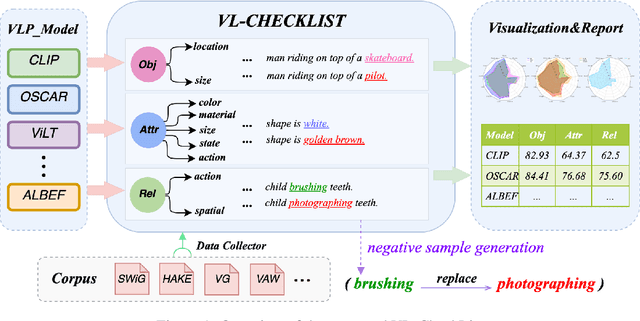
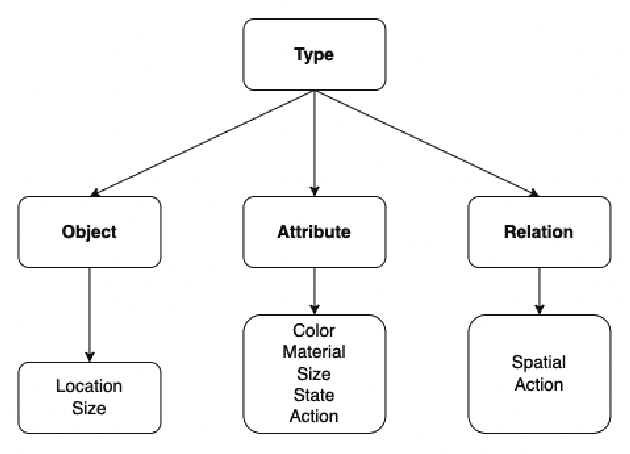
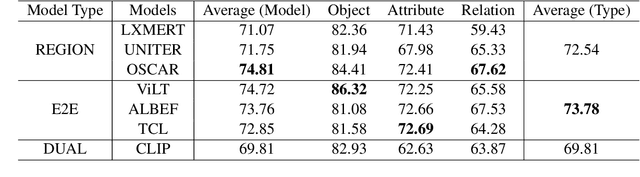
Vision-Language Pretraining (VLP) models have recently successfully facilitated many cross-modal downstream tasks. Most existing works evaluated their systems by comparing the fine-tuned downstream task performance. However, only average downstream task accuracy provides little information about the pros and cons of each VLP method, let alone provides insights on how the community can improve the systems in the future. Inspired by the CheckList for testing natural language processing, we introduce VL-CheckList, a novel framework to understand the capabilities of VLP models. The proposed method divides the image-texting ability of a VLP model into three categories: objects, attributes, and relations, and uses a novel taxonomy to further break down these three aspects. We conduct comprehensive studies to analyze seven recently popular VLP models via the proposed framework. Results confirm the effectiveness of the proposed method by revealing fine-grained differences among the compared models that were not visible from downstream task-only evaluation. Further results show promising research direction in building better VLP models. Data and Code: https://github.com/om-ai-lab/VL-CheckList
Combinatorial Learning of Graph Edit Distance via Dynamic Embedding
Dec 01, 2020



Graph Edit Distance (GED) is a popular similarity measurement for pairwise graphs and it also refers to the recovery of the edit path from the source graph to the target graph. Traditional A* algorithm suffers scalability issues due to its exhaustive nature, whose search heuristics heavily rely on human prior knowledge. This paper presents a hybrid approach by combing the interpretability of traditional search-based techniques for producing the edit path, as well as the efficiency and adaptivity of deep embedding models to achieve a cost-effective GED solver. Inspired by dynamic programming, node-level embedding is designated in a dynamic reuse fashion and suboptimal branches are encouraged to be pruned. To this end, our method can be readily integrated into A* procedure in a dynamic fashion, as well as significantly reduce the computational burden with a learned heuristic. Experimental results on different graph datasets show that our approach can remarkably ease the search process of A* without sacrificing much accuracy. To our best knowledge, this work is also the first deep learning-based GED method for recovering the edit path.
Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning
Oct 08, 2020



Graph representation learning has attracted lots of attention recently. Existing graph neural networks fed with the complete graph data are not scalable due to limited computation and memory costs. Thus, it remains a great challenge to capture rich information in large-scale graph data. Besides, these methods mainly focus on supervised learning and highly depend on node label information, which is expensive to obtain in the real world. As to unsupervised network embedding approaches, they overemphasize node proximity instead, whose learned representations can hardly be used in downstream application tasks directly. In recent years, emerging self-supervised learning provides a potential solution to address the aforementioned problems. However, existing self-supervised works also operate on the complete graph data and are biased to fit either global or very local (1-hop neighborhood) graph structures in defining the mutual information based loss terms. In this paper, a novel self-supervised representation learning method via Subgraph Contrast, namely \textsc{Subg-Con}, is proposed by utilizing the strong correlation between central nodes and their sampled subgraphs to capture regional structure information. Instead of learning on the complete input graph data, with a novel data augmentation strategy, \textsc{Subg-Con} learns node representations through a contrastive loss defined based on subgraphs sampled from the original graph instead. Compared with existing graph representation learning approaches, \textsc{Subg-Con} has prominent performance advantages in weaker supervision requirements, model learning scalability, and parallelization. Extensive experiments verify both the effectiveness and the efficiency of our work compared with both classic and state-of-the-art graph representation learning approaches on multiple real-world large-scale benchmark datasets from different domains.