 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenliang Chen
MoPE: Mixture of Prefix Experts for Zero-Shot Dialogue State Tracking
Apr 12, 2024
Zero-shot dialogue state tracking (DST) transfers knowledge to unseen domains, reducing the cost of annotating new datasets. Previous zero-shot DST models mainly suffer from domain transferring and partial prediction problems. To address these challenges, we propose Mixture of Prefix Experts (MoPE) to establish connections between similar slots in different domains, which strengthens the model transfer performance in unseen domains. Empirical results demonstrate that MoPE-DST achieves the joint goal accuracy of 57.13% on MultiWOZ2.1 and 55.40% on SGD.
DiffusionDialog: A Diffusion Model for Diverse Dialog Generation with Latent Space
Apr 10, 2024In real-life conversations, the content is diverse, and there exists the one-to-many problem that requires diverse generation. Previous studies attempted to introduce discrete or Gaussian-based continuous latent variables to address the one-to-many problem, but the diversity is limited. Recently, diffusion models have made breakthroughs in computer vision, and some attempts have been made in natural language processing. In this paper, we propose DiffusionDialog, a novel approach to enhance the diversity of dialogue generation with the help of diffusion model. In our approach, we introduce continuous latent variables into the diffusion model. The problem of using latent variables in the dialog task is how to build both an effective prior of the latent space and an inferring process to obtain the proper latent given the context. By combining the encoder and latent-based diffusion model, we encode the response's latent representation in a continuous space as the prior, instead of fixed Gaussian distribution or simply discrete ones. We then infer the latent by denoising step by step with the diffusion model. The experimental results show that our model greatly enhances the diversity of dialog responses while maintaining coherence. Furthermore, in further analysis, we find that our diffusion model achieves high inference efficiency, which is the main challenge of applying diffusion models in natural language processing.
Controllable and Diverse Data Augmentation with Large Language Model for Low-Resource Open-Domain Dialogue Generation
Mar 30, 2024Data augmentation (DA) is crucial to mitigate model training instability and over-fitting problems in low-resource open-domain dialogue generation. However, traditional DA methods often neglect semantic data diversity, restricting the overall quality. Recently, large language models (LLM) have been used for DA to generate diversified dialogues. However, they have limited controllability and tend to generate dialogues with a distribution shift compared to the seed dialogues. To maximize the augmentation diversity and address the controllability problem, we propose \textbf{S}ummary-based \textbf{D}ialogue \textbf{A}ugmentation with LLM (SDA). Our approach enhances the controllability of LLM by using dialogue summaries as a planning tool. Based on summaries, SDA can generate high-quality and diverse dialogue data even with a small seed dataset. To evaluate the efficacy of data augmentation methods for open-domain dialogue, we designed a clustering-based metric to characterize the semantic diversity of the augmented dialogue data. The experimental results show that SDA can augment high-quality and semantically diverse dialogues given a small seed dataset and an LLM, and the augmented data can boost the performance of open-domain dialogue models.
Mirror: A Universal Framework for Various Information Extraction Tasks
Nov 26, 2023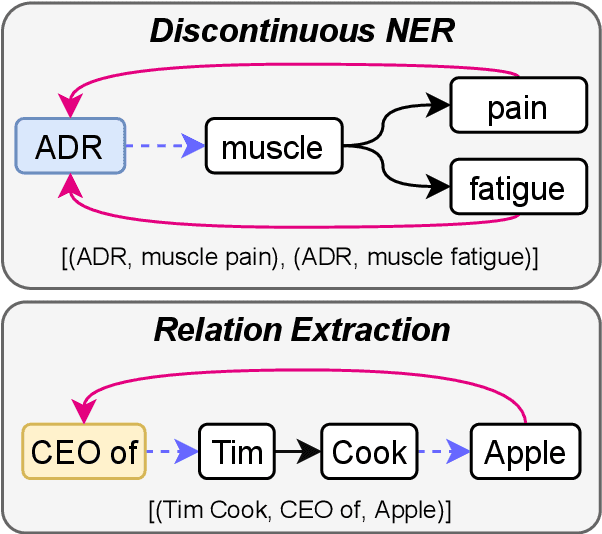
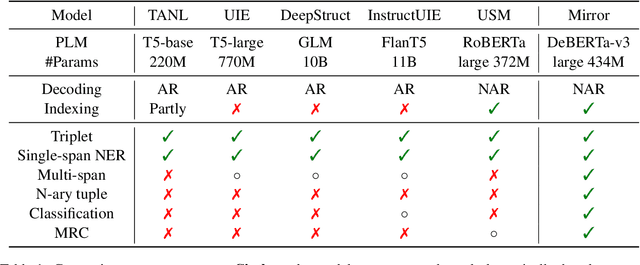
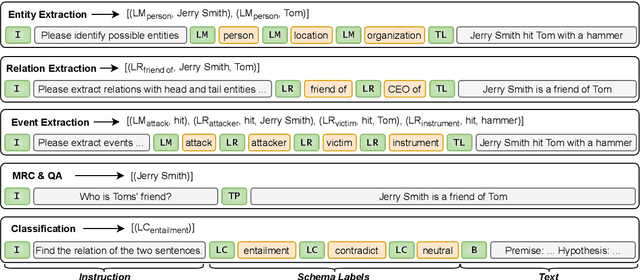
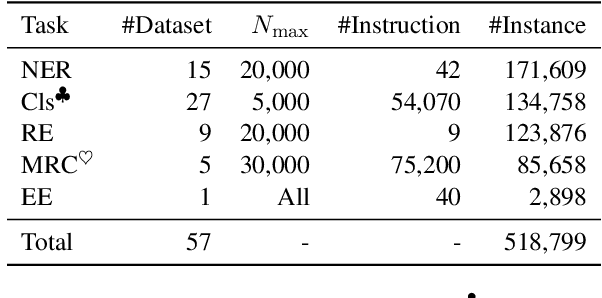
Sharing knowledge between information extraction tasks has always been a challenge due to the diverse data formats and task variations. Meanwhile, this divergence leads to information waste and increases difficulties in building complex applications in real scenarios. Recent studies often formulate IE tasks as a triplet extraction problem. However, such a paradigm does not support multi-span and n-ary extraction, leading to weak versatility. To this end, we reorganize IE problems into unified multi-slot tuples and propose a universal framework for various IE tasks, namely Mirror. Specifically, we recast existing IE tasks as a multi-span cyclic graph extraction problem and devise a non-autoregressive graph decoding algorithm to extract all spans in a single step. It is worth noting that this graph structure is incredibly versatile, and it supports not only complex IE tasks, but also machine reading comprehension and classification tasks. We manually construct a corpus containing 57 datasets for model pretraining, and conduct experiments on 30 datasets across 8 downstream tasks. The experimental results demonstrate that our model has decent compatibility and outperforms or reaches competitive performance with SOTA systems under few-shot and zero-shot settings. The code, model weights, and pretraining corpus are available at https://github.com/Spico197/Mirror .
OpenBA: An Open-sourced 15B Bilingual Asymmetric seq2seq Model Pre-trained from Scratch
Oct 01, 2023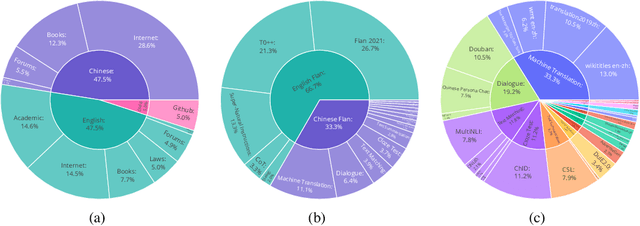


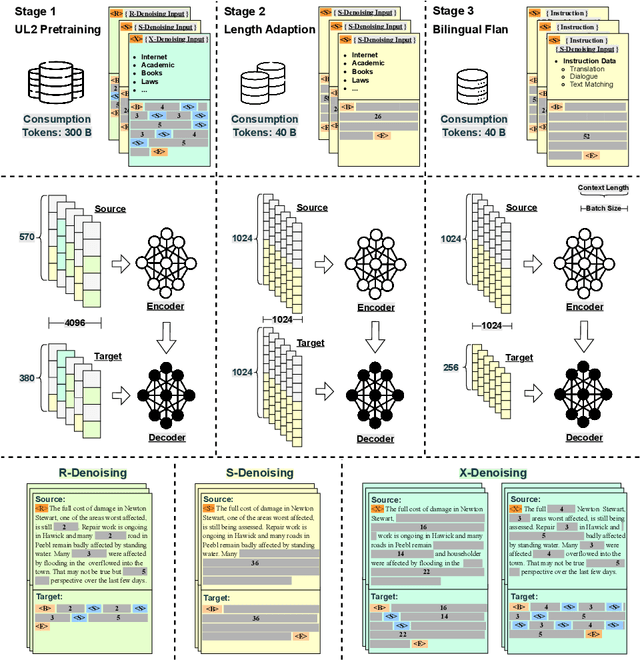
Large language models (LLMs) with billions of parameters have demonstrated outstanding performance on various natural language processing tasks. This report presents OpenBA, an open-sourced 15B bilingual asymmetric seq2seq model, to contribute an LLM variant to the Chinese-oriented open-source model community. We enhance OpenBA with effective and efficient techniques as well as adopt a three-stage training strategy to train the model from scratch. Our solution can also achieve very competitive performance with only 380B tokens, which is better than LLaMA-70B on the BELEBELE benchmark, BLOOM-176B on the MMLU benchmark, GLM-130B on the C-Eval (hard) benchmark. This report provides the main details to pre-train an analogous model, including pre-training data processing, Bilingual Flan data collection, the empirical observations that inspire our model architecture design, training objectives of different stages, and other enhancement techniques. Additionally, we also provide the fine-tuning details of OpenBA on four downstream tasks. We have refactored our code to follow the design principles of the Huggingface Transformers Library, making it more convenient for developers to use, and released checkpoints of different training stages at https://huggingface.co/openBA. More details of our project are available at https://github.com/OpenNLG/openBA.git.
Make a Choice! Knowledge Base Question Answering with In-Context Learning
May 23, 2023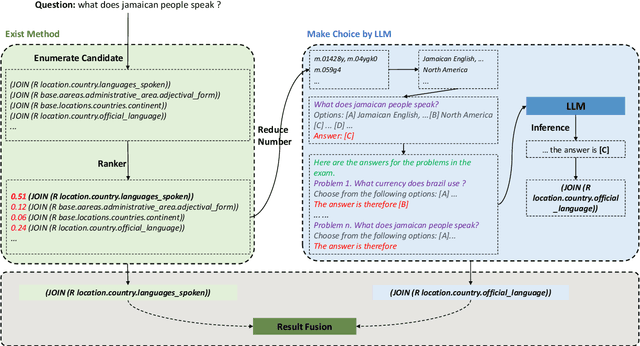
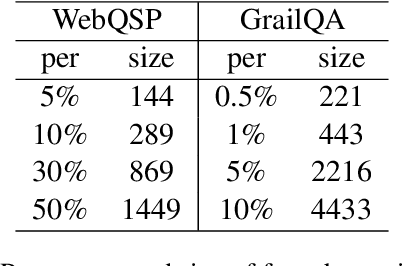

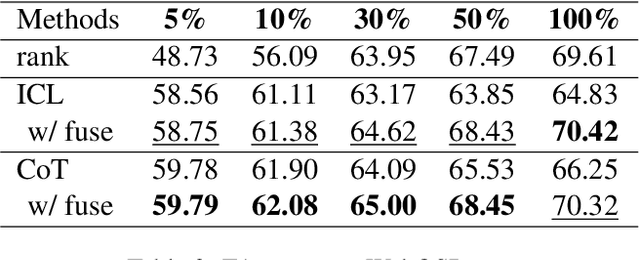
Question answering over knowledge bases (KBQA) aims to answer factoid questions with a given knowledge base (KB). Due to the large scale of KB, annotated data is impossible to cover all fact schemas in KB, which poses a challenge to the generalization ability of methods that require a sufficient amount of annotated data. Recently, LLMs have shown strong few-shot performance in many NLP tasks. We expect LLM can help existing methods improve their generalization ability, especially in low-resource situations. In this paper, we present McL-KBQA, a framework that incorporates the few-shot ability of LLM into the KBQA method via ICL-based multiple choice and then improves the effectiveness of the QA tasks. Experimental results on two KBQA datasets demonstrate the competitive performance of McL-KBQA with strong improvements in generalization. We expect to explore a new way to QA tasks from KBQA in conjunction with LLM, how to generate answers normatively and correctly with strong generalization.
CED: Catalog Extraction from Documents
Apr 28, 2023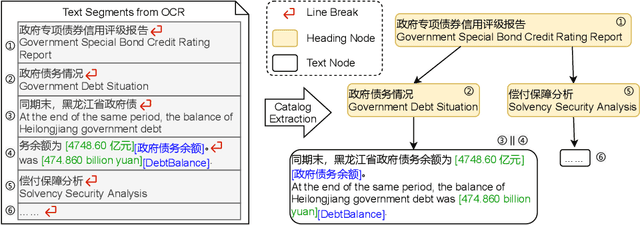
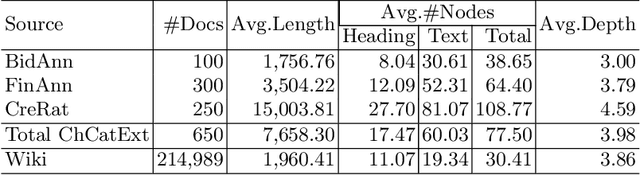
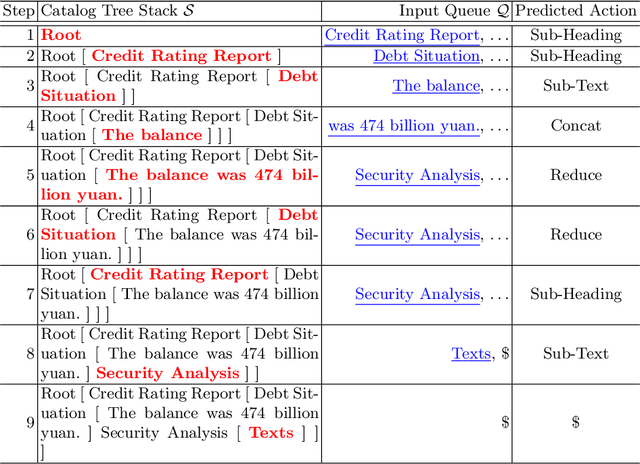
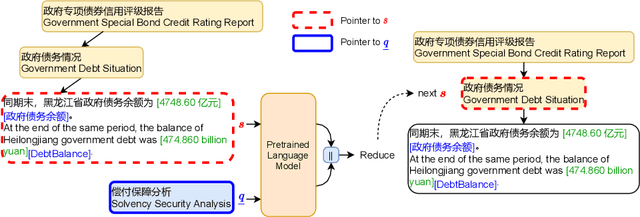
Sentence-by-sentence information extraction from long documents is an exhausting and error-prone task. As the indicator of document skeleton, catalogs naturally chunk documents into segments and provide informative cascade semantics, which can help to reduce the search space. Despite their usefulness, catalogs are hard to be extracted without the assist from external knowledge. For documents that adhere to a specific template, regular expressions are practical to extract catalogs. However, handcrafted heuristics are not applicable when processing documents from different sources with diverse formats. To address this problem, we build a large manually annotated corpus, which is the first dataset for the Catalog Extraction from Documents (CED) task. Based on this corpus, we propose a transition-based framework for parsing documents into catalog trees. The experimental results demonstrate that our proposed method outperforms baseline systems and shows a good ability to transfer. We believe the CED task could fill the gap between raw text segments and information extraction tasks on extremely long documents. Data and code are available at \url{https://github.com/Spico197/CatalogExtraction}
SelfMix: Robust Learning Against Textual Label Noise with Self-Mixup Training
Oct 11, 2022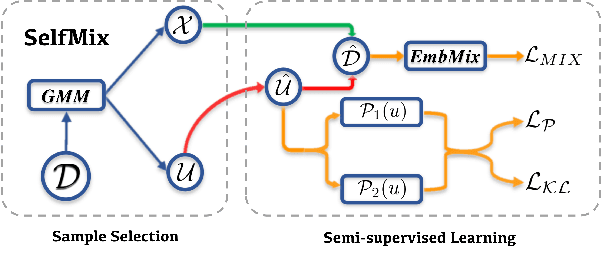

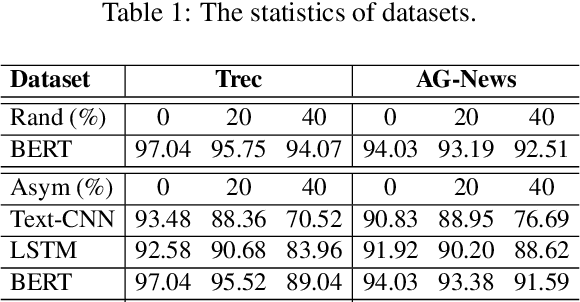
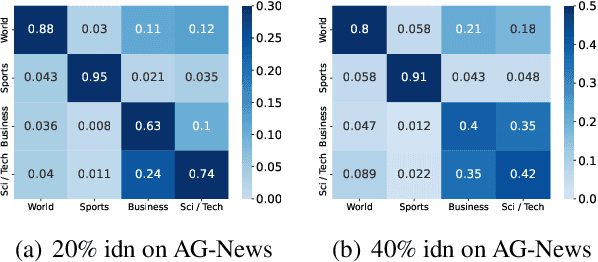
The conventional success of textual classification relies on annotated data, and the new paradigm of pre-trained language models (PLMs) still requires a few labeled data for downstream tasks. However, in real-world applications, label noise inevitably exists in training data, damaging the effectiveness, robustness, and generalization of the models constructed on such data. Recently, remarkable achievements have been made to mitigate this dilemma in visual data, while only a few explore textual data. To fill this gap, we present SelfMix, a simple yet effective method, to handle label noise in text classification tasks. SelfMix uses the Gaussian Mixture Model to separate samples and leverages semi-supervised learning. Unlike previous works requiring multiple models, our method utilizes the dropout mechanism on a single model to reduce the confirmation bias in self-training and introduces a textual-level mixup training strategy. Experimental results on three text classification benchmarks with different types of text show that the performance of our proposed method outperforms these strong baselines designed for both textual and visual data under different noise ratios and noise types. Our code is available at \url{https://github.com/noise-learning/SelfMix}.
STAD: Self-Training with Ambiguous Data for Low-Resource Relation Extraction
Sep 07, 2022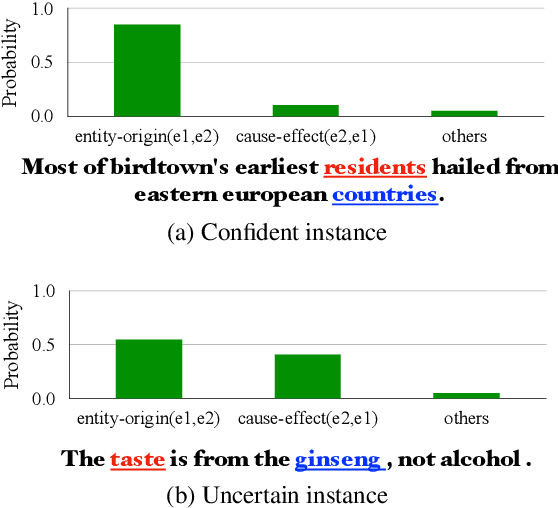
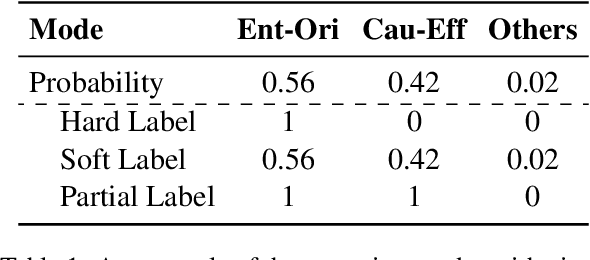
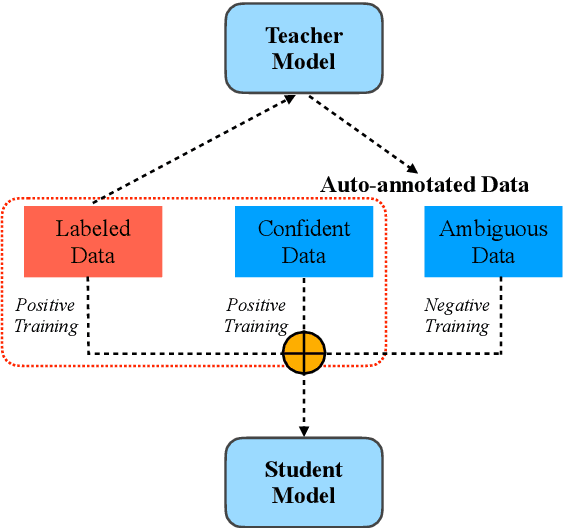
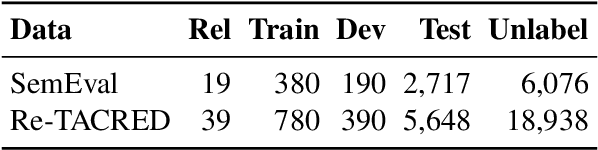
We present a simple yet effective self-training approach, named as STAD, for low-resource relation extraction. The approach first classifies the auto-annotated instances into two groups: confident instances and uncertain instances, according to the probabilities predicted by a teacher model. In contrast to most previous studies, which mainly only use the confident instances for self-training, we make use of the uncertain instances. To this end, we propose a method to identify ambiguous but useful instances from the uncertain instances and then divide the relations into candidate-label set and negative-label set for each ambiguous instance. Next, we propose a set-negative training method on the negative-label sets for the ambiguous instances and a positive training method for the confident instances. Finally, a joint-training method is proposed to build the final relation extraction system on all data. Experimental results on two widely used datasets SemEval2010 Task-8 and Re-TACRED with low-resource settings demonstrate that this new self-training approach indeed achieves significant and consistent improvements when comparing to several competitive self-training systems. Code is publicly available at https://github.com/jjyunlp/STAD
A Method of Query Graph Reranking for Knowledge Base Question Answering
Apr 27, 2022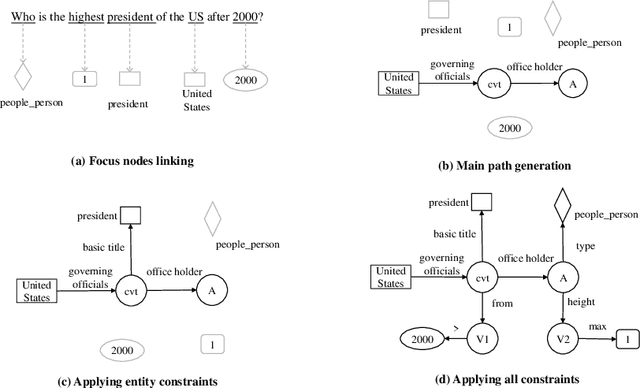

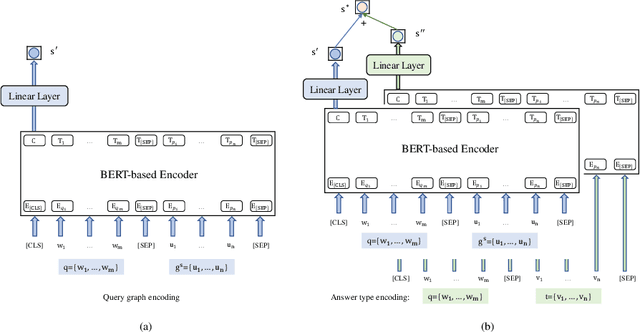
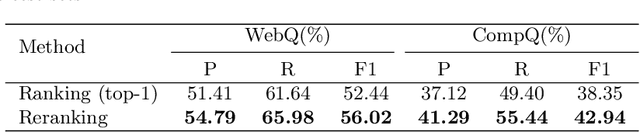
This paper presents a novel reranking method to better choose the optimal query graph, a sub-graph of knowledge graph, to retrieve the answer for an input question in Knowledge Base Question Answering (KBQA). Existing methods suffer from a severe problem that there is a significant gap between top-1 performance and the oracle score of top-n results. To address this problem, our method divides the choosing procedure into two steps: query graph ranking and query graph reranking. In the first step, we provide top-n query graphs for each question. Then we propose to rerank the top-n query graphs by combining with the information of answer type. Experimental results on two widely used datasets show that our proposed method achieves the best results on the WebQuestions dataset and the second best on the ComplexQuestions dataset.