 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWoo Jin Kim
Pixel-Level Equalized Matching for Video Object Segmentation
Sep 04, 2022
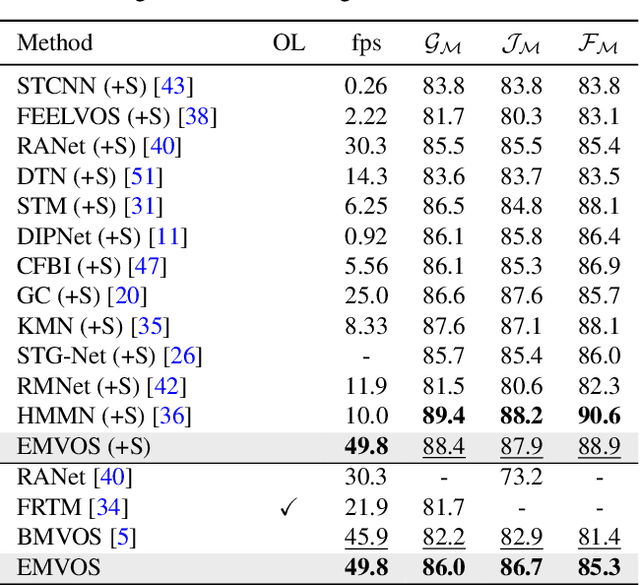
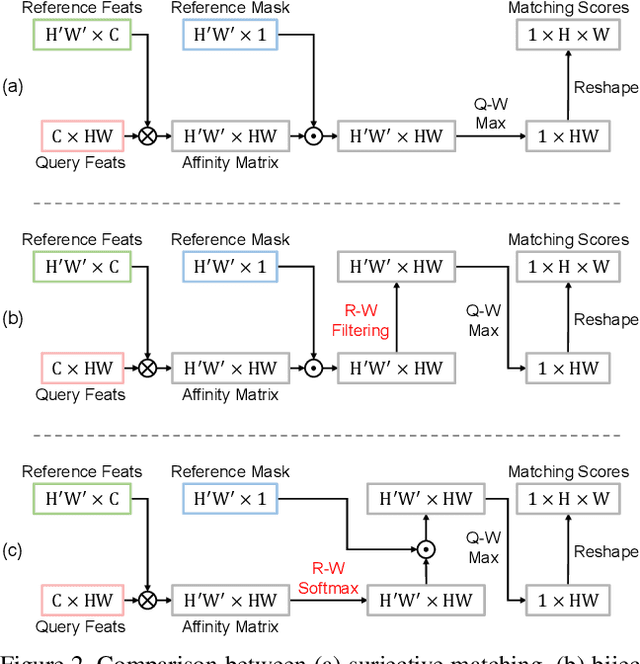
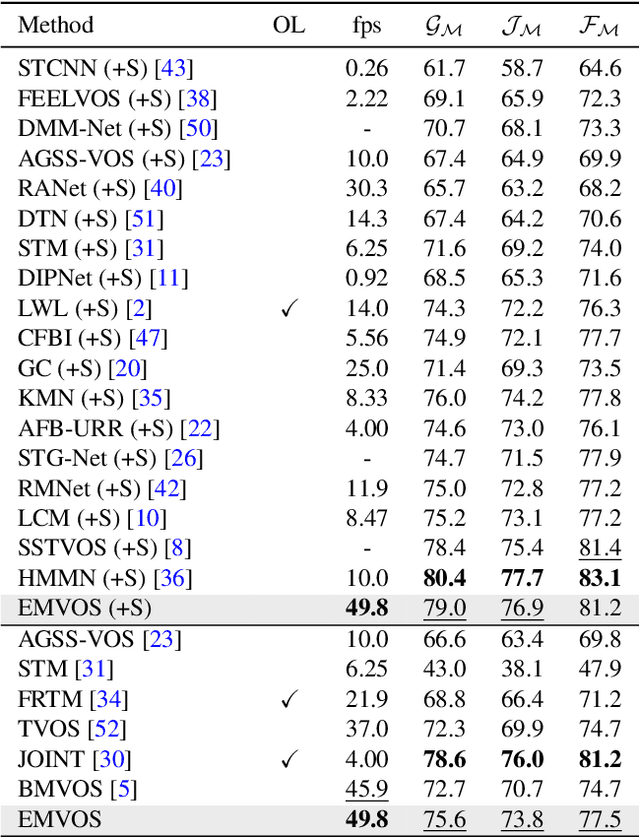
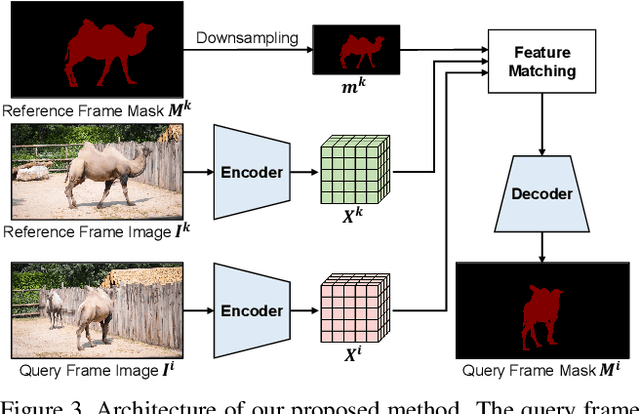
Feature similarity matching, which transfers the information of the reference frame to the query frame, is a key component in semi-supervised video object segmentation. If surjective matching is adopted, background distractors can easily occur and degrade the performance. Bijective matching mechanisms try to prevent this by restricting the amount of information being transferred to the query frame, but have two limitations: 1) surjective matching cannot be fully leveraged as it is transformed to bijective matching at test time; and 2) test-time manual tuning is required for searching the optimal hyper-parameters. To overcome these limitations while ensuring reliable information transfer, we introduce an equalized matching mechanism. To prevent the reference frame information from being overly referenced, the potential contribution to the query frame is equalized by simply applying a softmax operation along with the query. On public benchmark datasets, our proposed approach achieves a comparable performance to state-of-the-art methods.
AD-VO: Scale-Resilient Visual Odometry Using Attentive Disparity Map
Jan 07, 2020

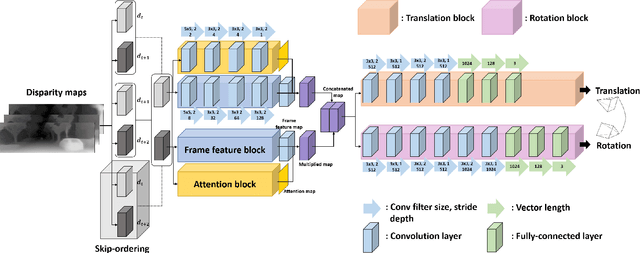
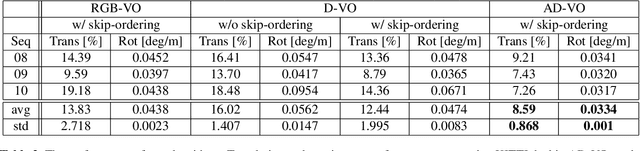
Visual odometry is an essential key for a localization module in SLAM systems. However, previous methods require tuning the system to adapt environment changes. In this paper, we propose a learning-based approach for frame-to-frame monocular visual odometry estimation. The proposed network is only learned by disparity maps for not only covering the environment changes but also solving the scale problem. Furthermore, attention block and skip-ordering scheme are introduced to achieve robust performance in various driving environment. Our network is compared with the conventional methods which use common domain such as color or optical flow. Experimental results confirm that the proposed network shows better performance than other approaches with higher and more stable results.