 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWujian Peng
Synthesize, Diagnose, and Optimize: Towards Fine-Grained Vision-Language Understanding
Nov 30, 2023
Vision language models (VLM) have demonstrated remarkable performance across various downstream tasks. However, understanding fine-grained visual-linguistic concepts, such as attributes and inter-object relationships, remains a significant challenge. While several benchmarks aim to evaluate VLMs in finer granularity, their primary focus remains on the linguistic aspect, neglecting the visual dimension. Here, we highlight the importance of evaluating VLMs from both a textual and visual perspective. We introduce a progressive pipeline to synthesize images that vary in a specific attribute while ensuring consistency in all other aspects. Utilizing this data engine, we carefully design a benchmark, SPEC, to diagnose the comprehension of object size, position, existence, and count. Subsequently, we conduct a thorough evaluation of four leading VLMs on SPEC. Surprisingly, their performance is close to random guess, revealing significant limitations. With this in mind, we propose a simply yet effective approach to optimize VLMs in fine-grained understanding, achieving significant improvements on SPEC without compromising the zero-shot performance. Results on two additional fine-grained benchmarks also show consistent improvements, further validating the transferability of our approach.
Building an Open-Vocabulary Video CLIP Model with Better Architectures, Optimization and Data
Oct 08, 2023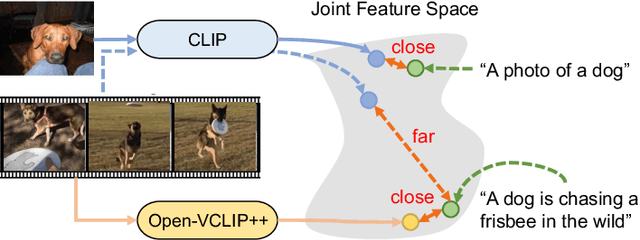
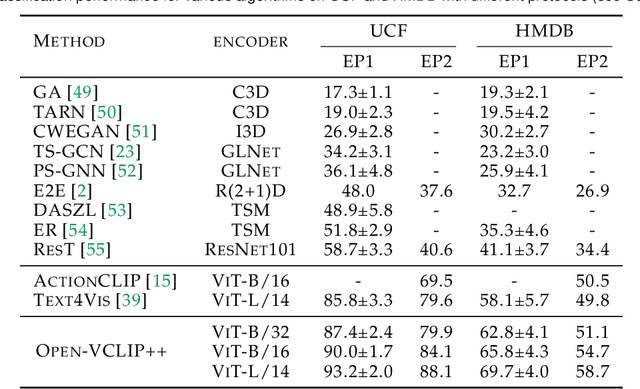

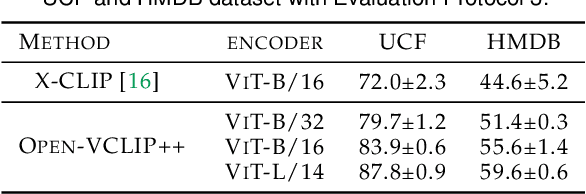
Despite significant results achieved by Contrastive Language-Image Pretraining (CLIP) in zero-shot image recognition, limited effort has been made exploring its potential for zero-shot video recognition. This paper presents Open-VCLIP++, a simple yet effective framework that adapts CLIP to a strong zero-shot video classifier, capable of identifying novel actions and events during testing. Open-VCLIP++ minimally modifies CLIP to capture spatial-temporal relationships in videos, thereby creating a specialized video classifier while striving for generalization. We formally demonstrate that training Open-VCLIP++ is tantamount to continual learning with zero historical data. To address this problem, we introduce Interpolated Weight Optimization, a technique that leverages the advantages of weight interpolation during both training and testing. Furthermore, we build upon large language models to produce fine-grained video descriptions. These detailed descriptions are further aligned with video features, facilitating a better transfer of CLIP to the video domain. Our approach is evaluated on three widely used action recognition datasets, following a variety of zero-shot evaluation protocols. The results demonstrate that our method surpasses existing state-of-the-art techniques by significant margins. Specifically, we achieve zero-shot accuracy scores of 88.1%, 58.7%, and 81.2% on UCF, HMDB, and Kinetics-600 datasets respectively, outpacing the best-performing alternative methods by 8.5%, 8.2%, and 12.3%. We also evaluate our approach on the MSR-VTT video-text retrieval dataset, where it delivers competitive video-to-text and text-to-video retrieval performance, while utilizing substantially less fine-tuning data compared to other methods. Code is released at https://github.com/wengzejia1/Open-VCLIP.
BMB: Balanced Memory Bank for Imbalanced Semi-supervised Learning
May 22, 2023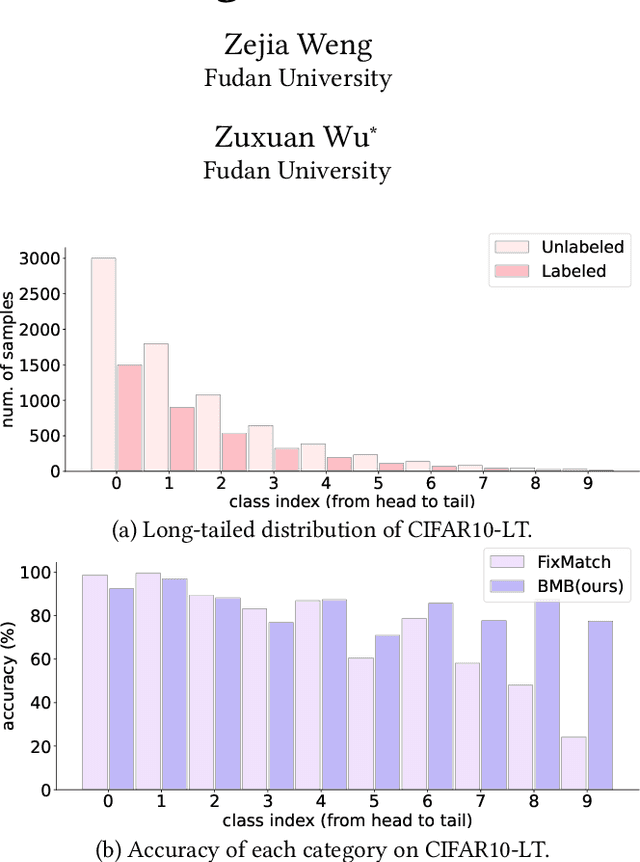
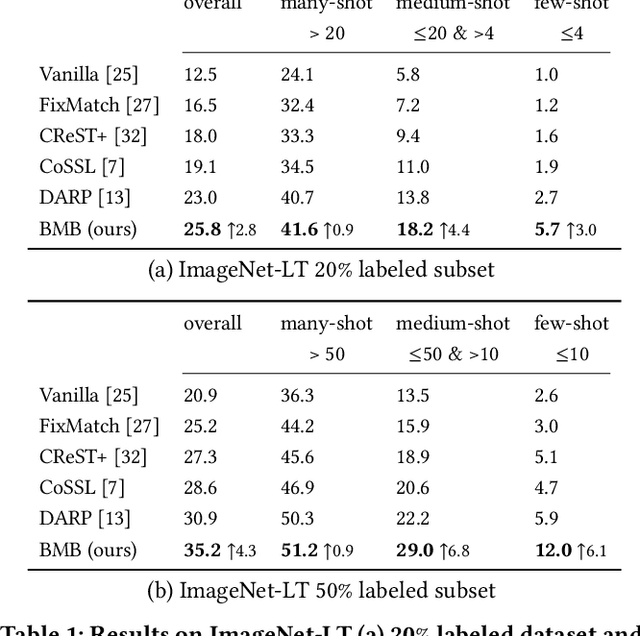


Exploring a substantial amount of unlabeled data, semi-supervised learning (SSL) boosts the recognition performance when only a limited number of labels are provided. However, traditional methods assume that the data distribution is class-balanced, which is difficult to achieve in reality due to the long-tailed nature of real-world data. While the data imbalance problem has been extensively studied in supervised learning (SL) paradigms, directly transferring existing approaches to SSL is nontrivial, as prior knowledge about data distribution remains unknown in SSL. In light of this, we propose Balanced Memory Bank (BMB), a semi-supervised framework for long-tailed recognition. The core of BMB is an online-updated memory bank that caches historical features with their corresponding pseudo labels, and the memory is also carefully maintained to ensure the data therein are class-rebalanced. Additionally, an adaptive weighting module is introduced to work jointly with the memory bank so as to further re-calibrate the biased training process. We conduct experiments on multiple datasets and demonstrate, among other things, that BMB surpasses state-of-the-art approaches by clear margins, for example 8.2$\%$ on the 1$\%$ labeled subset of ImageNet127 (with a resolution of 64$\times$64) and 4.3$\%$ on the 50$\%$ labeled subset of ImageNet-LT.