 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWukui Yang
Group-wise Correlation Stereo Network
Mar 10, 2019
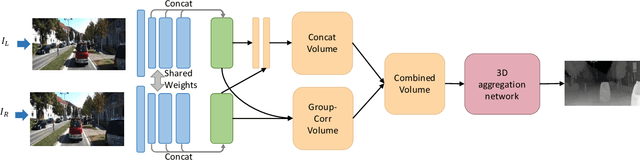
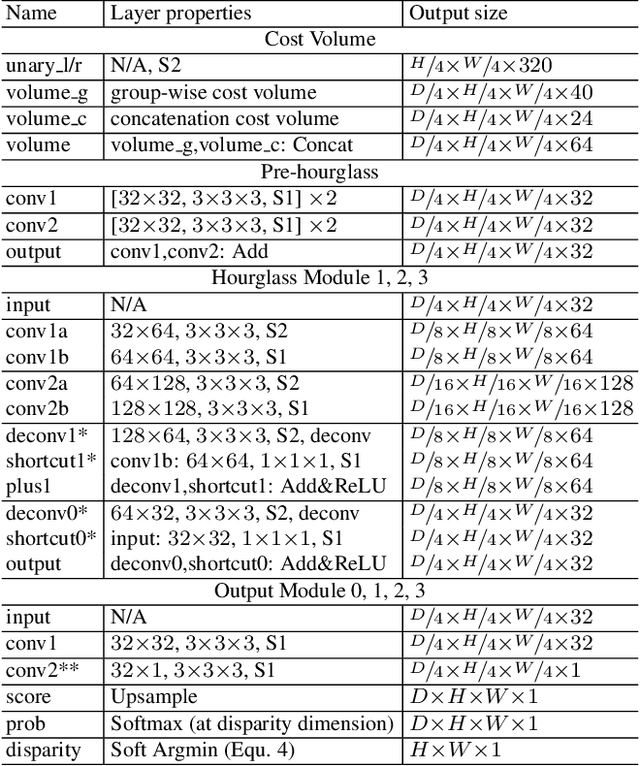

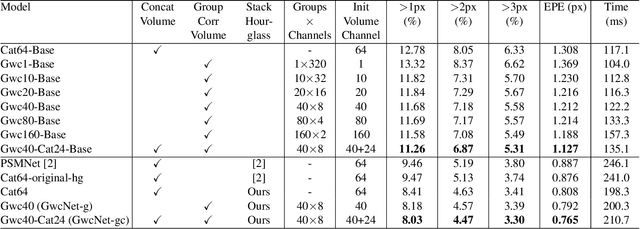
Stereo matching estimates the disparity between a rectified image pair, which is of great importance to depth sensing, autonomous driving, and other related tasks. Previous works built cost volumes with cross-correlation or concatenation of left and right features across all disparity levels, and then a 2D or 3D convolutional neural network is utilized to regress the disparity maps. In this paper, we propose to construct the cost volume by group-wise correlation. The left features and the right features are divided into groups along the channel dimension, and correlation maps are computed among each group to obtain multiple matching cost proposals, which are then packed into a cost volume. Group-wise correlation provides efficient representations for measuring feature similarities and will not lose too much information like full correlation. It also preserves better performance when reducing parameters compared with previous methods. The 3D stacked hourglass network proposed in previous works is improved to boost the performance and decrease the inference computational cost. Experiment results show that our method outperforms previous methods on Scene Flow, KITTI 2012, and KITTI 2015 datasets. The code is available at https://github.com/xy-guo/GwcNet
Action Recognition with Joint Attention on Multi-Level Deep Features
Jul 09, 2016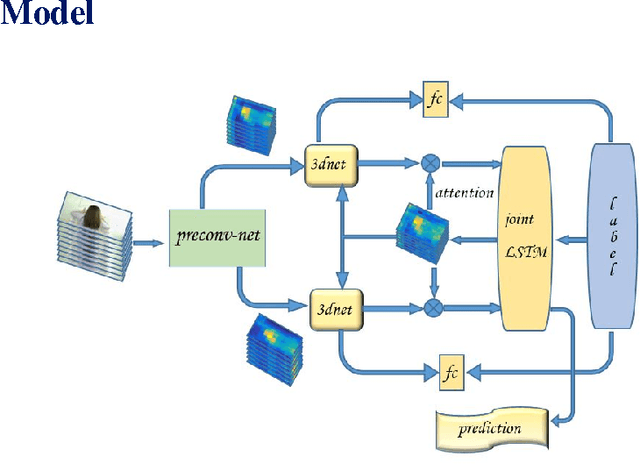
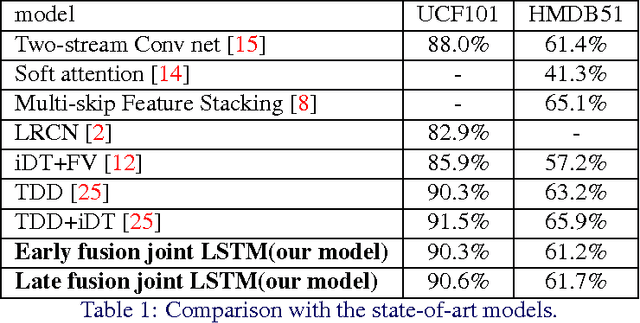

We propose a novel deep supervised neural network for the task of action recognition in videos, which implicitly takes advantage of visual tracking and shares the robustness of both deep Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN). In our method, a multi-branch model is proposed to suppress noise from background jitters. Specifically, we firstly extract multi-level deep features from deep CNNs and feed them into 3d-convolutional network. After that we feed those feature cubes into our novel joint LSTM module to predict labels and to generate attention regularization. We evaluate our model on two challenging datasets: UCF101 and HMDB51. The results show that our model achieves the state-of-art by only using convolutional features.