 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiang Zhu
Feature Re-Embedding: Towards Foundation Model-Level Performance in Computational Pathology
Feb 27, 2024
Multiple instance learning (MIL) is the most widely used framework in computational pathology, encompassing sub-typing, diagnosis, prognosis, and more. However, the existing MIL paradigm typically requires an offline instance feature extractor, such as a pre-trained ResNet or a foundation model. This approach lacks the capability for feature fine-tuning within the specific downstream tasks, limiting its adaptability and performance. To address this issue, we propose a Re-embedded Regional Transformer (R$^2$T) for re-embedding the instance features online, which captures fine-grained local features and establishes connections across different regions. Unlike existing works that focus on pre-training powerful feature extractor or designing sophisticated instance aggregator, R$^2$T is tailored to re-embed instance features online. It serves as a portable module that can seamlessly integrate into mainstream MIL models. Extensive experimental results on common computational pathology tasks validate that: 1) feature re-embedding improves the performance of MIL models based on ResNet-50 features to the level of foundation model features, and further enhances the performance of foundation model features; 2) the R$^2$T can introduce more significant performance improvements to various MIL models; 3) R$^2$T-MIL, as an R$^2$T-enhanced AB-MIL, outperforms other latest methods by a large margin. The code is available at:~\href{https://github.com/DearCaat/RRT-MIL}{https://github.com/DearCaat/RRT-MIL}.
Stylized Table Tennis Robots Skill Learning with Incomplete Human Demonstrations
Sep 16, 2023In recent years, Reinforcement Learning (RL) is becoming a popular technique for training controllers for robots. However, for complex dynamic robot control tasks, RL-based method often produces controllers with unrealistic styles. In contrast, humans can learn well-stylized skills under supervisions. For example, people learn table tennis skills by imitating the motions of coaches. Such reference motions are often incomplete, e.g. without the presence of an actual ball. Inspired by this, we propose an RL-based algorithm to train a robot that can learn the playing style from such incomplete human demonstrations. We collect data through the teaching-and-dragging method. We also propose data augmentation techniques to enable our robot to adapt to balls of different velocities. We finally evaluate our policy in different simulators with varying dynamics.
Incorporating Domain Knowledge through Task Augmentation for Front-End JavaScript Code Generation
Aug 23, 2022

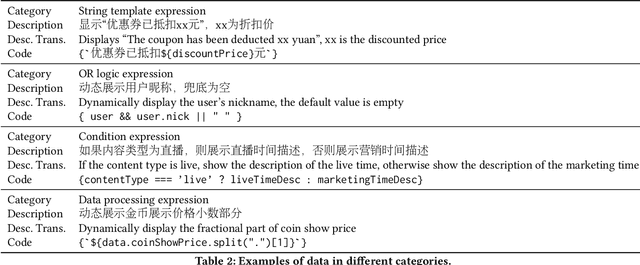

Code generation aims to generate a code snippet automatically from natural language descriptions. Generally, the mainstream code generation methods rely on a large amount of paired training data, including both the natural language description and the code. However, in some domain-specific scenarios, building such a large paired corpus for code generation is difficult because there is no directly available pairing data, and a lot of effort is required to manually write the code descriptions to construct a high-quality training dataset. Due to the limited training data, the generation model cannot be well trained and is likely to be overfitting, making the model's performance unsatisfactory for real-world use. To this end, in this paper, we propose a task augmentation method that incorporates domain knowledge into code generation models through auxiliary tasks and a Subtoken-TranX model by extending the original TranX model to support subtoken-level code generation. To verify our proposed approach, we collect a real-world code generation dataset and conduct experiments on it. Our experimental results demonstrate that the subtoken-level TranX model outperforms the original TranX model and the Transformer model on our dataset, and the exact match accuracy of Subtoken-TranX improves significantly by 12.75% with the help of our task augmentation method. The model performance on several code categories has satisfied the requirements for application in industrial systems. Our proposed approach has been adopted by Alibaba's BizCook platform. To the best of our knowledge, this is the first domain code generation system adopted in industrial development environments.
A Contact-Safe Reinforcement Learning Framework for Contact-Rich Robot Manipulation
Jul 27, 2022
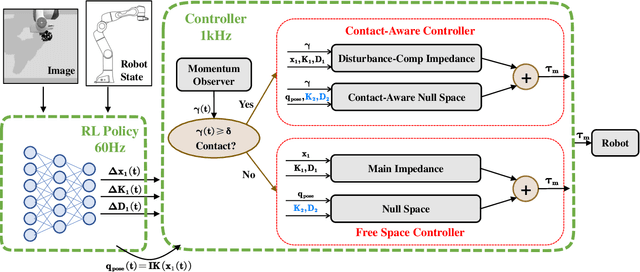
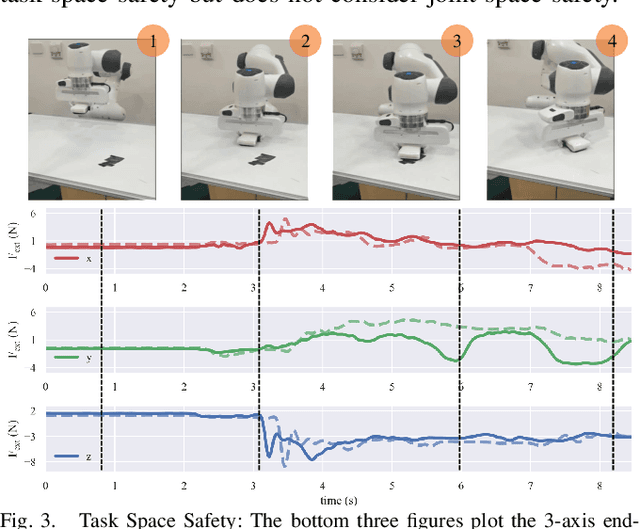
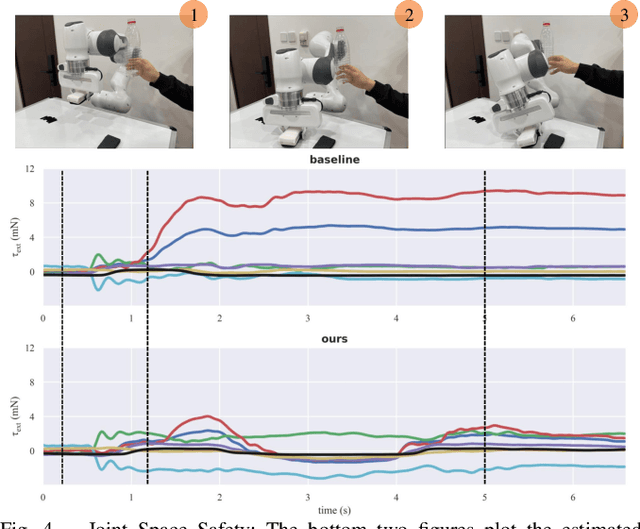
Reinforcement learning shows great potential to solve complex contact-rich robot manipulation tasks. However, the safety of using RL in the real world is a crucial problem, since unexpected dangerous collisions might happen when the RL policy is imperfect during training or in unseen scenarios. In this paper, we propose a contact-safe reinforcement learning framework for contact-rich robot manipulation, which maintains safety in both the task space and joint space. When the RL policy causes unexpected collisions between the robot arm and the environment, our framework is able to immediately detect the collision and ensure the contact force to be small. Furthermore, the end-effector is enforced to perform contact-rich tasks compliantly, while keeping robust to external disturbances. We train the RL policy in simulation and transfer it to the real robot. Real world experiments on robot wiping tasks show that our method is able to keep the contact force small both in task space and joint space even when the policy is under unseen scenario with unexpected collision, while rejecting the disturbances on the main task.
Super-Resolving Commercial Satellite Imagery Using Realistic Training Data
Feb 26, 2020



In machine learning based single image super-resolution, the degradation model is embedded in training data generation. However, most existing satellite image super-resolution methods use a simple down-sampling model with a fixed kernel to create training images. These methods work fine on synthetic data, but do not perform well on real satellite images. We propose a realistic training data generation model for commercial satellite imagery products, which includes not only the imaging process on satellites but also the post-process on the ground. We also propose a convolutional neural network optimized for satellite images. Experiments show that the proposed training data generation model is able to improve super-resolution performance on real satellite images.