 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiangdi Meng
PeriodicLoRA: Breaking the Low-Rank Bottleneck in LoRA Optimization
Feb 25, 2024
Supervised fine-tuning is the most common method to adapt large language models (LLMs) to downstream tasks, but full fine-tuning LLMs requires massive computational resources. Recently, parameter-efficient fine-tuning (PEFT) methods have been widely studied due to its cost-effectiveness. LoRA is one of the most widely used methods, which assumes that the optimization process is essentially low-dimensional. Although LoRA fine-tuning is effective, there is still a performance gap compared to full fine-tuning, since its weight update is limited to low-rank matrices. In order to break the low-rank bottleneck in LoRA Optimization, we propose PeriodicLoRA (PLoRA), which accumulates low-rank update matrices multiple times to achieve a higher update rank. PLoRA has multiple training stages. During each stage, we still update only the LoRA weights. However, at the end of each stage, we unload the LoRA weights into the backbone parameters and then reinitialize the LoRA states. Experimental results show that PLoRA has stronger learning ability, approximately 1.8 times that of LoRA's learning ability at most, but it does not increase memory usage. Further, we introduce a momentum-based unloading strategy for PLoRA to mitigate the training instability.
PCA-Bench: Evaluating Multimodal Large Language Models in Perception-Cognition-Action Chain
Feb 21, 2024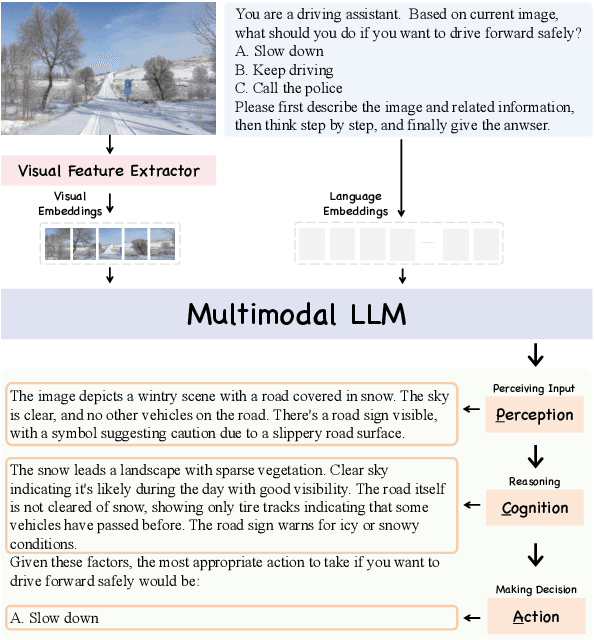



We present PCA-Bench, a multimodal decision-making benchmark for evaluating the integrated capabilities of Multimodal Large Language Models (MLLMs). Departing from previous benchmarks focusing on simplistic tasks and individual model capability, PCA-Bench introduces three complex scenarios: autonomous driving, domestic robotics, and open-world games. Given task instructions and diverse contexts, the model is required to seamlessly integrate multiple capabilities of Perception, Cognition, and Action in a reasoning chain to make accurate decisions. Moreover, PCA-Bench features error localization capabilities, scrutinizing model inaccuracies in areas such as perception, knowledge, or reasoning. This enhances the reliability of deploying MLLMs. To balance accuracy and efficiency in evaluation, we propose PCA-Eval, an automatic evaluation protocol, and assess 10 prevalent MLLMs. The results reveal significant performance disparities between open-source models and powerful proprietary models like GPT-4 Vision. To address this, we introduce Embodied-Instruction-Evolution (EIE), an automatic framework for synthesizing instruction tuning examples in multimodal embodied environments. EIE generates 7,510 training examples in PCA-Bench and enhances the performance of open-source MLLMs, occasionally surpassing GPT-4 Vision (+3\% in decision accuracy), thereby validating the effectiveness of EIE. Our findings suggest that robust MLLMs like GPT4-Vision show promise for decision-making in embodied agents, opening new avenues for MLLM research.