 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiao-Jun Zeng
Enhancing Cooperation through Selective Interaction and Long-term Experiences in Multi-Agent Reinforcement Learning
May 04, 2024
The significance of network structures in promoting group cooperation within social dilemmas has been widely recognized. Prior studies attribute this facilitation to the assortment of strategies driven by spatial interactions. Although reinforcement learning has been employed to investigate the impact of dynamic interaction on the evolution of cooperation, there remains a lack of understanding about how agents develop neighbour selection behaviours and the formation of strategic assortment within an explicit interaction structure. To address this, our study introduces a computational framework based on multi-agent reinforcement learning in the spatial Prisoner's Dilemma game. This framework allows agents to select dilemma strategies and interacting neighbours based on their long-term experiences, differing from existing research that relies on preset social norms or external incentives. By modelling each agent using two distinct Q-networks, we disentangle the coevolutionary dynamics between cooperation and interaction. The results indicate that long-term experience enables agents to develop the ability to identify non-cooperative neighbours and exhibit a preference for interaction with cooperative ones. This emergent self-organizing behaviour leads to the clustering of agents with similar strategies, thereby increasing network reciprocity and enhancing group cooperation.
Mapping-to-Parameter Nonlinear Functional Regression with Novel B-spline Free Knot Placement Algorithm
Jan 26, 2024We propose a novel approach to nonlinear functional regression, called the Mapping-to-Parameter function model, which addresses complex and nonlinear functional regression problems in parameter space by employing any supervised learning technique. Central to this model is the mapping of function data from an infinite-dimensional function space to a finite-dimensional parameter space. This is accomplished by concurrently approximating multiple functions with a common set of B-spline basis functions by any chosen order, with their knot distribution determined by the Iterative Local Placement Algorithm, a newly proposed free knot placement algorithm. In contrast to the conventional equidistant knot placement strategy that uniformly distributes knot locations based on a predefined number of knots, our proposed algorithms determine knot location according to the local complexity of the input or output functions. The performance of our knot placement algorithms is shown to be robust in both single-function approximation and multiple-function approximation contexts. Furthermore, the effectiveness and advantage of the proposed prediction model in handling both function-on-scalar regression and function-on-function regression problems are demonstrated through several real data applications, in comparison with four groups of state-of-the-art methods.
To transfer or not transfer: Unified transferability metric and analysis
May 12, 2023



In transfer learning, transferability is one of the most fundamental problems, which aims to evaluate the effectiveness of arbitrary transfer tasks. Existing research focuses on classification tasks and neglects domain or task differences. More importantly, there is a lack of research to determine whether to transfer or not. To address these, we propose a new analytical approach and metric, Wasserstein Distance based Joint Estimation (WDJE), for transferability estimation and determination in a unified setting: classification and regression problems with domain and task differences. The WDJE facilitates decision-making on whether to transfer or not by comparing the target risk with and without transfer. To enable the comparison, we approximate the target transfer risk by proposing a non-symmetric, easy-to-understand and easy-to-calculate target risk bound that is workable even with limited target labels. The proposed bound relates the target risk to source model performance, domain and task differences based on Wasserstein distance. We also extend our bound into unsupervised settings and establish the generalization bound from finite empirical samples. Our experiments in image classification and remaining useful life regression prediction illustrate the effectiveness of the WDJE in determining whether to transfer or not, and the proposed bound in approximating the target transfer risk.
EDU-level Extractive Summarization with Varying Summary Lengths
Oct 08, 2022



Extractive models usually formulate text summarization as extracting top-k important sentences from document as summary. Few work exploited extracting finer-grained Elementary Discourse Unit (EDU) and there is little analysis and justification for the extractive unit selection. To fill such a gap, this paper firstly conducts oracle analysis to compare the upper bound of performance for models based on EDUs and sentences. The analysis provides evidences from both theoretical and experimental perspectives to justify that EDUs make more concise and precise summary than sentences without losing salient information. Then, considering this merit of EDUs, this paper further proposes EDU-level extractive model with Varying summary Lengths (EDU-VL) and develops the corresponding learning algorithm. EDU-VL learns to encode and predict probabilities of EDUs in document, and encode EDU-level candidate summaries with different lengths based on various $k$ values and select the best candidate summary in an end-to-end training manner. Finally, the proposed and developed approach is experimented on single and multi-document benchmark datasets and shows the improved performances in comparison with the state-of-the-art models.
Towards Better Dermoscopic Image Feature Representation Learning for Melanoma Classification
Jul 15, 2022Deep learning-based melanoma classification with dermoscopic images has recently shown great potential in automatic early-stage melanoma diagnosis. However, limited by the significant data imbalance and obvious extraneous artifacts, i.e., the hair and ruler markings, discriminative feature extraction from dermoscopic images is very challenging. In this study, we seek to resolve these problems respectively towards better representation learning for lesion features. Specifically, a GAN-based data augmentation (GDA) strategy is adapted to generate synthetic melanoma-positive images, in conjunction with the proposed implicit hair denoising (IHD) strategy. Wherein the hair-related representations are implicitly disentangled via an auxiliary classifier network and reversely sent to the melanoma-feature extraction backbone for better melanoma-specific representation learning. Furthermore, to train the IHD module, the hair noises are additionally labeled on the ISIC2020 dataset, making it the first large-scale dermoscopic dataset with annotation of hair-like artifacts. Extensive experiments demonstrate the superiority of the proposed framework as well as the effectiveness of each component. The improved dataset publicly avaliable at https://github.com/kirtsy/DermoscopicDataset.
Group-Agent Reinforcement Learning with A Distributed Deep Solution
Mar 07, 2022



It can largely benefit the reinforcement learning process of each agent if multiple agents perform their separate reinforcement learning tasks cooperatively. These tasks can be not exactly the same but still benefit from the communication behaviour between agents due to task similarities. In fact, this learning scenario is not well understood yet and not well formulated. As the first effort, we provide a detailed discussion of this scenario, and propose group-agent reinforcement learning as a formulation of the reinforcement learning problem under this scenario and a third type of reinforcement learning problem with respect to single-agent and multi-agent reinforcement learning. We propose that it can be solved with the help of modern deep reinforcement learning techniques and provide a distributed deep reinforcement learning algorithm called DDA3C (Decentralised Distributed Asynchronous Advantage Actor-Critic) that is the first framework designed for group-agent reinforcement learning. We show through experiments in the CartPole-v0 game environment that DDA3C achieved desirable performance with very stable training and has good scalability.
Multiple Dynamic Pricing for Demand Response with Adaptive Clustering-based Customer Segmentation in Smart Grids
Jun 10, 2021


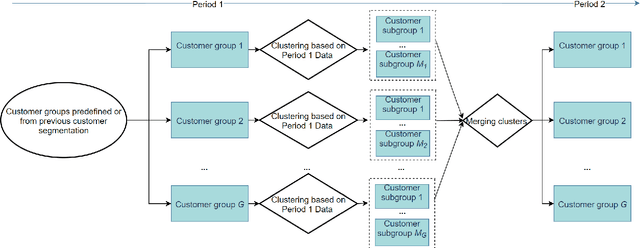
In this paper, we propose a realistic multiple dynamic pricing approach to demand response in the retail market. First, an adaptive clustering-based customer segmentation framework is proposed to categorize customers into different groups to enable the effective identification of usage patterns. Second, customized demand models with important market constraints which capture the price-demand relationship explicitly, are developed for each group of customers to improve the model accuracy and enable meaningful pricing. Third, the multiple pricing based demand response is formulated as a profit maximization problem subject to realistic market constraints. The overall aim of the proposed scalable and practical method aims to achieve 'right' prices for 'right' customers so as to benefit various stakeholders in the system such as grid operators, customers and retailers. The proposed multiple pricing framework is evaluated via simulations based on real-world datasets.
UPANets: Learning from the Universal Pixel Attention Networks
Mar 22, 2021



Among image classification, skip and densely-connection-based networks have dominated most leaderboards. Recently, from the successful development of multi-head attention in natural language processing, it is sure that now is a time of either using a Transformer-like model or hybrid CNNs with attention. However, the former need a tremendous resource to train, and the latter is in the perfect balance in this direction. In this work, to make CNNs handle global and local information, we proposed UPANets, which equips channel-wise attention with a hybrid skip-densely-connection structure. Also, the extreme-connection structure makes UPANets robust with a smoother loss landscape. In experiments, UPANets surpassed most well-known and widely-used SOTAs with an accuracy of 96.47% in Cifar-10, 80.29% in Cifar-100, and 67.67% in Tiny Imagenet. Most importantly, these performances have high parameters efficiency and only trained in one customer-based GPU. We share implementing code of UPANets in https://github.com/hanktseng131415go/UPANets.
An Integrated Optimization + Learning Approach to Optimal Dynamic Pricing for the Retailer with Multi-type Customers in Smart Grids
Mar 21, 2018



In this paper, we consider a realistic and meaningful scenario in the context of smart grids where an electricity retailer serves three different types of customers, i.e., customers with an optimal home energy management system embedded in their smart meters (C-HEMS), customers with only smart meters (C-SM), and customers without smart meters (C-NONE). The main objective of this paper is to support the retailer to make optimal day-ahead dynamic pricing decisions in such a mixed customer pool. To this end, we propose a two-level decision-making framework where the retailer acting as upper-level agent firstly announces its electricity prices of next 24 hours and customers acting as lower-level agents subsequently schedule their energy usages accordingly. For the lower level problem, we model the price responsiveness of different customers according to their unique characteristics. For the upper level problem, we optimize the dynamic prices for the retailer to maximize its profit subject to realistic market constraints. The above two-level model is tackled by genetic algorithms (GA) based distributed optimization methods while its feasibility and effectiveness are confirmed via simulation results.
Twitter mood predicts the stock market
Oct 14, 2010



Behavioral economics tells us that emotions can profoundly affect individual behavior and decision-making. Does this also apply to societies at large, i.e., can societies experience mood states that affect their collective decision making? By extension is the public mood correlated or even predictive of economic indicators? Here we investigate whether measurements of collective mood states derived from large-scale Twitter feeds are correlated to the value of the Dow Jones Industrial Average (DJIA) over time. We analyze the text content of daily Twitter feeds by two mood tracking tools, namely OpinionFinder that measures positive vs. negative mood and Google-Profile of Mood States (GPOMS) that measures mood in terms of 6 dimensions (Calm, Alert, Sure, Vital, Kind, and Happy). We cross-validate the resulting mood time series by comparing their ability to detect the public's response to the presidential election and Thanksgiving day in 2008. A Granger causality analysis and a Self-Organizing Fuzzy Neural Network are then used to investigate the hypothesis that public mood states, as measured by the OpinionFinder and GPOMS mood time series, are predictive of changes in DJIA closing values. Our results indicate that the accuracy of DJIA predictions can be significantly improved by the inclusion of specific public mood dimensions but not others. We find an accuracy of 87.6% in predicting the daily up and down changes in the closing values of the DJIA and a reduction of the Mean Average Percentage Error by more than 6%.