 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaohao Liu
rFaceNet: An End-to-End Network for Enhanced Physiological Signal Extraction through Identity-Specific Facial Contours
Mar 17, 2024
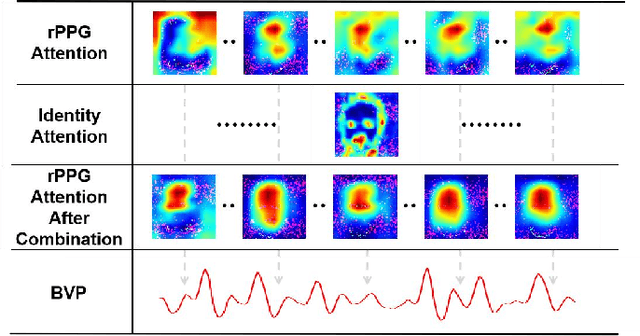
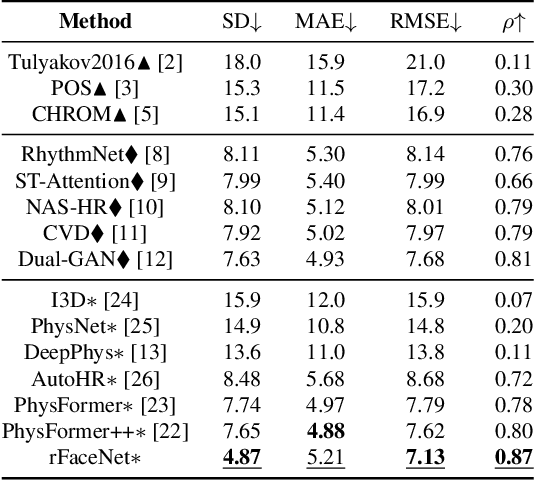
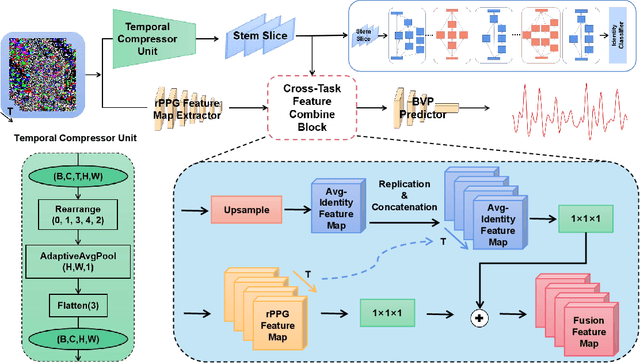
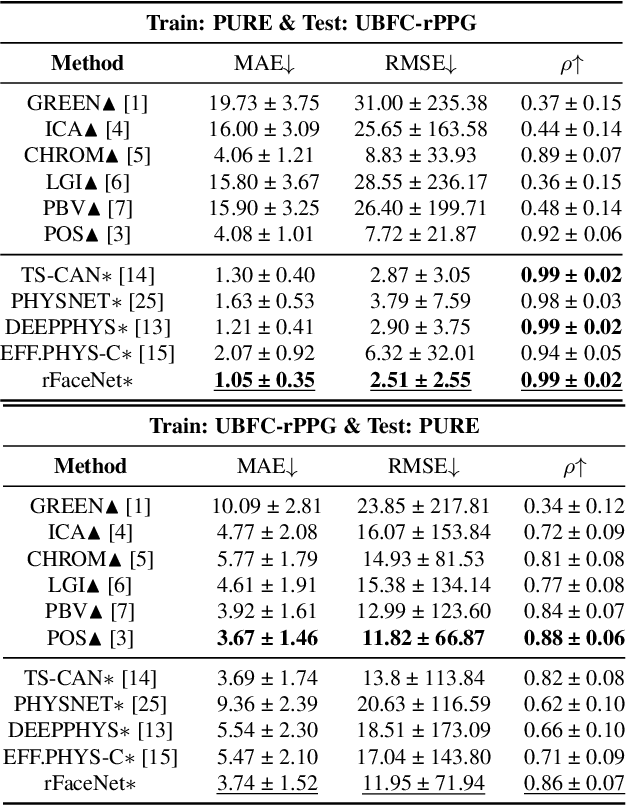
Remote photoplethysmography (rPPG) technique extracts blood volume pulse (BVP) signals from subtle pixel changes in video frames. This study introduces rFaceNet, an advanced rPPG method that enhances the extraction of facial BVP signals with a focus on facial contours. rFaceNet integrates identity-specific facial contour information and eliminates redundant data. It efficiently extracts facial contours from temporally normalized frame inputs through a Temporal Compressor Unit (TCU) and steers the model focus to relevant facial regions by using the Cross-Task Feature Combiner (CTFC). Through elaborate training, the quality and interpretability of facial physiological signals extracted by rFaceNet are greatly improved compared to previous methods. Moreover, our novel approach demonstrates superior performance than SOTA methods in various heart rate estimation benchmarks.
Leveraging Multimodal Features and Item-level User Feedback for Bundle Construction
Oct 28, 2023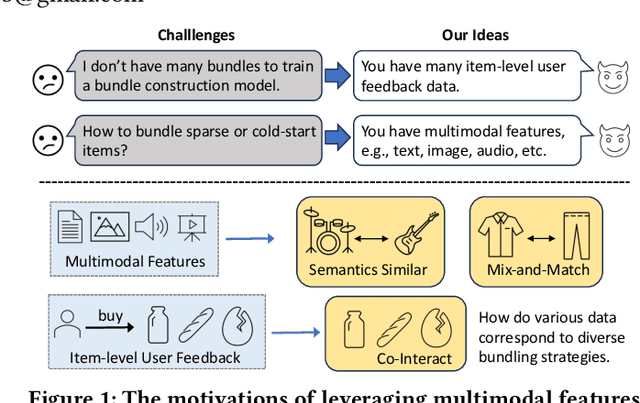

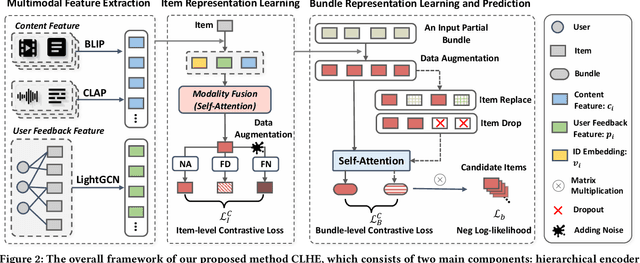
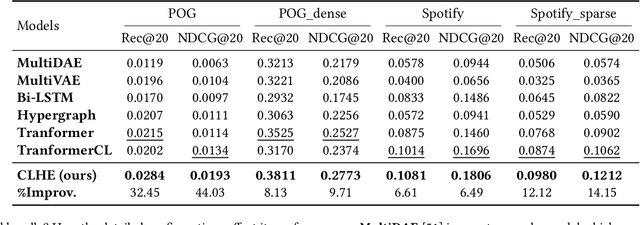
Automatic bundle construction is a crucial prerequisite step in various bundle-aware online services. Previous approaches are mostly designed to model the bundling strategy of existing bundles. However, it is hard to acquire large-scale well-curated bundle dataset, especially for those platforms that have not offered bundle services before. Even for platforms with mature bundle services, there are still many items that are included in few or even zero bundles, which give rise to sparsity and cold-start challenges in the bundle construction models. To tackle these issues, we target at leveraging multimodal features, item-level user feedback signals, and the bundle composition information, to achieve a comprehensive formulation of bundle construction. Nevertheless, such formulation poses two new technical challenges: 1) how to learn effective representations by optimally unifying multiple features, and 2) how to address the problems of modality missing, noise, and sparsity problems induced by the incomplete query bundles. In this work, to address these technical challenges, we propose a Contrastive Learning-enhanced Hierarchical Encoder method (CLHE). Specifically, we use self-attention modules to combine the multimodal and multi-item features, and then leverage both item- and bundle-level contrastive learning to enhance the representation learning, thus to counter the modality missing, noise, and sparsity problems. Extensive experiments on four datasets in two application domains demonstrate that our method outperforms a list of SOTA methods. The code and dataset are available at https://github.com/Xiaohao-Liu/CLHE.