 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhulin Tao
Leveraging Multimodal Features and Item-level User Feedback for Bundle Construction
Oct 28, 2023
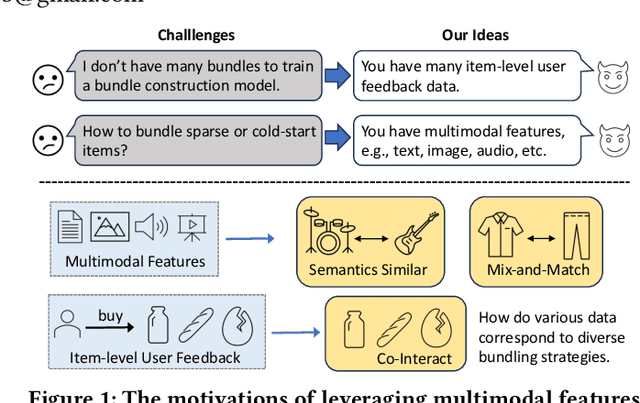

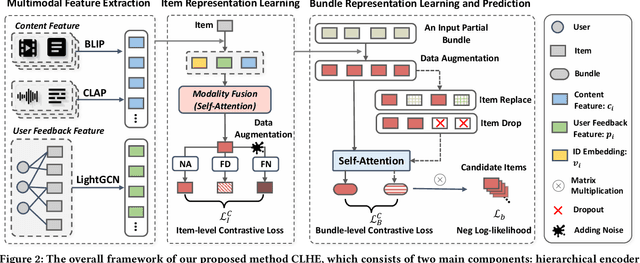
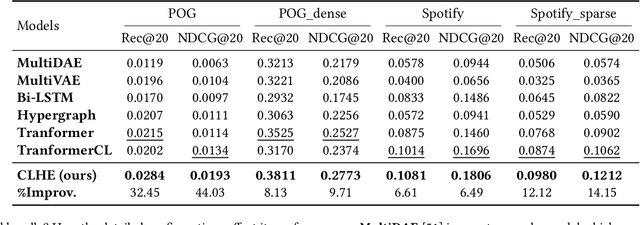
Automatic bundle construction is a crucial prerequisite step in various bundle-aware online services. Previous approaches are mostly designed to model the bundling strategy of existing bundles. However, it is hard to acquire large-scale well-curated bundle dataset, especially for those platforms that have not offered bundle services before. Even for platforms with mature bundle services, there are still many items that are included in few or even zero bundles, which give rise to sparsity and cold-start challenges in the bundle construction models. To tackle these issues, we target at leveraging multimodal features, item-level user feedback signals, and the bundle composition information, to achieve a comprehensive formulation of bundle construction. Nevertheless, such formulation poses two new technical challenges: 1) how to learn effective representations by optimally unifying multiple features, and 2) how to address the problems of modality missing, noise, and sparsity problems induced by the incomplete query bundles. In this work, to address these technical challenges, we propose a Contrastive Learning-enhanced Hierarchical Encoder method (CLHE). Specifically, we use self-attention modules to combine the multimodal and multi-item features, and then leverage both item- and bundle-level contrastive learning to enhance the representation learning, thus to counter the modality missing, noise, and sparsity problems. Extensive experiments on four datasets in two application domains demonstrate that our method outperforms a list of SOTA methods. The code and dataset are available at https://github.com/Xiaohao-Liu/CLHE.
INO at Factify 2: Structure Coherence based Multi-Modal Fact Verification
Mar 02, 2023



This paper describes our approach to the multi-modal fact verification (FACTIFY) challenge at AAAI2023. In recent years, with the widespread use of social media, fake news can spread rapidly and negatively impact social security. Automatic claim verification becomes more and more crucial to combat fake news. In fact verification involving multiple modal data, there should be a structural coherence between claim and document. Therefore, we proposed a structure coherence-based multi-modal fact verification scheme to classify fake news. Our structure coherence includes the following four aspects: sentence length, vocabulary similarity, semantic similarity, and image similarity. Specifically, CLIP and Sentence BERT are combined to extract text features, and ResNet50 is used to extract image features. In addition, we also extract the length of the text as well as the lexical similarity. Then the features were concatenated and passed through the random forest classifier. Finally, our weighted average F1 score has reached 0.8079, achieving 2nd place in FACTIFY2.
BiSTNet: Semantic Image Prior Guided Bidirectional Temporal Feature Fusion for Deep Exemplar-based Video Colorization
Dec 05, 2022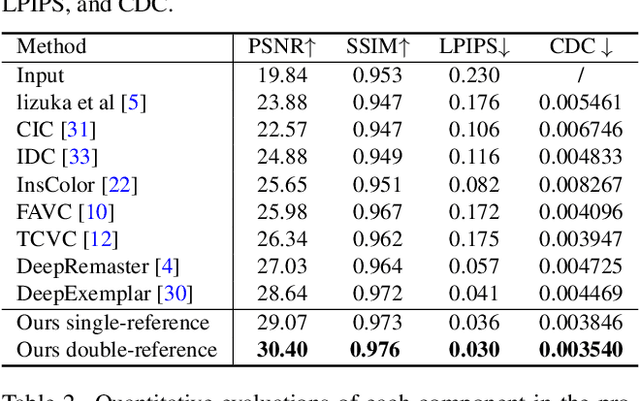
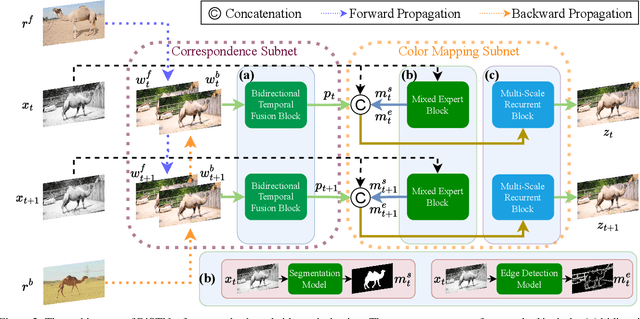
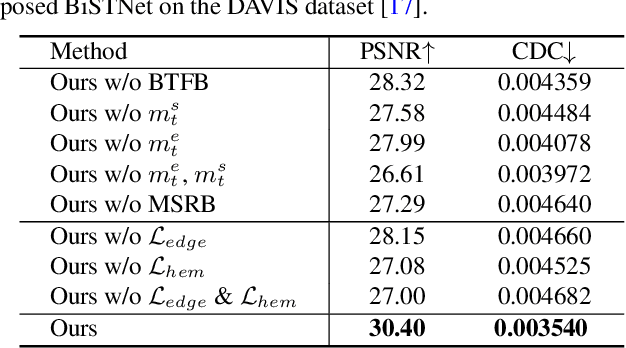

How to effectively explore the colors of reference exemplars and propagate them to colorize each frame is vital for exemplar-based video colorization. In this paper, we present an effective BiSTNet to explore colors of reference exemplars and utilize them to help video colorization by a bidirectional temporal feature fusion with the guidance of semantic image prior. We first establish the semantic correspondence between each frame and the reference exemplars in deep feature space to explore color information from reference exemplars. Then, to better propagate the colors of reference exemplars into each frame and avoid the inaccurate matches colors from exemplars we develop a simple yet effective bidirectional temporal feature fusion module to better colorize each frame. We note that there usually exist color-bleeding artifacts around the boundaries of the important objects in videos. To overcome this problem, we further develop a mixed expert block to extract semantic information for modeling the object boundaries of frames so that the semantic image prior can better guide the colorization process for better performance. In addition, we develop a multi-scale recurrent block to progressively colorize frames in a coarse-to-fine manner. Extensive experimental results demonstrate that the proposed BiSTNet performs favorably against state-of-the-art methods on the benchmark datasets. Our code will be made available at \url{https://yyang181.github.io/BiSTNet/}