 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoqian Shen
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
Apr 04, 2024
This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
Large Language Models as Consistent Story Visualizers
Dec 04, 2023



Recent generative models have demonstrated impressive capabilities in generating realistic and visually pleasing images grounded on textual prompts. Nevertheless, a significant challenge remains in applying these models for the more intricate task of story visualization. Since it requires resolving pronouns (he, she, they) in the frame descriptions, i.e., anaphora resolution, and ensuring consistent characters and background synthesis across frames. Yet, the emerging Large Language Model (LLM) showcases robust reasoning abilities to navigate through ambiguous references and process extensive sequences. Therefore, we introduce \textbf{StoryGPT-V}, which leverages the merits of the latent diffusion (LDM) and LLM to produce images with consistent and high-quality characters grounded on given story descriptions. First, we train a character-aware LDM, which takes character-augmented semantic embedding as input and includes the supervision of the cross-attention map using character segmentation masks, aiming to enhance character generation accuracy and faithfulness. In the second stage, we enable an alignment between the output of LLM and the character-augmented embedding residing in the input space of the first-stage model. This harnesses the reasoning ability of LLM to address ambiguous references and the comprehension capability to memorize the context. We conduct comprehensive experiments on two visual story visualization benchmarks. Our model reports superior quantitative results and consistently generates accurate characters of remarkable quality with low memory consumption. Our code will be made publicly available.
MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
Oct 26, 2023Large language models have shown their remarkable capabilities as a general interface for various language-related applications. Motivated by this, we target to build a unified interface for completing many vision-language tasks including image description, visual question answering, and visual grounding, among others. The challenge is to use a single model for performing diverse vision-language tasks effectively with simple multi-modal instructions. Towards this objective, we introduce MiniGPT-v2, a model that can be treated as a unified interface for better handling various vision-language tasks. We propose using unique identifiers for different tasks when training the model. These identifiers enable our model to better distinguish each task instruction effortlessly and also improve the model learning efficiency for each task. After the three-stage training, the experimental results show that MiniGPT-v2 achieves strong performance on many visual question-answering and visual grounding benchmarks compared to other vision-language generalist models. Our model and codes are available at https://minigpt-v2.github.io/
Affective Visual Dialog: A Large-Scale Benchmark for Emotional Reasoning Based on Visually Grounded Conversations
Sep 12, 2023We introduce Affective Visual Dialog, an emotion explanation and reasoning task as a testbed for research on understanding the formation of emotions in visually grounded conversations. The task involves three skills: (1) Dialog-based Question Answering (2) Dialog-based Emotion Prediction and (3) Affective emotion explanation generation based on the dialog. Our key contribution is the collection of a large-scale dataset, dubbed AffectVisDial, consisting of 50K 10-turn visually grounded dialogs as well as concluding emotion attributions and dialog-informed textual emotion explanations, resulting in a total of 27,180 working hours. We explain our design decisions in collecting the dataset and introduce the questioner and answerer tasks that are associated with the participants in the conversation. We train and demonstrate solid Affective Visual Dialog baselines adapted from state-of-the-art models. Remarkably, the responses generated by our models show promising emotional reasoning abilities in response to visually grounded conversations. Our project page is available at https://affective-visual-dialog.github.io.
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Apr 20, 2023



The recent GPT-4 has demonstrated extraordinary multi-modal abilities, such as directly generating websites from handwritten text and identifying humorous elements within images. These features are rarely observed in previous vision-language models. We believe the primary reason for GPT-4's advanced multi-modal generation capabilities lies in the utilization of a more advanced large language model (LLM). To examine this phenomenon, we present MiniGPT-4, which aligns a frozen visual encoder with a frozen LLM, Vicuna, using just one projection layer. Our findings reveal that MiniGPT-4 possesses many capabilities similar to those exhibited by GPT-4 like detailed image description generation and website creation from hand-written drafts. Furthermore, we also observe other emerging capabilities in MiniGPT-4, including writing stories and poems inspired by given images, providing solutions to problems shown in images, teaching users how to cook based on food photos, etc. In our experiment, we found that only performing the pretraining on raw image-text pairs could produce unnatural language outputs that lack coherency including repetition and fragmented sentences. To address this problem, we curate a high-quality, well-aligned dataset in the second stage to finetune our model using a conversational template. This step proved crucial for augmenting the model's generation reliability and overall usability. Notably, our model is highly computationally efficient, as we only train a projection layer utilizing approximately 5 million aligned image-text pairs. Our code, pre-trained model, and collected dataset are available at https://minigpt-4.github.io/.
HRS-Bench: Holistic, Reliable and Scalable Benchmark for Text-to-Image Models
Apr 11, 2023



In recent years, Text-to-Image (T2I) models have been extensively studied, especially with the emergence of diffusion models that achieve state-of-the-art results on T2I synthesis tasks. However, existing benchmarks heavily rely on subjective human evaluation, limiting their ability to holistically assess the model's capabilities. Furthermore, there is a significant gap between efforts in developing new T2I architectures and those in evaluation. To address this, we introduce HRS-Bench, a concrete evaluation benchmark for T2I models that is Holistic, Reliable, and Scalable. Unlike existing bench-marks that focus on limited aspects, HRS-Bench measures 13 skills that can be categorized into five major categories: accuracy, robustness, generalization, fairness, and bias. In addition, HRS-Bench covers 50 scenarios, including fashion, animals, transportation, food, and clothes. We evaluate nine recent large-scale T2I models using metrics that cover a wide range of skills. A human evaluation aligned with 95% of our evaluations on average was conducted to probe the effectiveness of HRS-Bench. Our experiments demonstrate that existing models often struggle to generate images with the desired count of objects, visual text, or grounded emotions. We hope that our benchmark help ease future text-to-image generation research. The code and data are available at https://eslambakr.github.io/hrsbench.github.io
MoStGAN-V: Video Generation with Temporal Motion Styles
Apr 05, 2023



Video generation remains a challenging task due to spatiotemporal complexity and the requirement of synthesizing diverse motions with temporal consistency. Previous works attempt to generate videos in arbitrary lengths either in an autoregressive manner or regarding time as a continuous signal. However, they struggle to synthesize detailed and diverse motions with temporal coherence and tend to generate repetitive scenes after a few time steps. In this work, we argue that a single time-agnostic latent vector of style-based generator is insufficient to model various and temporally-consistent motions. Hence, we introduce additional time-dependent motion styles to model diverse motion patterns. In addition, a Motion Style Attention modulation mechanism, dubbed as MoStAtt, is proposed to augment frames with vivid dynamics for each specific scale (i.e., layer), which assigns attention score for each motion style w.r.t deconvolution filter weights in the target synthesis layer and softly attends different motion styles for weight modulation. Experimental results show our model achieves state-of-the-art performance on four unconditional $256^2$ video synthesis benchmarks trained with only 3 frames per clip and produces better qualitative results with respect to dynamic motions. Code and videos have been made available at https://github.com/xiaoqian-shen/MoStGAN-V.
ChatGPT Asks, BLIP-2 Answers: Automatic Questioning Towards Enriched Visual Descriptions
Mar 12, 2023



Asking insightful questions is crucial for acquiring knowledge and expanding our understanding of the world. However, the importance of questioning has been largely overlooked in AI research, where models have been primarily developed to answer questions. With the recent advancements of large language models (LLMs) like ChatGPT, we discover their capability to ask high-quality questions when provided with a suitable prompt. This discovery presents a new opportunity to develop an automatic questioning system. In this paper, we introduce ChatCaptioner, a novel automatic-questioning method deployed in image captioning. Here, ChatGPT is prompted to ask a series of informative questions about images to BLIP-2, a strong vision question-answering model. By keeping acquiring new visual information from BLIP-2's answers, ChatCaptioner is able to generate more enriched image descriptions. We conduct human-subject evaluations on common image caption datasets such as COCO, Conceptual Caption, and WikiArt, and compare ChatCaptioner with BLIP-2 as well as ground truth. Our results demonstrate that ChatCaptioner's captions are significantly more informative, receiving three times as many votes from human evaluators for providing the most image information. Besides, ChatCaptioner identifies 53% more objects within the image than BLIP-2 alone measured by WordNet synset matching. Code is available at https://github.com/Vision-CAIR/ChatCaptioner
Exploring Hierarchical Graph Representation for Large-Scale Zero-Shot Image Classification
Mar 02, 2022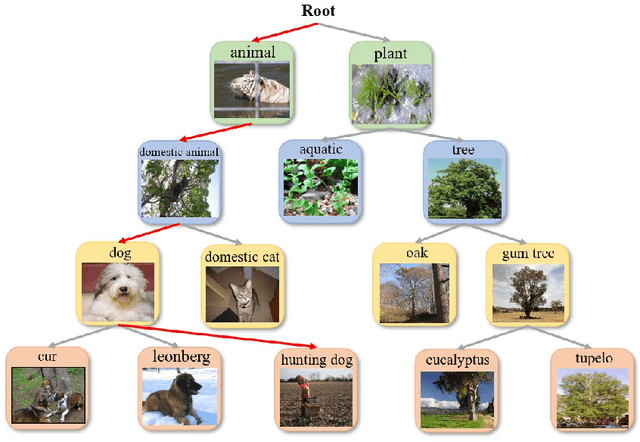
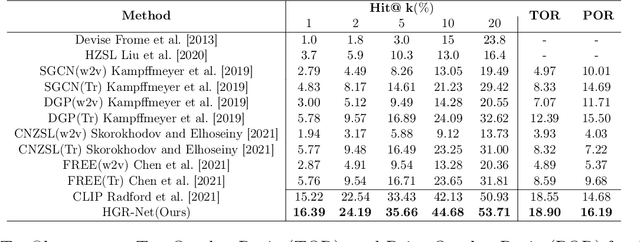

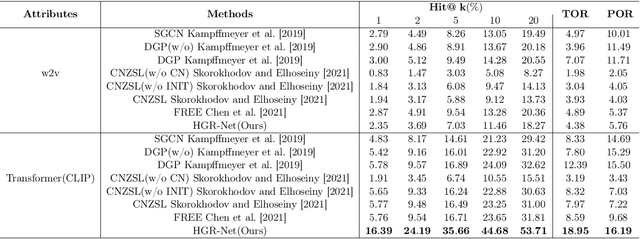
The main question we address in this paper is how to scale up visual recognition of unseen classes, also known as zero-shot learning, to tens of thousands of categories as in the ImageNet-21K benchmark. At this scale, especially with many fine-grained categories included in ImageNet-21K, it is critical to learn quality visual semantic representations that are discriminative enough to recognize unseen classes and distinguish them from seen ones. We propose a Hierarchical Graphical knowledge Representation framework for the confidence-based classification method, dubbed as HGR-Net. Our experimental results demonstrate that HGR-Net can grasp class inheritance relations by utilizing hierarchical conceptual knowledge. Our method significantly outperformed all existing techniques, boosting the performance 7% compared to the runner-up approach on the ImageNet-21K benchmark. We show that HGR-Net is learning-efficient in few-shot scenarios. We also analyzed our method on smaller datasets like ImageNet-21K-P, 2-hops and 3-hops, demonstrating its generalization ability. Our benchmark and code will be made publicly available.