 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMohamed Elhoseiny
Continual Learning on a Diet: Learning from Sparsely Labeled Streams Under Constrained Computation
Apr 19, 2024

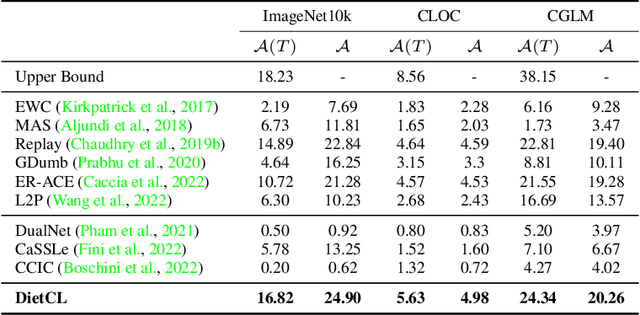


We propose and study a realistic Continual Learning (CL) setting where learning algorithms are granted a restricted computational budget per time step while training. We apply this setting to large-scale semi-supervised Continual Learning scenarios with sparse label rates. Previous proficient CL methods perform very poorly in this challenging setting. Overfitting to the sparse labeled data and insufficient computational budget are the two main culprits for such a poor performance. Our new setting encourages learning methods to effectively and efficiently utilize the unlabeled data during training. To that end, we propose a simple but highly effective baseline, DietCL, which utilizes both unlabeled and labeled data jointly. DietCL meticulously allocates computational budget for both types of data. We validate our baseline, at scale, on several datasets, e.g., CLOC, ImageNet10K, and CGLM, under constraint budget setups. DietCL outperforms, by a large margin, all existing supervised CL algorithms as well as more recent continual semi-supervised methods. Our extensive analysis and ablations demonstrate that DietCL is stable under a full spectrum of label sparsity, computational budget, and various other ablations.
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
Apr 04, 2024This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
AI Art Neural Constellation: Revealing the Collective and Contrastive State of AI-Generated and Human Art
Feb 04, 2024Discovering the creative potentials of a random signal to various artistic expressions in aesthetic and conceptual richness is a ground for the recent success of generative machine learning as a way of art creation. To understand the new artistic medium better, we conduct a comprehensive analysis to position AI-generated art within the context of human art heritage. Our comparative analysis is based on an extensive dataset, dubbed ``ArtConstellation,'' consisting of annotations about art principles, likability, and emotions for 6,000 WikiArt and 3,200 AI-generated artworks. After training various state-of-the-art generative models, art samples are produced and compared with WikiArt data on the last hidden layer of a deep-CNN trained for style classification. We actively examined the various art principles to interpret the neural representations and used them to drive the comparative knowledge about human and AI-generated art. A key finding in the semantic analysis is that AI-generated artworks are visually related to the principle concepts for modern period art made in 1800-2000. In addition, through Out-Of-Distribution (OOD) and In-Distribution (ID) detection in CLIP space, we find that AI-generated artworks are ID to human art when they depict landscapes and geometric abstract figures, while detected as OOD when the machine art consists of deformed and twisted figures. We observe that machine-generated art is uniquely characterized by incomplete and reduced figuration. Lastly, we conducted a human survey about emotional experience. Color composition and familiar subjects are the key factors of likability and emotions in art appreciation. We propose our whole methodologies and collected dataset as our analytical framework to contrast human and AI-generated art, which we refer to as ``ArtNeuralConstellation''. Code is available at: https://github.com/faixan-khan/ArtNeuralConstellation
Uni3DL: Unified Model for 3D and Language Understanding
Dec 05, 2023

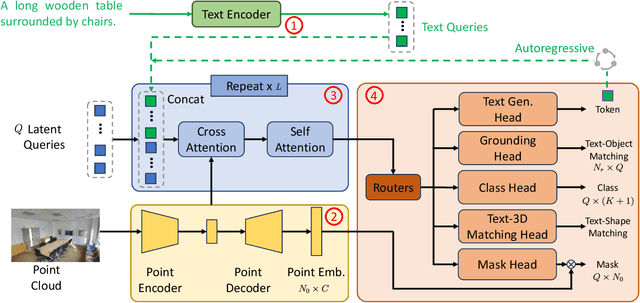
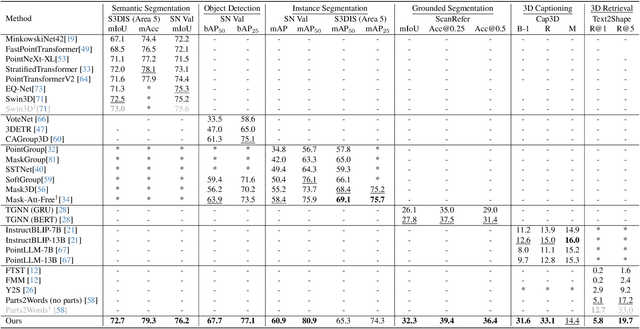
In this work, we present Uni3DL, a unified model for 3D and Language understanding. Distinct from existing unified vision-language models in 3D which are limited in task variety and predominantly dependent on projected multi-view images, Uni3DL operates directly on point clouds. This approach significantly expands the range of supported tasks in 3D, encompassing both vision and vision-language tasks in 3D. At the core of Uni3DL, a query transformer is designed to learn task-agnostic semantic and mask outputs by attending to 3D visual features, and a task router is employed to selectively generate task-specific outputs required for diverse tasks. With a unified architecture, our Uni3DL model enjoys seamless task decomposition and substantial parameter sharing across tasks. Uni3DL has been rigorously evaluated across diverse 3D vision-language understanding tasks, including semantic segmentation, object detection, instance segmentation, visual grounding, 3D captioning, and text-3D cross-modal retrieval. It demonstrates performance on par with or surpassing state-of-the-art (SOTA) task-specific models. We hope our benchmark and Uni3DL model will serve as a solid step to ease future research in unified models in the realm of 3D and language understanding. Project page: https://uni3dl.github.io.
Large Language Models as Consistent Story Visualizers
Dec 04, 2023



Recent generative models have demonstrated impressive capabilities in generating realistic and visually pleasing images grounded on textual prompts. Nevertheless, a significant challenge remains in applying these models for the more intricate task of story visualization. Since it requires resolving pronouns (he, she, they) in the frame descriptions, i.e., anaphora resolution, and ensuring consistent characters and background synthesis across frames. Yet, the emerging Large Language Model (LLM) showcases robust reasoning abilities to navigate through ambiguous references and process extensive sequences. Therefore, we introduce \textbf{StoryGPT-V}, which leverages the merits of the latent diffusion (LDM) and LLM to produce images with consistent and high-quality characters grounded on given story descriptions. First, we train a character-aware LDM, which takes character-augmented semantic embedding as input and includes the supervision of the cross-attention map using character segmentation masks, aiming to enhance character generation accuracy and faithfulness. In the second stage, we enable an alignment between the output of LLM and the character-augmented embedding residing in the input space of the first-stage model. This harnesses the reasoning ability of LLM to address ambiguous references and the comprehension capability to memorize the context. We conduct comprehensive experiments on two visual story visualization benchmarks. Our model reports superior quantitative results and consistently generates accurate characters of remarkable quality with low memory consumption. Our code will be made publicly available.
Label Delay in Continual Learning
Dec 01, 2023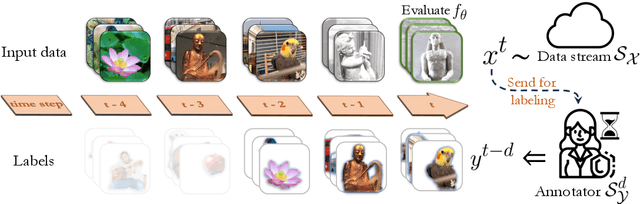
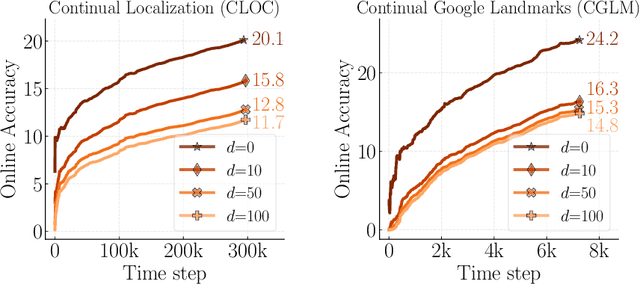
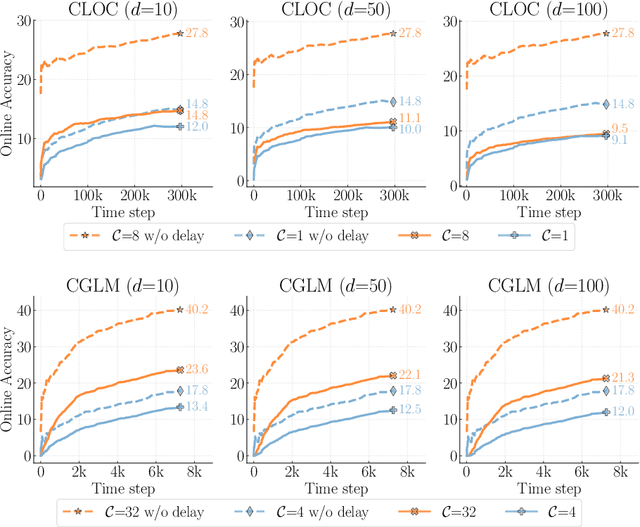
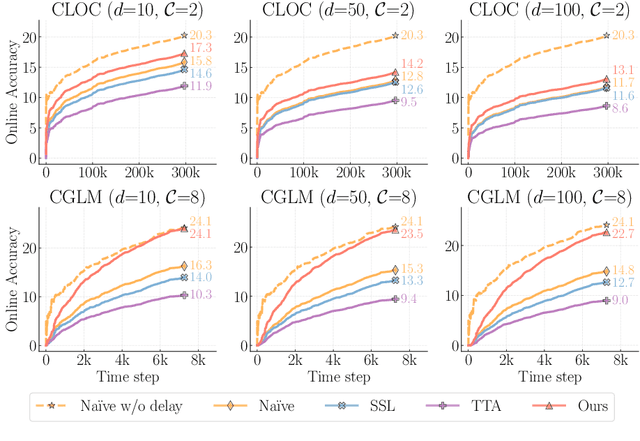
Online continual learning, the process of training models on streaming data, has gained increasing attention in recent years. However, a critical aspect often overlooked is the label delay, where new data may not be labeled due to slow and costly annotation processes. We introduce a new continual learning framework with explicit modeling of the label delay between data and label streams over time steps. In each step, the framework reveals both unlabeled data from the current time step $t$ and labels delayed with $d$ steps, from the time step $t-d$. In our extensive experiments amounting to 1060 GPU days, we show that merely augmenting the computational resources is insufficient to tackle this challenge. Our findings underline a notable performance decline when solely relying on labeled data when the label delay becomes significant. More surprisingly, when using state-of-the-art SSL and TTA techniques to utilize the newer, unlabeled data, they fail to surpass the performance of a na\"ive method that simply trains on the delayed supervised stream. To this end, we introduce a simple, efficient baseline that rehearses from the labeled memory samples that are most similar to the new unlabeled samples. This method bridges the accuracy gap caused by label delay without significantly increasing computational complexity. We show experimentally that our method is the least affected by the label delay factor and in some cases successfully recovers the accuracy of the non-delayed counterpart. We conduct various ablations and sensitivity experiments, demonstrating the effectiveness of our approach.
ToddlerDiffusion: Flash Interpretable Controllable Diffusion Model
Nov 24, 2023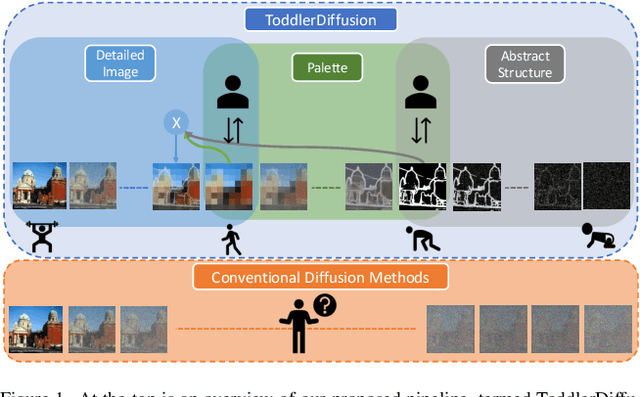



Diffusion-based generative models excel in perceptually impressive synthesis but face challenges in interpretability. This paper introduces ToddlerDiffusion, an interpretable 2D diffusion image-synthesis framework inspired by the human generation system. Unlike traditional diffusion models with opaque denoising steps, our approach decomposes the generation process into simpler, interpretable stages; generating contours, a palette, and a detailed colored image. This not only enhances overall performance but also enables robust editing and interaction capabilities. Each stage is meticulously formulated for efficiency and accuracy, surpassing Stable-Diffusion (LDM). Extensive experiments on datasets like LSUN-Churches and COCO validate our approach, consistently outperforming existing methods. ToddlerDiffusion achieves notable efficiency, matching LDM performance on LSUN-Churches while operating three times faster with a 3.76 times smaller architecture. Our source code is provided in the supplementary material and will be publicly accessible.
A Hybrid Graph Network for Complex Activity Detection in Video
Oct 30, 2023Interpretation and understanding of video presents a challenging computer vision task in numerous fields - e.g. autonomous driving and sports analytics. Existing approaches to interpreting the actions taking place within a video clip are based upon Temporal Action Localisation (TAL), which typically identifies short-term actions. The emerging field of Complex Activity Detection (CompAD) extends this analysis to long-term activities, with a deeper understanding obtained by modelling the internal structure of a complex activity taking place within the video. We address the CompAD problem using a hybrid graph neural network which combines attention applied to a graph encoding the local (short-term) dynamic scene with a temporal graph modelling the overall long-duration activity. Our approach is as follows: i) Firstly, we propose a novel feature extraction technique which, for each video snippet, generates spatiotemporal `tubes' for the active elements (`agents') in the (local) scene by detecting individual objects, tracking them and then extracting 3D features from all the agent tubes as well as the overall scene. ii) Next, we construct a local scene graph where each node (representing either an agent tube or the scene) is connected to all other nodes. Attention is then applied to this graph to obtain an overall representation of the local dynamic scene. iii) Finally, all local scene graph representations are interconnected via a temporal graph, to estimate the complex activity class together with its start and end time. The proposed framework outperforms all previous state-of-the-art methods on all three datasets including ActivityNet-1.3, Thumos-14, and ROAD.
3DCoMPaT$^{++}$: An improved Large-scale 3D Vision Dataset for Compositional Recognition
Oct 27, 2023In this work, we present 3DCoMPaT$^{++}$, a multimodal 2D/3D dataset with 160 million rendered views of more than 10 million stylized 3D shapes carefully annotated at the part-instance level, alongside matching RGB point clouds, 3D textured meshes, depth maps, and segmentation masks. 3DCoMPaT$^{++}$ covers 41 shape categories, 275 fine-grained part categories, and 293 fine-grained material classes that can be compositionally applied to parts of 3D objects. We render a subset of one million stylized shapes from four equally spaced views as well as four randomized views, leading to a total of 160 million renderings. Parts are segmented at the instance level, with coarse-grained and fine-grained semantic levels. We introduce a new task, called Grounded CoMPaT Recognition (GCR), to collectively recognize and ground compositions of materials on parts of 3D objects. Additionally, we report the outcomes of a data challenge organized at CVPR2023, showcasing the winning method's utilization of a modified PointNet$^{++}$ model trained on 6D inputs, and exploring alternative techniques for GCR enhancement. We hope our work will help ease future research on compositional 3D Vision.
MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
Oct 26, 2023Large language models have shown their remarkable capabilities as a general interface for various language-related applications. Motivated by this, we target to build a unified interface for completing many vision-language tasks including image description, visual question answering, and visual grounding, among others. The challenge is to use a single model for performing diverse vision-language tasks effectively with simple multi-modal instructions. Towards this objective, we introduce MiniGPT-v2, a model that can be treated as a unified interface for better handling various vision-language tasks. We propose using unique identifiers for different tasks when training the model. These identifiers enable our model to better distinguish each task instruction effortlessly and also improve the model learning efficiency for each task. After the three-stage training, the experimental results show that MiniGPT-v2 achieves strong performance on many visual question-answering and visual grounding benchmarks compared to other vision-language generalist models. Our model and codes are available at https://minigpt-v2.github.io/