 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoxuan Liu
Mélange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity
Apr 22, 2024
Large language models (LLMs) are increasingly integrated into many online services. However, a major challenge in deploying LLMs is their high cost, due primarily to the use of expensive GPU instances. To address this problem, we find that the significant heterogeneity of GPU types presents an opportunity to increase GPU cost efficiency and reduce deployment costs. The broad and growing market of GPUs creates a diverse option space with varying costs and hardware specifications. Within this space, we show that there is not a linear relationship between GPU cost and performance, and identify three key LLM service characteristics that significantly affect which GPU type is the most cost effective: model request size, request rate, and latency service-level objective (SLO). We then present M\'elange, a framework for navigating the diversity of GPUs and LLM service specifications to derive the most cost-efficient set of GPUs for a given LLM service. We frame the task of GPU selection as a cost-aware bin-packing problem, where GPUs are bins with a capacity and cost, and items are request slices defined by a request size and rate. Upon solution, M\'elange derives the minimal-cost GPU allocation that adheres to a configurable latency SLO. Our evaluations across both real-world and synthetic datasets demonstrate that M\'elange can reduce deployment costs by up to 77% as compared to utilizing only a single GPU type, highlighting the importance of making heterogeneity-aware GPU provisioning decisions for LLM serving. Our source code is publicly available at https://github.com/tyler-griggs/melange-release.
Computing in the Era of Large Generative Models: From Cloud-Native to AI-Native
Jan 17, 2024In this paper, we investigate the intersection of large generative AI models and cloud-native computing architectures. Recent large models such as ChatGPT, while revolutionary in their capabilities, face challenges like escalating costs and demand for high-end GPUs. Drawing analogies between large-model-as-a-service (LMaaS) and cloud database-as-a-service (DBaaS), we describe an AI-native computing paradigm that harnesses the power of both cloud-native technologies (e.g., multi-tenancy and serverless computing) and advanced machine learning runtime (e.g., batched LoRA inference). These joint efforts aim to optimize costs-of-goods-sold (COGS) and improve resource accessibility. The journey of merging these two domains is just at the beginning and we hope to stimulate future research and development in this area.
Learned Best-Effort LLM Serving
Jan 15, 2024Many applications must provide low-latency LLM service to users or risk unacceptable user experience. However, over-provisioning resources to serve fluctuating request patterns is often prohibitively expensive. In this work, we present a best-effort serving system that employs deep reinforcement learning to adjust service quality based on the task distribution and system load. Our best-effort system can maintain availability with over 10x higher client request rates, serves above 96% of peak performance 4.1x more often, and serves above 98% of peak performance 2.3x more often than static serving on unpredictable workloads. Our learned router is robust to shifts in both the arrival and task distribution. Compared to static serving, learned best-effort serving allows for cost-efficient serving through increased hardware utility. Additionally, we argue that learned best-effort LLM serving is applicable in wide variety of settings and provides application developers great flexibility to meet their specific needs.
Online Speculative Decoding
Oct 17, 2023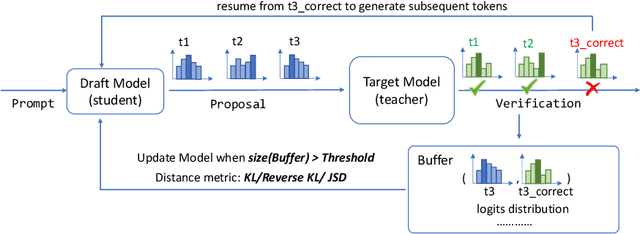


Speculative decoding is a pivotal technique to accelerate the inference of large language models (LLMs) by employing a smaller draft model to predict the target model's outputs. However, its efficacy can be limited due to the low predictive accuracy of the draft model, particularly when faced with diverse text inputs and a significant capability gap between the draft and target models. We introduce online speculative decoding (OSD) to address this challenge. The main idea is to continually update (multiple) draft model(s) on observed user query data using the abundant excess computational power in an LLM serving cluster. Given that LLM inference is memory-bounded, the surplus computational power in a typical LLM serving cluster can be repurposed for online retraining of draft models, thereby making the training cost-neutral. Since the query distribution of an LLM service is relatively simple, retraining on query distribution enables the draft model to more accurately predict the target model's outputs, particularly on data originating from query distributions. As the draft model evolves online, it aligns with the query distribution in real time, mitigating distribution shifts. We develop a prototype of online speculative decoding based on online knowledge distillation and evaluate it using both synthetic and real query data on several popular LLMs. The results show a substantial increase in the token acceptance rate by 0.1 to 0.65, which translates into 1.22x to 3.06x latency reduction.
QFT: Quantized Full-parameter Tuning of LLMs with Affordable Resources
Oct 11, 2023Large Language Models (LLMs) have showcased remarkable impacts across a wide spectrum of natural language processing tasks. Fine-tuning these pre-trained models on downstream datasets provides further significant performance gains, but this process has been challenging due to its extraordinary resource requirements. To this end, existing efforts focus on parameter-efficient fine-tuning, which, unfortunately, fail to capitalize on the powerful potential of full-parameter fine-tuning. In this work, we propose QFT, a novel Quantized Full-parameter Tuning framework for LLMs that enables memory-efficient fine-tuning without harming performance. Our framework incorporates two novel ideas: (i) we adopt the efficient Lion optimizer, which only keeps track of the momentum and has consistent update magnitudes for each parameter, an inherent advantage for robust quantization; and (ii) we quantize all model states and store them as integer values, and present a gradient flow and parameter update scheme for the quantized weights. As a result, QFT reduces the model state memory to 21% of the standard solution while achieving comparable performance, e.g., tuning a LLaMA-7B model requires only <30GB of memory, satisfied by a single A6000 GPU.
What is the State of Memory Saving for Model Training?
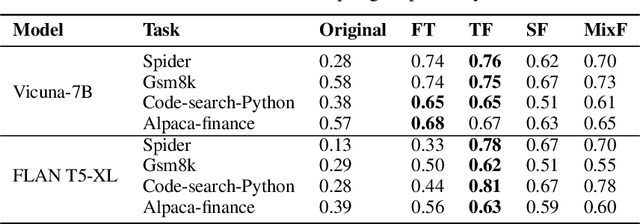
Mar 26, 2023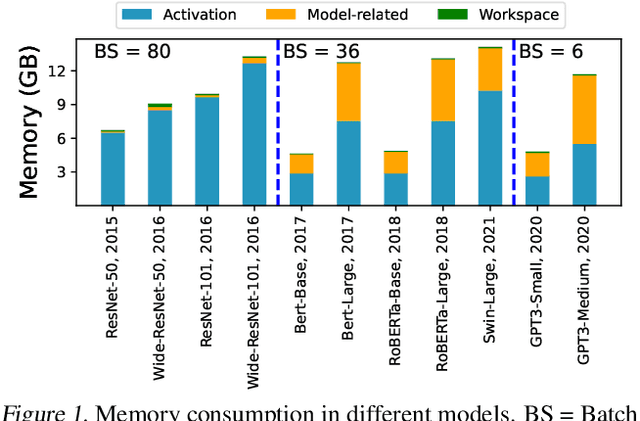
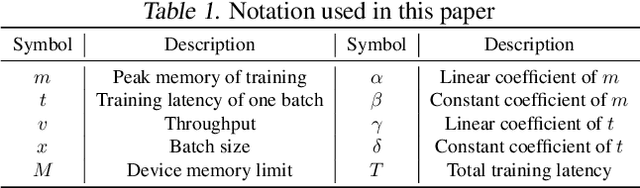
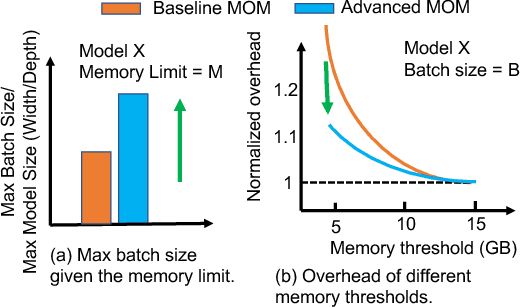
Large neural networks can improve the accuracy and generalization on tasks across many domains. However, this trend cannot continue indefinitely due to limited hardware memory. As a result, researchers have devised a number of memory optimization methods (MOMs) to alleviate the memory bottleneck, such as gradient checkpointing, quantization, and swapping. In this work, we study memory optimization methods and show that, although these strategies indeed lower peak memory usage, they can actually decrease training throughput by up to 9.3x. To provide practical guidelines for practitioners, we propose a simple but effective performance model PAPAYA to quantitatively explain the memory and training time trade-off. PAPAYA can be used to determine when to apply the various memory optimization methods in training different models. We outline the circumstances in which memory optimization techniques are more advantageous based on derived implications from PAPAYA. We assess the accuracy of PAPAYA and the derived implications on a variety of machine models, showing that it achieves over 0.97 R score on predicting the peak memory/throughput, and accurately predicts the effectiveness of MOMs across five evaluated models on vision and NLP tasks.
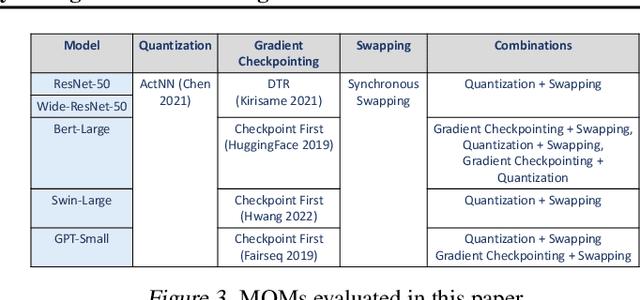
GACT: Activation Compressed Training for General Architectures
Jun 28, 2022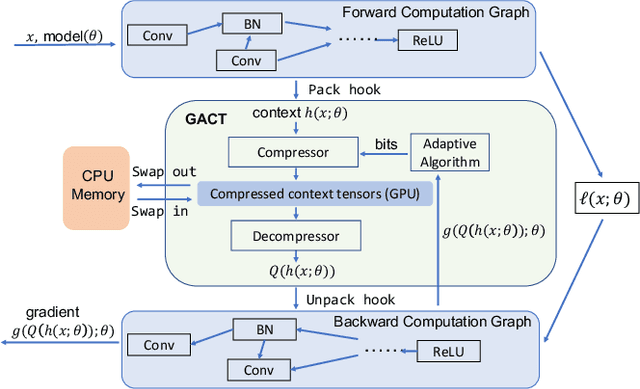
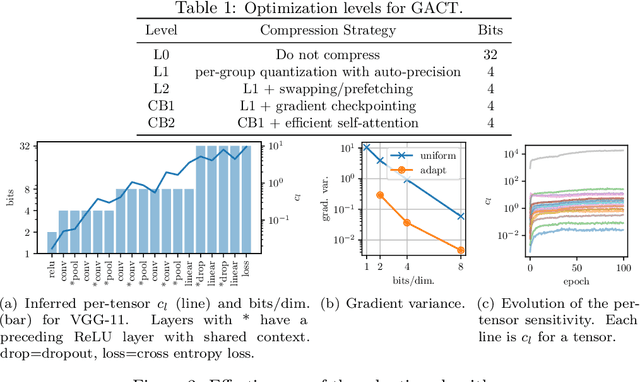

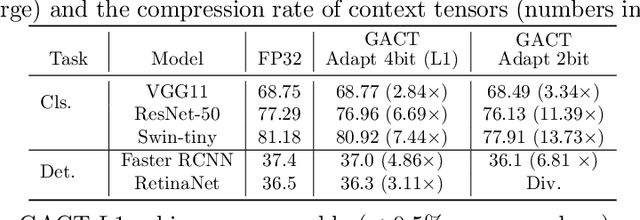
Training large neural network (NN) models requires extensive memory resources, and Activation Compressed Training (ACT) is a promising approach to reduce training memory footprint. This paper presents GACT, an ACT framework to support a broad range of machine learning tasks for generic NN architectures with limited domain knowledge. By analyzing a linearized version of ACT's approximate gradient, we prove the convergence of GACT without prior knowledge on operator type or model architecture. To make training stable, we propose an algorithm that decides the compression ratio for each tensor by estimating its impact on the gradient at run time. We implement GACT as a PyTorch library that readily applies to any NN architecture. GACT reduces the activation memory for convolutional NNs, transformers, and graph NNs by up to 8.1x, enabling training with a 4.2x to 24.7x larger batch size, with negligible accuracy loss.
Long-run User Value Optimization in Recommender Systems through Content Creation Modeling
Apr 25, 2022
Content recommender systems are generally adept at maximizing immediate user satisfaction but to optimize for the \textit{long-run} user value, we need more statistically sophisticated solutions than off-the-shelf simple recommender algorithms. In this paper we lay out such a solution to optimize \textit{long-run} user value through discounted utility maximization and a machine learning method we have developed for estimating it. Our method estimates which content producers are most likely to create the highest long-run user value if their content is shown more to users who enjoy it in the present. We do this estimation with the help of an A/B test and heterogeneous effects machine learning model. We have used such models in Facebook's feed ranking system, and such a model can be used in other recommender systems.