 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXin Pan
SparseByteNN: A Novel Mobile Inference Acceleration Framework Based on Fine-Grained Group Sparsity
Oct 30, 2023
To address the challenge of increasing network size, researchers have developed sparse models through network pruning. However, maintaining model accuracy while achieving significant speedups on general computing devices remains an open problem. In this paper, we present a novel mobile inference acceleration framework SparseByteNN, which leverages fine-grained kernel sparsity to achieve real-time execution as well as high accuracy. Our framework consists of two parts: (a) A fine-grained kernel sparsity schema with a sparsity granularity between structured pruning and unstructured pruning. It designs multiple sparse patterns for different operators. Combined with our proposed whole network rearrangement strategy, the schema achieves a high compression rate and high precision at the same time. (b) Inference engine co-optimized with the sparse pattern. The conventional wisdom is that this reduction in theoretical FLOPs does not translate into real-world efficiency gains. We aim to correct this misconception by introducing a family of efficient sparse kernels for ARM and WebAssembly. Equipped with our efficient implementation of sparse primitives, we show that sparse versions of MobileNet-v1 outperform strong dense baselines on the efficiency-accuracy curve. Experimental results on Qualcomm 855 show that for 30% sparse MobileNet-v1, SparseByteNN achieves 1.27x speedup over the dense version and 1.29x speedup over the state-of-the-art sparse inference engine MNN with a slight accuracy drop of 0.224%. The source code of SparseByteNN will be available at https://github.com/lswzjuer/SparseByteNN
AutoDiffusion: Training-Free Optimization of Time Steps and Architectures for Automated Diffusion Model Acceleration
Sep 23, 2023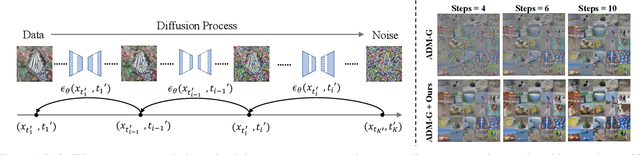


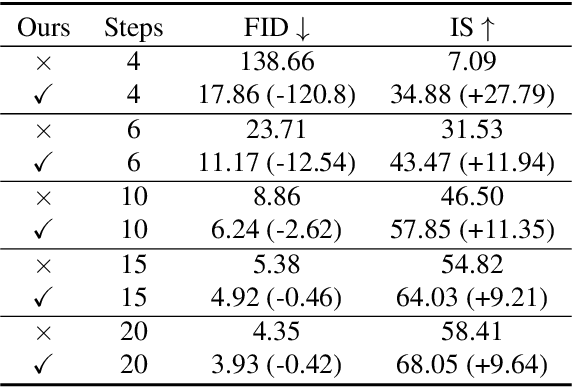
Diffusion models are emerging expressive generative models, in which a large number of time steps (inference steps) are required for a single image generation. To accelerate such tedious process, reducing steps uniformly is considered as an undisputed principle of diffusion models. We consider that such a uniform assumption is not the optimal solution in practice; i.e., we can find different optimal time steps for different models. Therefore, we propose to search the optimal time steps sequence and compressed model architecture in a unified framework to achieve effective image generation for diffusion models without any further training. Specifically, we first design a unified search space that consists of all possible time steps and various architectures. Then, a two stage evolutionary algorithm is introduced to find the optimal solution in the designed search space. To further accelerate the search process, we employ FID score between generated and real samples to estimate the performance of the sampled examples. As a result, the proposed method is (i).training-free, obtaining the optimal time steps and model architecture without any training process; (ii). orthogonal to most advanced diffusion samplers and can be integrated to gain better sample quality. (iii). generalized, where the searched time steps and architectures can be directly applied on different diffusion models with the same guidance scale. Experimental results show that our method achieves excellent performance by using only a few time steps, e.g. 17.86 FID score on ImageNet 64 $\times$ 64 with only four steps, compared to 138.66 with DDIM. The code is available at https://github.com/lilijiangg/AutoDiffusion.
UGC: Unified GAN Compression for Efficient Image-to-Image Translation
Sep 17, 2023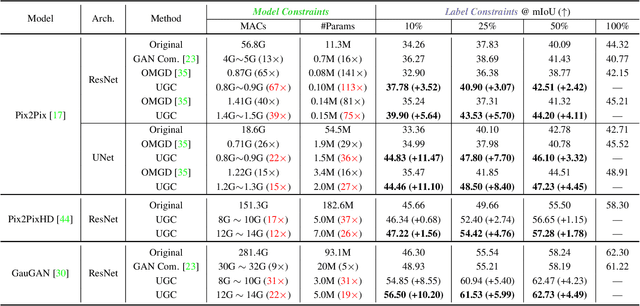

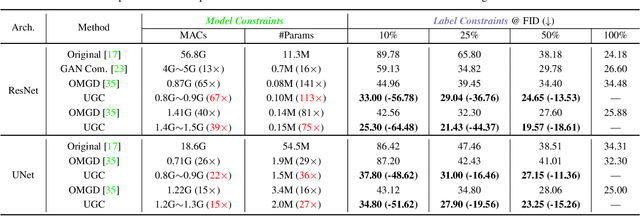
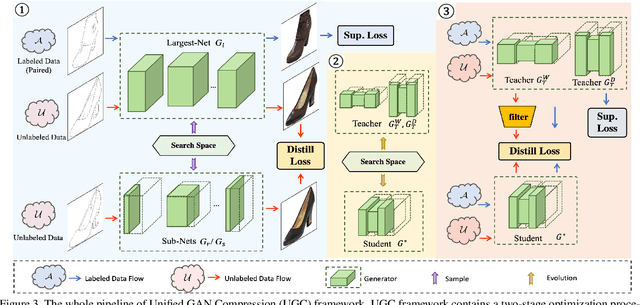
Recent years have witnessed the prevailing progress of Generative Adversarial Networks (GANs) in image-to-image translation. However, the success of these GAN models hinges on ponderous computational costs and labor-expensive training data. Current efficient GAN learning techniques often fall into two orthogonal aspects: i) model slimming via reduced calculation costs; ii)data/label-efficient learning with fewer training data/labels. To combine the best of both worlds, we propose a new learning paradigm, Unified GAN Compression (UGC), with a unified optimization objective to seamlessly prompt the synergy of model-efficient and label-efficient learning. UGC sets up semi-supervised-driven network architecture search and adaptive online semi-supervised distillation stages sequentially, which formulates a heterogeneous mutual learning scheme to obtain an architecture-flexible, label-efficient, and performance-excellent model.
AlignDet: Aligning Pre-training and Fine-tuning in Object Detection
Jul 20, 2023
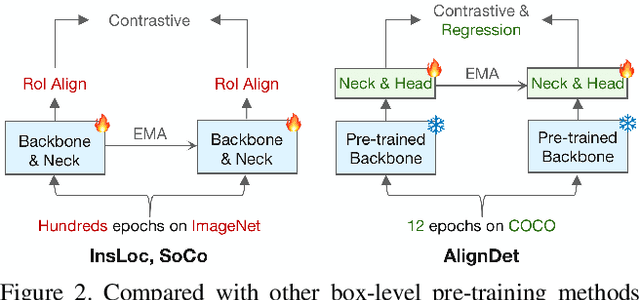
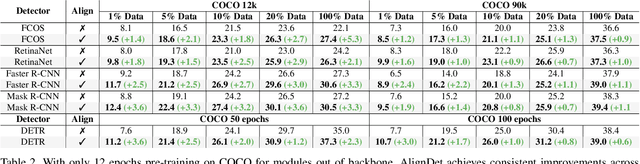
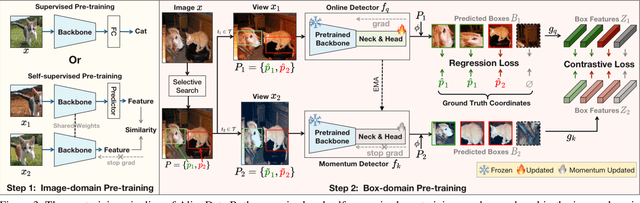
The paradigm of large-scale pre-training followed by downstream fine-tuning has been widely employed in various object detection algorithms. In this paper, we reveal discrepancies in data, model, and task between the pre-training and fine-tuning procedure in existing practices, which implicitly limit the detector's performance, generalization ability, and convergence speed. To this end, we propose AlignDet, a unified pre-training framework that can be adapted to various existing detectors to alleviate the discrepancies. AlignDet decouples the pre-training process into two stages, i.e., image-domain and box-domain pre-training. The image-domain pre-training optimizes the detection backbone to capture holistic visual abstraction, and box-domain pre-training learns instance-level semantics and task-aware concepts to initialize the parts out of the backbone. By incorporating the self-supervised pre-trained backbones, we can pre-train all modules for various detectors in an unsupervised paradigm. As depicted in Figure 1, extensive experiments demonstrate that AlignDet can achieve significant improvements across diverse protocols, such as detection algorithm, model backbone, data setting, and training schedule. For example, AlignDet improves FCOS by 5.3 mAP, RetinaNet by 2.1 mAP, Faster R-CNN by 3.3 mAP, and DETR by 2.3 mAP under fewer epochs.
Channel-Spatial-Based Few-Shot Bird Sound Event Detection
Jun 25, 2023



In this paper, we propose a model for bird sound event detection that focuses on a small number of training samples within the everyday long-tail distribution. As a result, we investigate bird sound detection using the few-shot learning paradigm. By integrating channel and spatial attention mechanisms, improved feature representations can be learned from few-shot training datasets. We develop a Metric Channel-Spatial Network model by incorporating a Channel Spatial Squeeze-Excitation block into the prototype network, combining it with these attention mechanisms. We evaluate the Metric Channel Spatial Network model on the DCASE 2022 Take5 dataset benchmark, achieving an F-measure of 66.84% and a PSDS of 58.98%. Our experiment demonstrates that the combination of channel and spatial attention mechanisms effectively enhances the performance of bird sound classification and detection.
Solving Oscillation Problem in Post-Training Quantization Through a Theoretical Perspective
Apr 04, 2023



Post-training quantization (PTQ) is widely regarded as one of the most efficient compression methods practically, benefitting from its data privacy and low computation costs. We argue that an overlooked problem of oscillation is in the PTQ methods. In this paper, we take the initiative to explore and present a theoretical proof to explain why such a problem is essential in PTQ. And then, we try to solve this problem by introducing a principled and generalized framework theoretically. In particular, we first formulate the oscillation in PTQ and prove the problem is caused by the difference in module capacity. To this end, we define the module capacity (ModCap) under data-dependent and data-free scenarios, where the differentials between adjacent modules are used to measure the degree of oscillation. The problem is then solved by selecting top-k differentials, in which the corresponding modules are jointly optimized and quantized. Extensive experiments demonstrate that our method successfully reduces the performance drop and is generalized to different neural networks and PTQ methods. For example, with 2/4 bit ResNet-50 quantization, our method surpasses the previous state-of-the-art method by 1.9%. It becomes more significant on small model quantization, e.g. surpasses BRECQ method by 6.61% on MobileNetV2*0.5.
FreeSeg: Unified, Universal and Open-Vocabulary Image Segmentation
Mar 30, 2023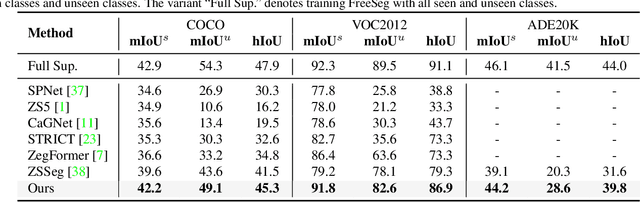
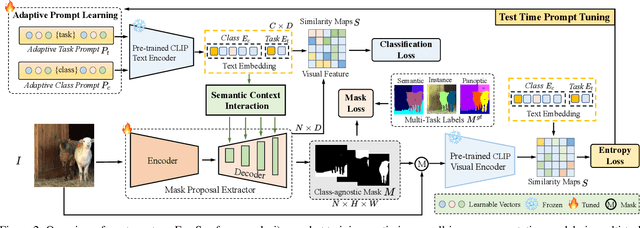
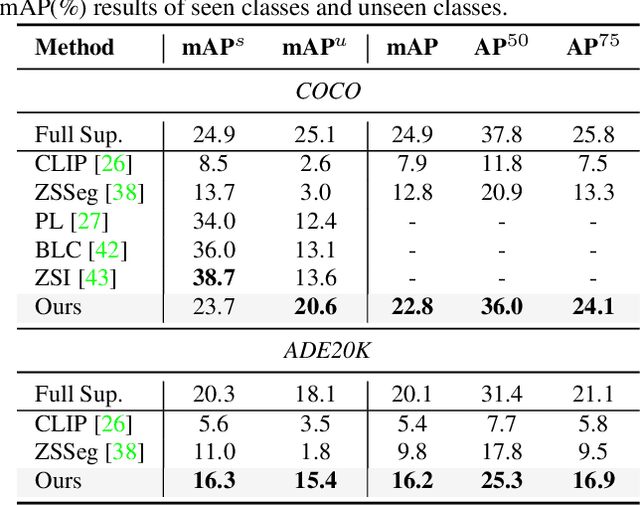
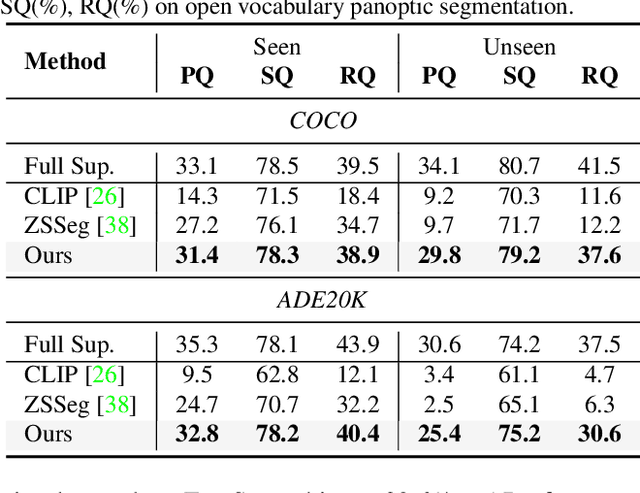
Recently, open-vocabulary learning has emerged to accomplish segmentation for arbitrary categories of text-based descriptions, which popularizes the segmentation system to more general-purpose application scenarios. However, existing methods devote to designing specialized architectures or parameters for specific segmentation tasks. These customized design paradigms lead to fragmentation between various segmentation tasks, thus hindering the uniformity of segmentation models. Hence in this paper, we propose FreeSeg, a generic framework to accomplish Unified, Universal and Open-Vocabulary Image Segmentation. FreeSeg optimizes an all-in-one network via one-shot training and employs the same architecture and parameters to handle diverse segmentation tasks seamlessly in the inference procedure. Additionally, adaptive prompt learning facilitates the unified model to capture task-aware and category-sensitive concepts, improving model robustness in multi-task and varied scenarios. Extensive experimental results demonstrate that FreeSeg establishes new state-of-the-art results in performance and generalization on three segmentation tasks, which outperforms the best task-specific architectures by a large margin: 5.5% mIoU on semantic segmentation, 17.6% mAP on instance segmentation, 20.1% PQ on panoptic segmentation for the unseen class on COCO.
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
Jul 13, 2022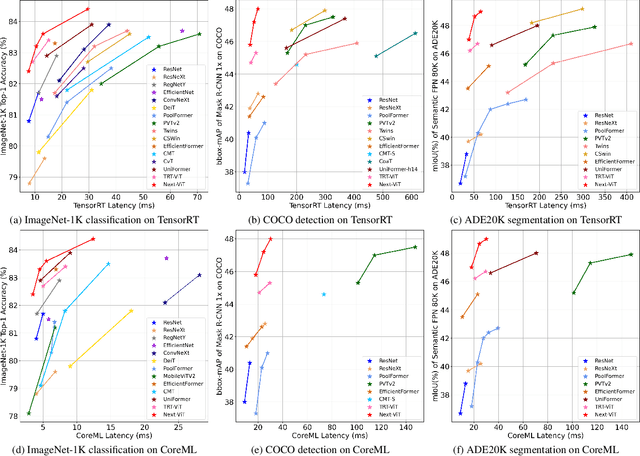
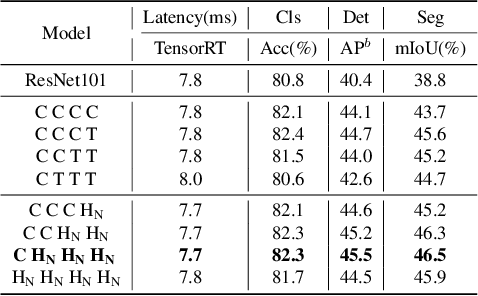
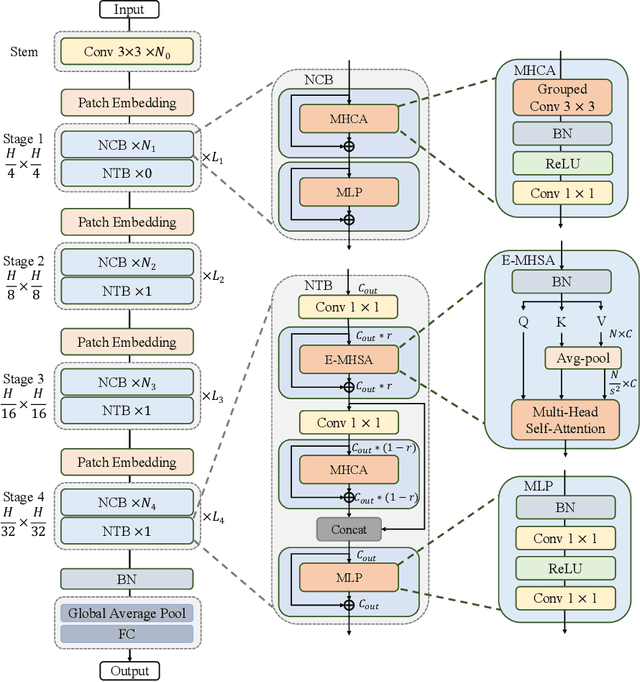
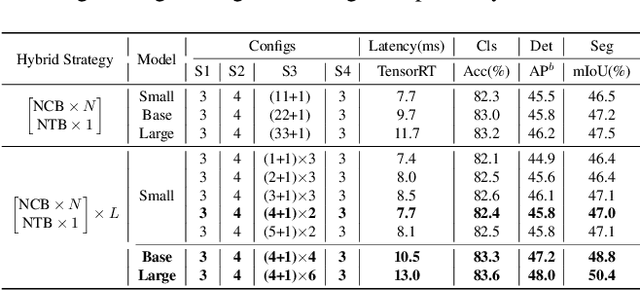
Due to the complex attention mechanisms and model design, most existing vision Transformers (ViTs) can not perform as efficiently as convolutional neural networks (CNNs) in realistic industrial deployment scenarios, e.g. TensorRT and CoreML. This poses a distinct challenge: Can a visual neural network be designed to infer as fast as CNNs and perform as powerful as ViTs? Recent works have tried to design CNN-Transformer hybrid architectures to address this issue, yet the overall performance of these works is far away from satisfactory. To end these, we propose a next generation vision Transformer for efficient deployment in realistic industrial scenarios, namely Next-ViT, which dominates both CNNs and ViTs from the perspective of latency/accuracy trade-off. In this work, the Next Convolution Block (NCB) and Next Transformer Block (NTB) are respectively developed to capture local and global information with deployment-friendly mechanisms. Then, Next Hybrid Strategy (NHS) is designed to stack NCB and NTB in an efficient hybrid paradigm, which boosts performance in various downstream tasks. Extensive experiments show that Next-ViT significantly outperforms existing CNNs, ViTs and CNN-Transformer hybrid architectures with respect to the latency/accuracy trade-off across various vision tasks. On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation under similar latency. Meanwhile, it achieves comparable performance with CSWin, while the inference speed is accelerated by 3.6x. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency. Code will be released recently.
Parallel Pre-trained Transformers (PPT) for Synthetic Data-based Instance Segmentation
Jun 22, 2022



Recently, Synthetic data-based Instance Segmentation has become an exceedingly favorable optimization paradigm since it leverages simulation rendering and physics to generate high-quality image-annotation pairs. In this paper, we propose a Parallel Pre-trained Transformers (PPT) framework to accomplish the synthetic data-based Instance Segmentation task. Specifically, we leverage the off-the-shelf pre-trained vision Transformers to alleviate the gap between natural and synthetic data, which helps to provide good generalization in the downstream synthetic data scene with few samples. Swin-B-based CBNet V2, SwinL-based CBNet V2 and Swin-L-based Uniformer are employed for parallel feature learning, and the results of these three models are fused by pixel-level Non-maximum Suppression (NMS) algorithm to obtain more robust results. The experimental results reveal that PPT ranks first in the CVPR2022 AVA Accessibility Vision and Autonomy Challenge, with a 65.155% mAP.
YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video
Mar 24, 2017



We introduce a new large-scale data set of video URLs with densely-sampled object bounding box annotations called YouTube-BoundingBoxes (YT-BB). The data set consists of approximately 380,000 video segments about 19s long, automatically selected to feature objects in natural settings without editing or post-processing, with a recording quality often akin to that of a hand-held cell phone camera. The objects represent a subset of the MS COCO label set. All video segments were human-annotated with high-precision classification labels and bounding boxes at 1 frame per second. The use of a cascade of increasingly precise human annotations ensures a label accuracy above 95% for every class and tight bounding boxes. Finally, we train and evaluate well-known deep network architectures and report baseline figures for per-frame classification and localization to provide a point of comparison for future work. We also demonstrate how the temporal contiguity of video can potentially be used to improve such inferences. Please see the PDF file to find the URL to download the data. We hope the availability of such large curated corpus will spur new advances in video object detection and tracking.