 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXin Tian
OCT2Confocal: 3D CycleGAN based Translation of Retinal OCT Images to Confocal Microscopy
Nov 26, 2023
Optical coherence tomography (OCT) and confocal microscopy are pivotal in retinal imaging, each presenting unique benefits and limitations. In vivo OCT offers rapid, non-invasive imaging but can be hampered by clarity issues and motion artifacts. Ex vivo confocal microscopy provides high-resolution, cellular detailed color images but is invasive and poses ethical concerns and potential tissue damage. To bridge these modalities, we developed a 3D CycleGAN framework for unsupervised translation of in vivo OCT to ex vivo confocal microscopy images. Applied to our OCT2Confocal dataset, this framework effectively translates between 3D medical data domains, capturing vascular, textural, and cellular details with precision. This marks the first attempt to exploit the inherent 3D information of OCT and translate it into the rich, detailed color domain of confocal microscopy. Assessed through quantitative and qualitative metrics, the 3D CycleGAN framework demonstrates commendable image fidelity and quality, outperforming existing methods despite the constraints of limited data. This non-invasive generation of retinal confocal images has the potential to further enhance diagnostic and monitoring capabilities in ophthalmology.
A Canonical Data Transformation for Achieving Inter- and Within-group Fairness
Oct 23, 2023Increases in the deployment of machine learning algorithms for applications that deal with sensitive data have brought attention to the issue of fairness in machine learning. Many works have been devoted to applications that require different demographic groups to be treated fairly. However, algorithms that aim to satisfy inter-group fairness (also called group fairness) may inadvertently treat individuals within the same demographic group unfairly. To address this issue, we introduce a formal definition of within-group fairness that maintains fairness among individuals from within the same group. We propose a pre-processing framework to meet both inter- and within-group fairness criteria with little compromise in accuracy. The framework maps the feature vectors of members from different groups to an inter-group-fair canonical domain before feeding them into a scoring function. The mapping is constructed to preserve the relative relationship between the scores obtained from the unprocessed feature vectors of individuals from the same demographic group, guaranteeing within-group fairness. We apply this framework to the COMPAS risk assessment and Law School datasets and compare its performance in achieving inter-group and within-group fairness to two regularization-based methods.
Query Enhanced Knowledge-Intensive Conversation via Unsupervised Joint Modeling
Dec 19, 2022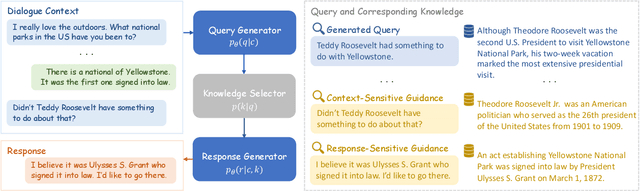


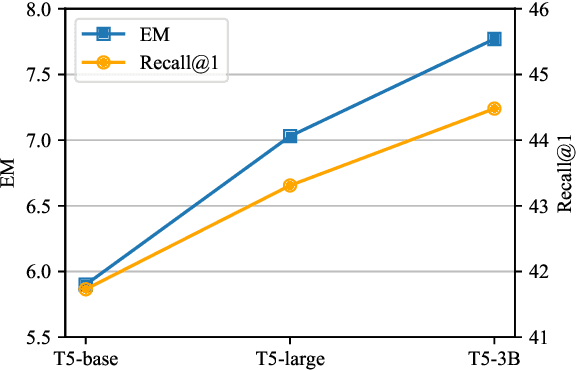
The quality of knowledge retrieval is crucial in knowledge-intensive conversations. Two common strategies to improve the retrieval quality are finetuning the retriever or generating a self-contained query, while they encounter heavy burdens on expensive computation and elaborate annotations. In this paper, we propose an unsupervised query enhanced approach for knowledge-intensive conversations, namely QKConv. There are three modules in QKConv: a query generator, an off-the-shelf knowledge selector, and a response generator. Without extra supervision, the end-to-end joint training of QKConv explores multiple candidate queries and utilizes corresponding selected knowledge to yield the target response. To evaluate the effectiveness of the proposed method, we conducted comprehensive experiments on conversational question-answering, task-oriented dialogue, and knowledge-grounded conversation. Experimental results demonstrate that QKConv achieves state-of-the-art performance compared to unsupervised methods and competitive performance compared to supervised methods.
Q-TOD: A Query-driven Task-oriented Dialogue System
Oct 14, 2022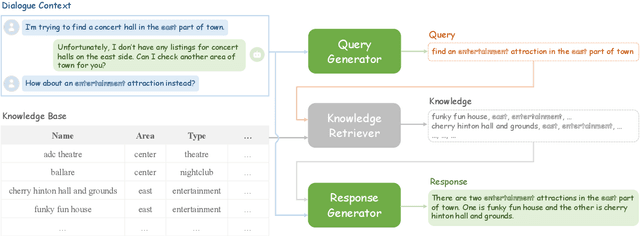
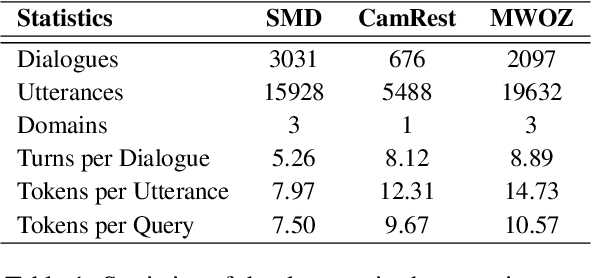
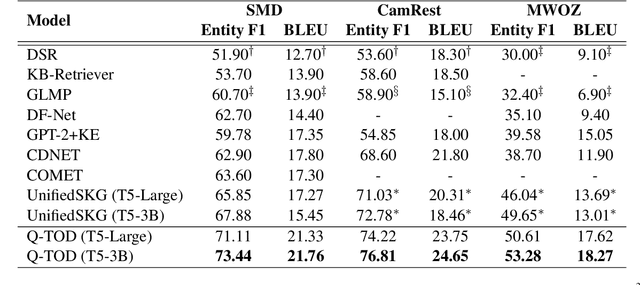
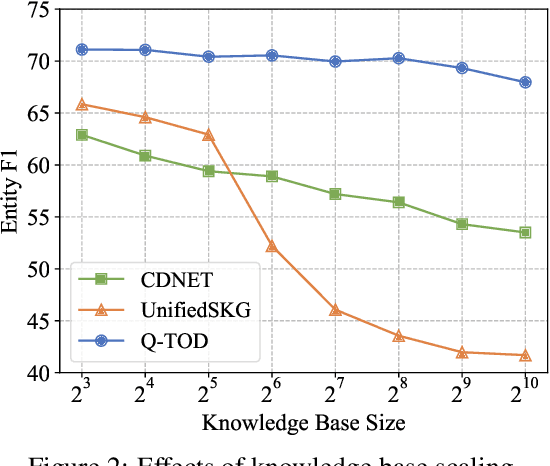
Existing pipelined task-oriented dialogue systems usually have difficulties adapting to unseen domains, whereas end-to-end systems are plagued by large-scale knowledge bases in practice. In this paper, we introduce a novel query-driven task-oriented dialogue system, namely Q-TOD. The essential information from the dialogue context is extracted into a query, which is further employed to retrieve relevant knowledge records for response generation. Firstly, as the query is in the form of natural language and not confined to the schema of the knowledge base, the issue of domain adaption is alleviated remarkably in Q-TOD. Secondly, as the query enables the decoupling of knowledge retrieval from the generation, Q-TOD gets rid of the issue of knowledge base scalability. To evaluate the effectiveness of the proposed Q-TOD, we collect query annotations for three publicly available task-oriented dialogue datasets. Comprehensive experiments verify that Q-TOD outperforms strong baselines and establishes a new state-of-the-art performance on these datasets.
Bi-directional Object-context Prioritization Learning for Saliency Ranking
Mar 22, 2022



The saliency ranking task is recently proposed to study the visual behavior that humans would typically shift their attention over different objects of a scene based on their degrees of saliency. Existing approaches focus on learning either object-object or object-scene relations. Such a strategy follows the idea of object-based attention in Psychology, but it tends to favor those objects with strong semantics (e.g., humans), resulting in unrealistic saliency ranking. We observe that spatial attention works concurrently with object-based attention in the human visual recognition system. During the recognition process, the human spatial attention mechanism would move, engage, and disengage from region to region (i.e., context to context). This inspires us to model the region-level interactions, in addition to the object-level reasoning, for saliency ranking. To this end, we propose a novel bi-directional method to unify spatial attention and object-based attention for saliency ranking. Our model includes two novel modules: (1) a selective object saliency (SOS) module that models objectbased attention via inferring the semantic representation of the salient object, and (2) an object-context-object relation (OCOR) module that allocates saliency ranks to objects by jointly modeling the object-context and context-object interactions of the salient objects. Extensive experiments show that our approach outperforms existing state-of-theart methods. Our code and pretrained model are available at https://github.com/GrassBro/OCOR.
Optimal Transport-based Graph Matching for 3D retinal OCT image registration
Feb 28, 2022



Registration of longitudinal optical coherence tomography (OCT) images assists disease monitoring and is essential in image fusion applications. Mouse retinal OCT images are often collected for longitudinal study of eye disease models such as uveitis, but their quality is often poor compared with human imaging. This paper presents a novel but efficient framework involving an optimal transport based graph matching (OT-GM) method for 3D mouse OCT image registration. We first perform registration of fundus-like images obtained by projecting all b-scans of a volume on a plane orthogonal to them, hereafter referred to as the x-y plane. We introduce Adaptive Weighted Vessel Graph Descriptors (AWVGD) and 3D Cube Descriptors (CD) to identify the correspondence between nodes of graphs extracted from segmented vessels within the OCT projection images. The AWVGD comprises scaling, translation and rotation, which are computationally efficient, whereas CD exploits 3D spatial and frequency domain information. The OT-GM method subsequently performs the correct alignment in the x-y plane. Finally, registration along the direction orthogonal to the x-y plane (the z-direction) is guided by the segmentation of two important anatomical features peculiar to mouse b-scans, the Internal Limiting Membrane (ILM) and the hyaloid remnant (HR). Both subjective and objective evaluation results demonstrate that our framework outperforms other well-established methods on mouse OCT images within a reasonable execution time.
TOD-DA: Towards Boosting the Robustness of Task-oriented Dialogue Modeling on Spoken Conversations
Dec 23, 2021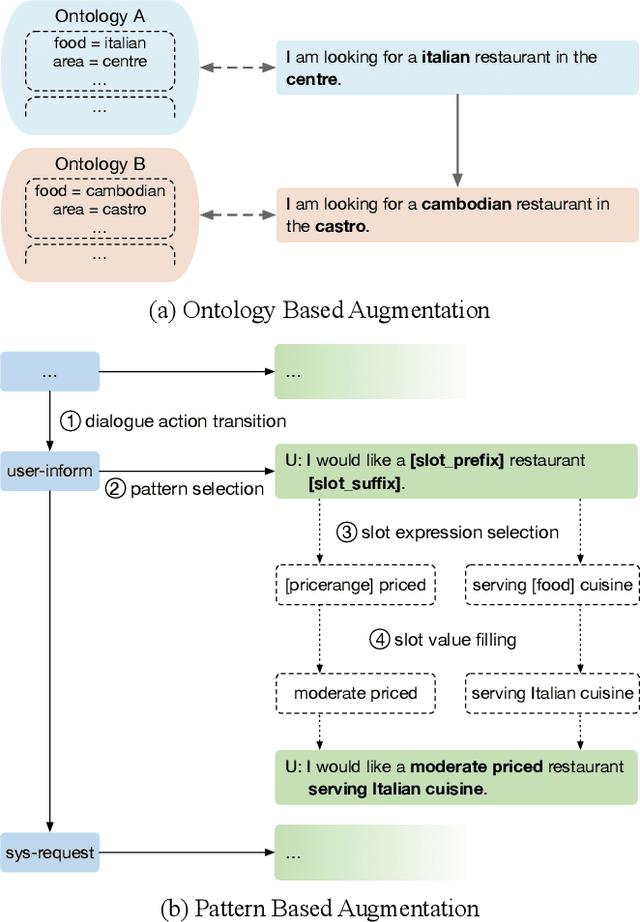
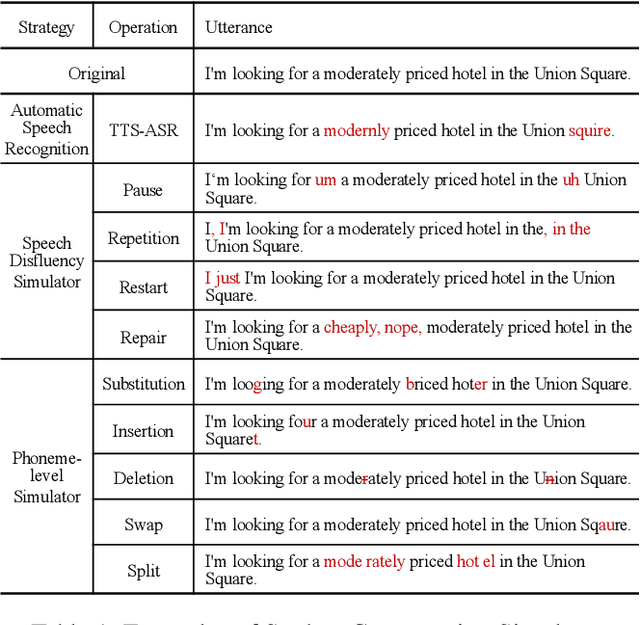
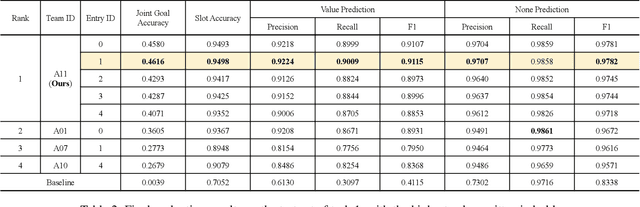
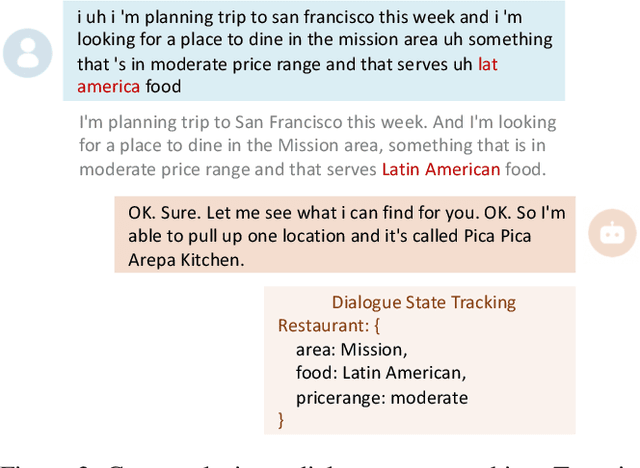
Task-oriented dialogue systems have been plagued by the difficulties of obtaining large-scale and high-quality annotated conversations. Furthermore, most of the publicly available datasets only include written conversations, which are insufficient to reflect actual human behaviors in practical spoken dialogue systems. In this paper, we propose Task-oriented Dialogue Data Augmentation (TOD-DA), a novel model-agnostic data augmentation paradigm to boost the robustness of task-oriented dialogue modeling on spoken conversations. The TOD-DA consists of two modules: 1) Dialogue Enrichment to expand training data on task-oriented conversations for easing data sparsity and 2) Spoken Conversation Simulator to imitate oral style expressions and speech recognition errors in diverse granularities for bridging the gap between written and spoken conversations. With such designs, our approach ranked first in both tasks of DSTC10 Track2, a benchmark for task-oriented dialogue modeling on spoken conversations, demonstrating the superiority and effectiveness of our proposed TOD-DA.
Learning to Detect Instance-level Salient Objects Using Complementary Image Labels
Nov 19, 2021



Existing salient instance detection (SID) methods typically learn from pixel-level annotated datasets. In this paper, we present the first weakly-supervised approach to the SID problem. Although weak supervision has been considered in general saliency detection, it is mainly based on using class labels for object localization. However, it is non-trivial to use only class labels to learn instance-aware saliency information, as salient instances with high semantic affinities may not be easily separated by the labels. As the subitizing information provides an instant judgement on the number of salient items, it is naturally related to detecting salient instances and may help separate instances of the same class while grouping different parts of the same instance. Inspired by this observation, we propose to use class and subitizing labels as weak supervision for the SID problem. We propose a novel weakly-supervised network with three branches: a Saliency Detection Branch leveraging class consistency information to locate candidate objects; a Boundary Detection Branch exploiting class discrepancy information to delineate object boundaries; and a Centroid Detection Branch using subitizing information to detect salient instance centroids. This complementary information is then fused to produce a salient instance map. To facilitate the learning process, we further propose a progressive training scheme to reduce label noise and the corresponding noise learned by the model, via reciprocating the model with progressive salient instance prediction and model refreshing. Our extensive evaluations show that the proposed method plays favorably against carefully designed baseline methods adapted from related tasks.
Amendable Generation for Dialogue State Tracking
Oct 29, 2021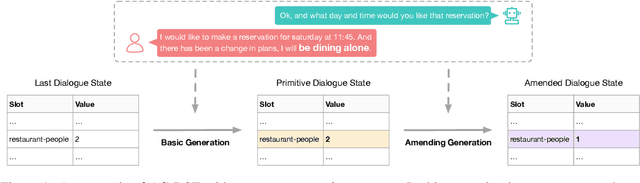
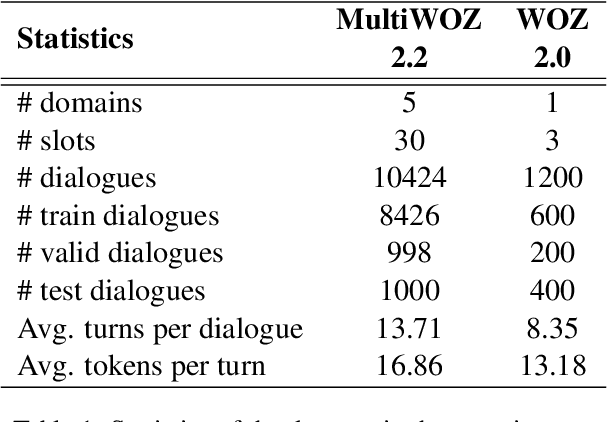
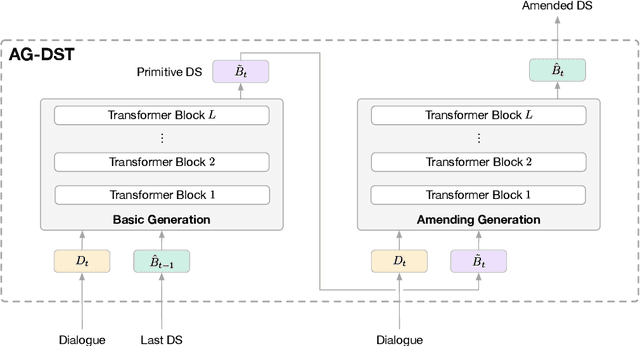
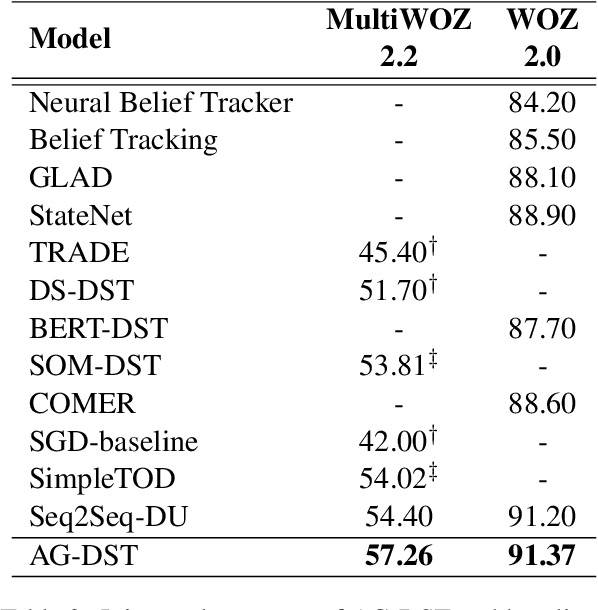
In task-oriented dialogue systems, recent dialogue state tracking methods tend to perform one-pass generation of the dialogue state based on the previous dialogue state. The mistakes of these models made at the current turn are prone to be carried over to the next turn, causing error propagation. In this paper, we propose a novel Amendable Generation for Dialogue State Tracking (AG-DST), which contains a two-pass generation process: (1) generating a primitive dialogue state based on the dialogue of the current turn and the previous dialogue state, and (2) amending the primitive dialogue state from the first pass. With the additional amending generation pass, our model is tasked to learn more robust dialogue state tracking by amending the errors that still exist in the primitive dialogue state, which plays the role of reviser in the double-checking process and alleviates unnecessary error propagation. Experimental results show that AG-DST significantly outperforms previous works in two active DST datasets (MultiWOZ 2.2 and WOZ 2.0), achieving new state-of-the-art performances.
PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation
Sep 20, 2021
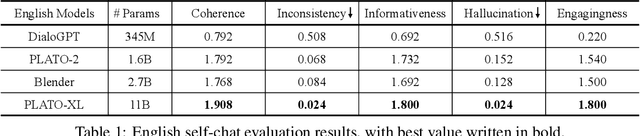

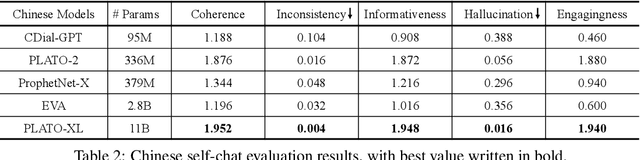
To explore the limit of dialogue generation pre-training, we present the models of PLATO-XL with up to 11 billion parameters, trained on both Chinese and English social media conversations. To train such large models, we adopt the architecture of unified transformer with high computation and parameter efficiency. In addition, we carry out multi-party aware pre-training to better distinguish the characteristic information in social media conversations. With such designs, PLATO-XL successfully achieves superior performances as compared to other approaches in both Chinese and English chitchat. We further explore the capacity of PLATO-XL on other conversational tasks, such as knowledge grounded dialogue and task-oriented conversation. The experimental results indicate that PLATO-XL obtains state-of-the-art results across multiple conversational tasks, verifying its potential as a foundation model of conversational AI.