 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinhai Liu
D-Net: Learning for Distinctive Point Clouds by Self-Attentive Point Searching and Learnable Feature Fusion
May 10, 2023
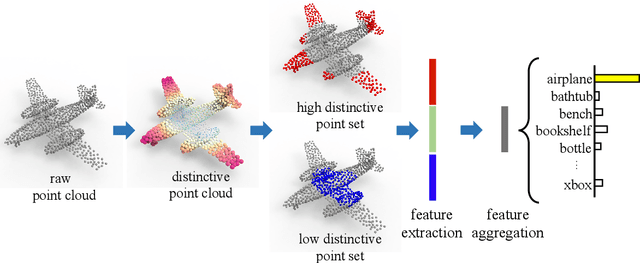
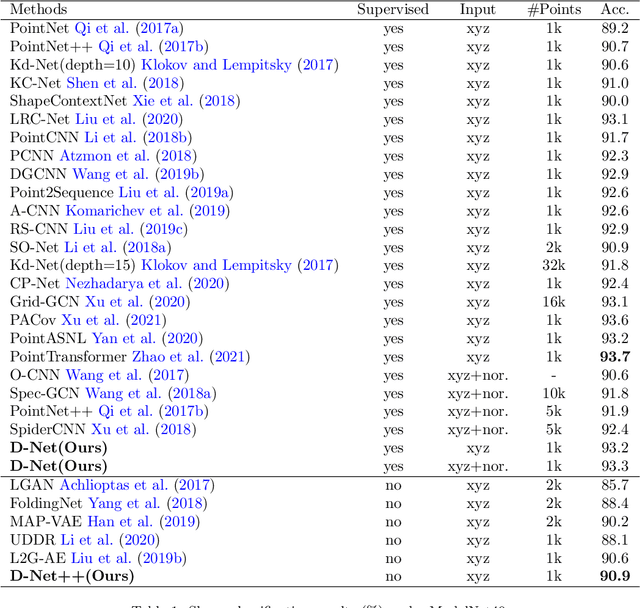
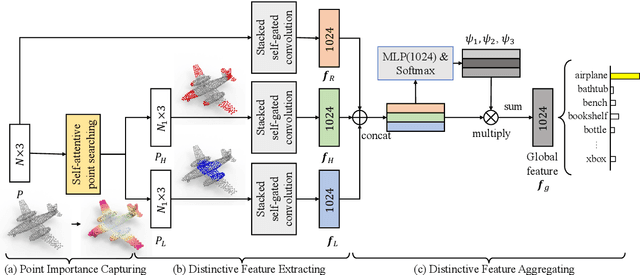
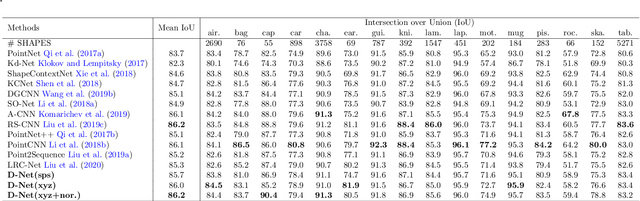
Learning and selecting important points on a point cloud is crucial for point cloud understanding in various applications. Most of early methods selected the important points on 3D shapes by analyzing the intrinsic geometric properties of every single shape, which fails to capture the importance of points that distinguishes a shape from objects of other classes, i.e., the distinction of points. To address this problem, we propose D-Net (Distinctive Network) to learn for distinctive point clouds based on a self-attentive point searching and a learnable feature fusion. Specifically, in the self-attentive point searching, we first learn the distinction score for each point to reveal the distinction distribution of the point cloud. After ranking the learned distinction scores, we group a point cloud into a high distinctive point set and a low distinctive one to enrich the fine-grained point cloud structure. To generate a compact feature representation for each distinctive point set, a stacked self-gated convolution is proposed to extract the distinctive features. Finally, we further introduce a learnable feature fusion mechanism to aggregate multiple distinctive features into a global point cloud representation in a channel-wise aggregation manner. The results also show that the learned distinction distribution of a point cloud is highly consistent with objects of the same class and different from objects of other classes. Extensive experiments on public datasets, including ModelNet and ShapeNet part dataset, demonstrate the ability to learn for distinctive point clouds, which helps to achieve the state-of-the-art performance in some shape understanding applications.
SPU-Net: Self-Supervised Point Cloud Upsampling by Coarse-to-Fine Reconstruction with Self-Projection Optimization
Dec 08, 2020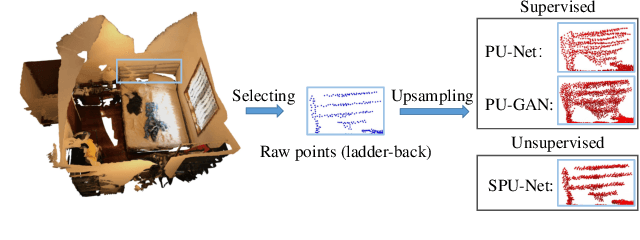
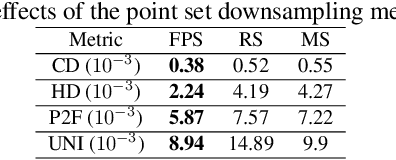
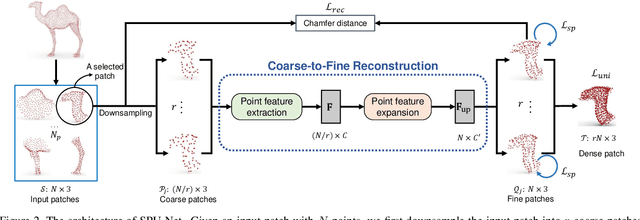
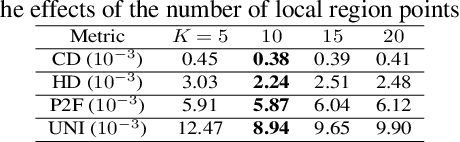
The task of point cloud upsampling aims to acquire dense and uniform point sets from sparse and irregular point sets. Although significant progress has been made with deep learning models, they require ground-truth dense point sets as the supervision information, which can only trained on synthetic paired training data and are not suitable for training under real-scanned sparse data. However, it is expensive and tedious to obtain large scale paired sparse-dense point sets for training from real scanned sparse data. To address this problem, we propose a self-supervised point cloud upsampling network, named SPU-Net, to capture the inherent upsampling patterns of points lying on the underlying object surface. Specifically, we propose a coarse-to-fine reconstruction framework, which contains two main components: point feature extraction and point feature expansion, respectively. In the point feature extraction, we integrate self-attention module with graph convolution network (GCN) to simultaneously capture context information inside and among local regions. In the point feature expansion, we introduce a hierarchically learnable folding strategy to generate the upsampled point sets with learnable 2D grids. Moreover, to further optimize the noisy points in the generated point sets, we propose a novel self-projection optimization associated with uniform and reconstruction terms, as a joint loss, to facilitate the self-supervised point cloud upsampling. We conduct various experiments on both synthetic and real-scanned datasets, and the results demonstrate that we achieve comparable performance to the state-of-the-art supervised methods.
Fine-Grained 3D Shape Classification with Hierarchical Part-View Attentions
May 26, 2020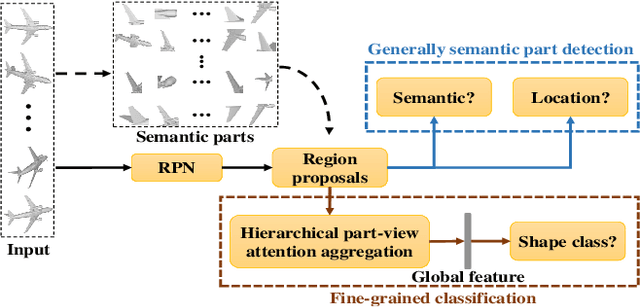
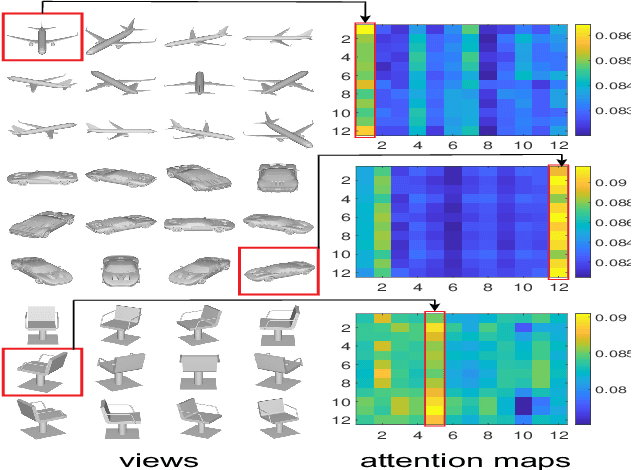
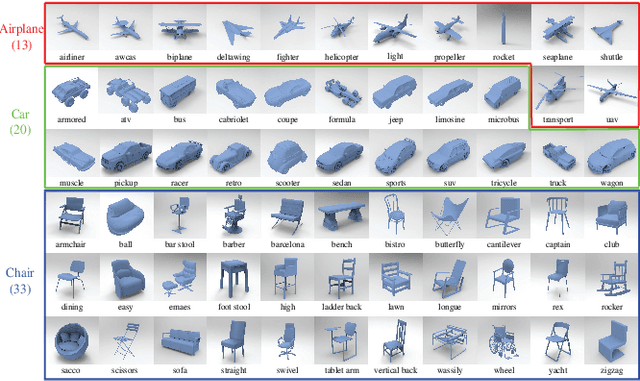
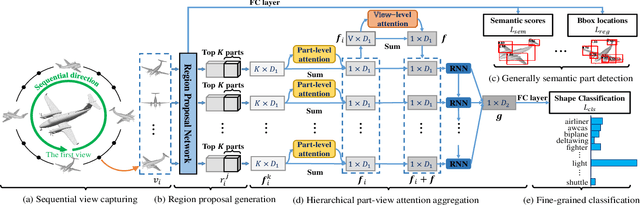
Fine-grained 3D shape classification is important and research challenging for shape understanding and analysis. However, due to the lack of fine-grained 3D shape benchmark, research on fine-grained 3D shape classification has rarely been explored. To address this issue, we first introduce a new dataset of fine-grained 3D shapes, which consists of three categories including airplane, car and chair. Each category consists of several subcategories at a fine-grained level. According to our experiments under this fine-grained dataset, we find that state-of-the-art methods are significantly limited by the small variance among subcategories in the same category. To resolve this problem, we further propose a novel fine-grained 3D shape classification method named FG3D-Net to capture the fine-grained local details of 3D shapes from multiple rendered views. Specifically, we first train a Region Proposal Network (RPN) to detect the generally semantic parts inside multiple views under the benchmark of generally semantic part detection. Then, we design a hierarchical part-view attention aggregation module to learn global shape representation by aggregating generally semantic part features, which preserves the local details of 3D shapes. The part-view attention module leverages a part-level attention and a view-level attention to increase the discriminative ability of features, where the part-level attention highlights the important parts in each view while the view-level attention highlights the discriminative views among all the views from the same object. In addition, we integrate the Recurrent Neural Network (RNN) to capture the spatial relationships among sequential views from different viewpoints. Our results under the fine-grained 3D shape dataset show that our method outperforms other state-of-the-art methods.
LRC-Net: Learning Discriminative Features on Point Clouds by Encoding Local Region Contexts
Mar 21, 2020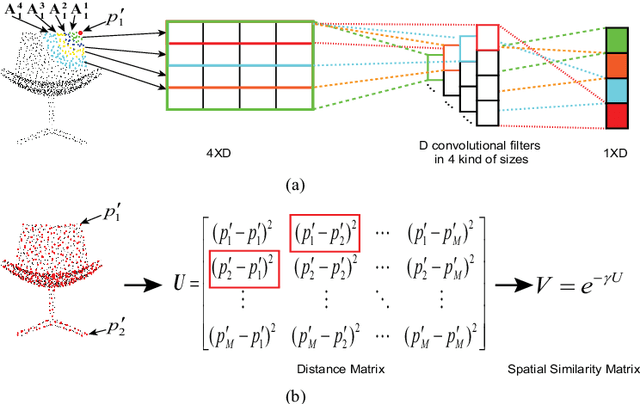
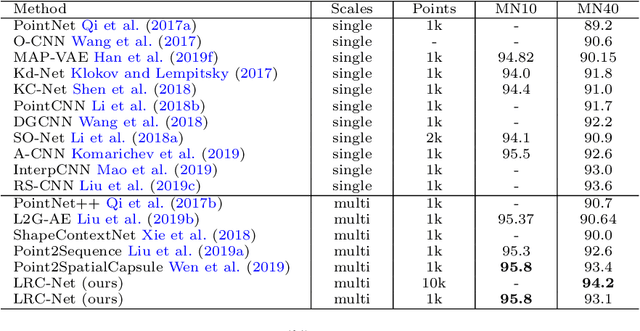
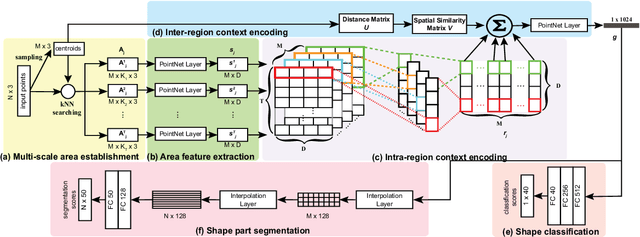
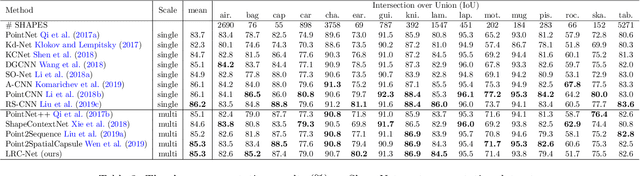
Learning discriminative feature directly on point clouds is still challenging in the understanding of 3D shapes. Recent methods usually partition point clouds into local region sets, and then extract the local region features with fixed-size CNN or MLP, and finally aggregate all individual local features into a global feature using simple max pooling. However, due to the irregularity and sparsity in sampled point clouds, it is hard to encode the fine-grained geometry of local regions and their spatial relationships when only using the fixed-size filters and individual local feature integration, which limit the ability to learn discriminative features. To address this issue, we present a novel Local-Region-Context Network (LRC-Net), to learn discriminative features on point clouds by encoding the fine-grained contexts inside and among local regions simultaneously. LRC-Net consists of two main modules. The first module, named intra-region context encoding, is designed for capturing the geometric correlation inside each local region by novel variable-size convolution filter. The second module, named inter-region context encoding, is proposed for integrating the spatial relationships among local regions based on spatial similarity measures. Experimental results show that LRC-Net is competitive with state-of-the-art methods in shape classification and shape segmentation applications.
LRC-Net: Learning Discriminative Features on Point Clouds by EncodingLocal Region Contexts
Mar 18, 2020Learning discriminative feature directly on point clouds is still challenging in the understanding of 3D shapes. Recent methods usually partition point clouds into local region sets, and then extract the local region features with fixed-size CNN or MLP, and finally aggregate all individual local features into a global feature using simple max pooling. However, due to the irregularity and sparsity in sampled point clouds, it is hard to encode the fine-grained geometry of local regions and their spatial relationships when only using the fixed-size filters and individual local feature integration, which limit the ability to learn discriminative features. To address this issue, we present a novel Local-Region-Context Network (LRC-Net), to learn discriminative features on point clouds by encoding the fine-grained contexts inside and among local regions simultaneously. LRC-Net consists of two main modules. The first module, named intra-region context encoding, is designed for capturing the geometric correlation inside each local region by novel variable-size convolution filter. The second module, named inter-region context encoding, is proposed for integrating the spatial relationships among local regions based on spatial similarity measures. Experimental results show that LRC-Net is competitive with state-of-the-art methods in shape classification and shape segmentation applications.
Point2SpatialCapsule: Aggregating Features and Spatial Relationships of Local Regions on Point Clouds using Spatial-aware Capsules
Aug 29, 2019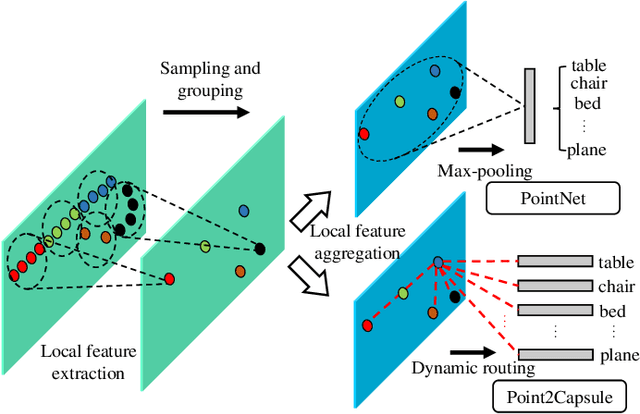


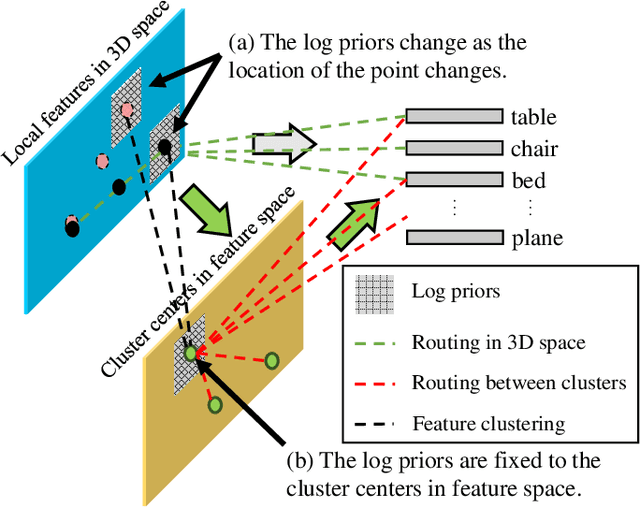
Learning discriminative shape representation directly on point clouds is still challenging in 3D shape analysis and understanding. Recent studies usually involve three steps: first splitting a point cloud into some local regions, then extracting corresponding feature of each local region, and finally aggregating all individual local region features into a global feature as shape representation using simple max pooling. However, such pooling-based feature aggregation methods do not adequately take the spatial relationships between local regions into account, which greatly limits the ability to learn discriminative shape representation. To address this issue, we propose a novel deep learning network, named Point2SpatialCapsule, for aggregating features and spatial relationships of local regions on point clouds, which aims to learn more discriminative shape representation. Compared with traditional max-pooling based feature aggregation networks, Point2SpatialCapsule can explicitly learn not only geometric features of local regions but also spatial relationships among them. It consists of two modules. To resolve the disorder problem of local regions, the first module, named geometric feature aggregation, is designed to aggregate the local region features into the learnable cluster centers, which explicitly encodes the spatial locations from the original 3D space. The second module, named spatial relationship aggregation, is proposed for further aggregating clustered features and the spatial relationships among them in the feature space using the spatial-aware capsules developed in this paper. Compared to the previous capsule network based methods, the feature routing on the spatial-aware capsules can learn more discriminative spatial relationships among local regions for point clouds, which establishes a direct mapping between log priors and the spatial locations through feature clusters.
L2G Auto-encoder: Understanding Point Clouds by Local-to-Global Reconstruction with Hierarchical Self-Attention
Aug 02, 2019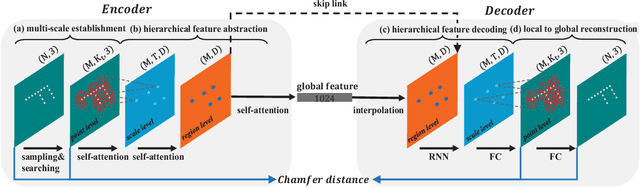

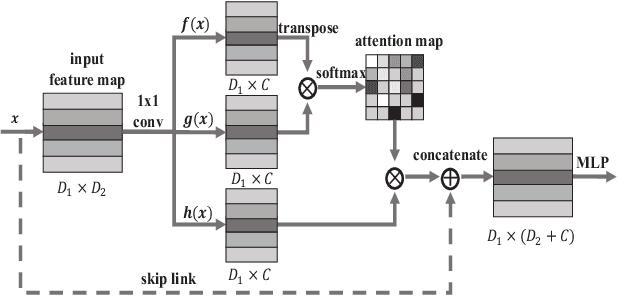
Auto-encoder is an important architecture to understand point clouds in an encoding and decoding procedure of self reconstruction. Current auto-encoder mainly focuses on the learning of global structure by global shape reconstruction, while ignoring the learning of local structures. To resolve this issue, we propose Local-to-Global auto-encoder (L2G-AE) to simultaneously learn the local and global structure of point clouds by local to global reconstruction. Specifically, L2G-AE employs an encoder to encode the geometry information of multiple scales in a local region at the same time. In addition, we introduce a novel hierarchical self-attention mechanism to highlight the important points, scales and regions at different levels in the information aggregation of the encoder. Simultaneously, L2G-AE employs a recurrent neural network (RNN) as decoder to reconstruct a sequence of scales in a local region, based on which the global point cloud is incrementally reconstructed. Our outperforming results in shape classification, retrieval and upsampling show that L2G-AE can understand point clouds better than state-of-the-art methods.
Parts4Feature: Learning 3D Global Features from Generally Semantic Parts in Multiple Views
May 18, 2019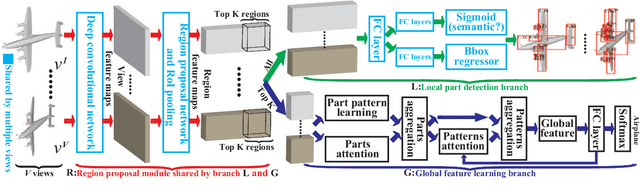
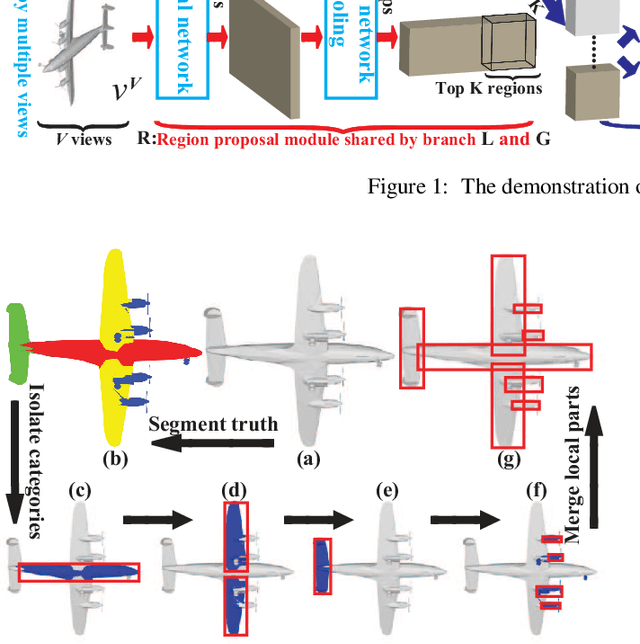

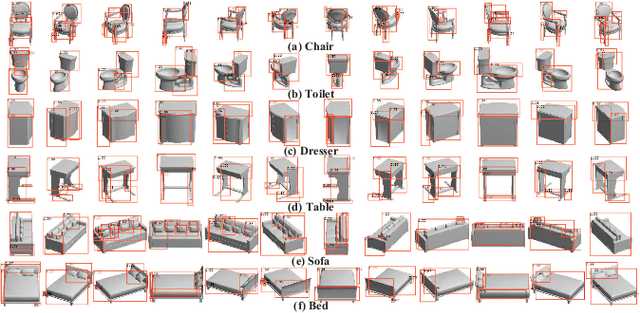
Deep learning has achieved remarkable results in 3D shape analysis by learning global shape features from the pixel-level over multiple views. Previous methods, however, compute low-level features for entire views without considering part-level information. In contrast, we propose a deep neural network, called Parts4Feature, to learn 3D global features from part-level information in multiple views. We introduce a novel definition of generally semantic parts, which Parts4Feature learns to detect in multiple views from different 3D shape segmentation benchmarks. A key idea of our architecture is that it transfers the ability to detect semantically meaningful parts in multiple views to learn 3D global features. Parts4Feature achieves this by combining a local part detection branch and a global feature learning branch with a shared region proposal module. The global feature learning branch aggregates the detected parts in terms of learned part patterns with a novel multi-attention mechanism, while the region proposal module enables locally and globally discriminative information to be promoted by each other. We demonstrate that Parts4Feature outperforms the state-of-the-art under three large-scale 3D shape benchmarks.
Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network
Nov 15, 2018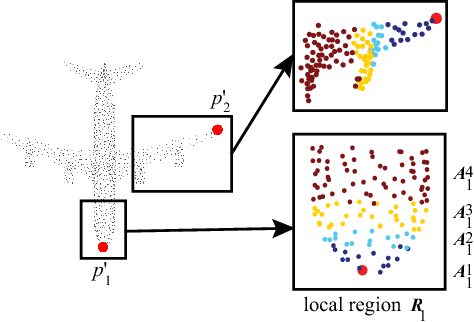
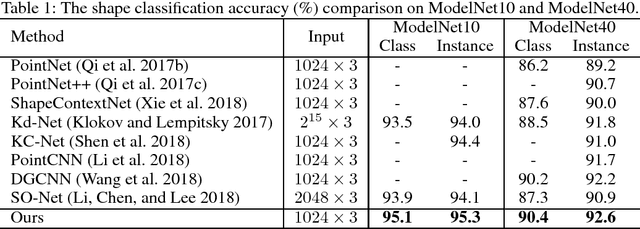
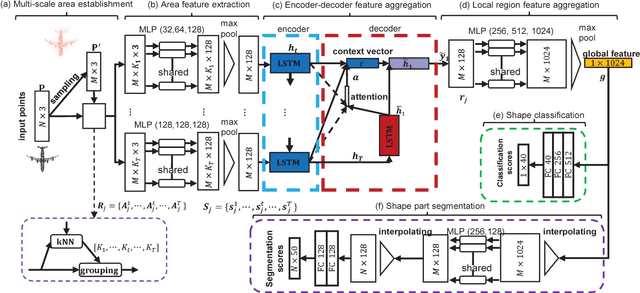
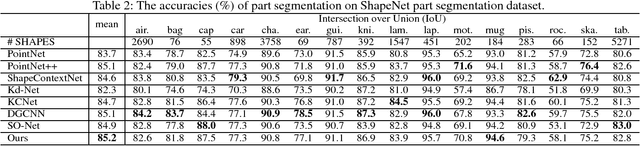
Exploring contextual information in the local region is important for shape understanding and analysis. Existing studies often employ hand-crafted or explicit ways to encode contextual information of local regions. However, it is hard to capture fine-grained contextual information in hand-crafted or explicit manners, such as the correlation between different areas in a local region, which limits the discriminative ability of learned features. To resolve this issue, we propose a novel deep learning model for 3D point clouds, named Point2Sequence, to learn 3D shape features by capturing fine-grained contextual information in a novel implicit way. Point2Sequence employs a novel sequence learning model for point clouds to capture the correlations by aggregating multi-scale areas of each local region with attention. Specifically, Point2Sequence first learns the feature of each area scale in a local region. Then, it captures the correlation between area scales in the process of aggregating all area scales using a recurrent neural network (RNN) based encoder-decoder structure, where an attention mechanism is proposed to highlight the importance of different area scales. Experimental results show that Point2Sequence achieves state-of-the-art performance in shape classification and segmentation tasks.