 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXintong Li
Geometry-Aware Adaptation for Pretrained Models
Jul 23, 2023

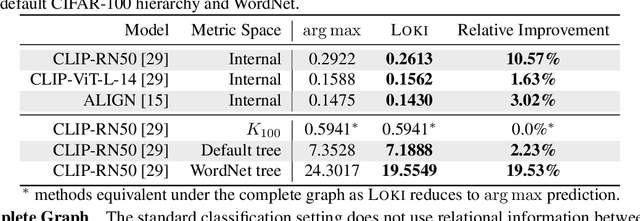
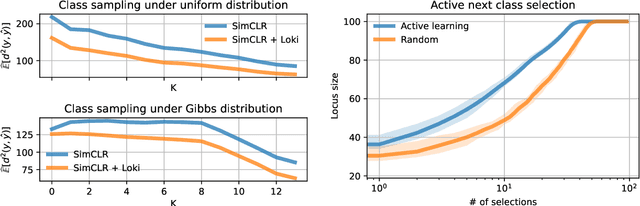
Machine learning models -- including prominent zero-shot models -- are often trained on datasets whose labels are only a small proportion of a larger label space. Such spaces are commonly equipped with a metric that relates the labels via distances between them. We propose a simple approach to exploit this information to adapt the trained model to reliably predict new classes -- or, in the case of zero-shot prediction, to improve its performance -- without any additional training. Our technique is a drop-in replacement of the standard prediction rule, swapping argmax with the Fr\'echet mean. We provide a comprehensive theoretical analysis for this approach, studying (i) learning-theoretic results trading off label space diameter, sample complexity, and model dimension, (ii) characterizations of the full range of scenarios in which it is possible to predict any unobserved class, and (iii) an optimal active learning-like next class selection procedure to obtain optimal training classes for when it is not possible to predict the entire range of unobserved classes. Empirically, using easily-available external metrics, our proposed approach, Loki, gains up to 29.7% relative improvement over SimCLR on ImageNet and scales to hundreds of thousands of classes. When no such metric is available, Loki can use self-derived metrics from class embeddings and obtains a 10.5% improvement on pretrained zero-shot models such as CLIP.
Cascaded Logic Gates Based on High-Performance Ambipolar Dual-Gate WSe2 Thin Film Transistors
May 02, 2023



Ambipolar dual-gate transistors based on two-dimensional (2D) materials, such as graphene, carbon nanotubes, black phosphorus, and certain transition metal dichalcogenides (TMDs), enable reconfigurable logic circuits with suppressed off-state current. These circuits achieve the same logical output as CMOS with fewer transistors and offer greater flexibility in design. The primary challenge lies in the cascadability and power consumption of these logic gates with static CMOS-like connections. In this article, high-performance ambipolar dual-gate transistors based on tungsten diselenide (WSe2) are fabricated. A high on-off ratio of 10^8 and 10^6, a low off-state current of 100 to 300 fA, a negligible hysteresis, and an ideal subthreshold swing of 62 and 63 mV/dec are measured in the p- and n-type transport, respectively. For the first time, we demonstrate cascadable and cascaded logic gates using ambipolar TMD transistors with minimal static power consumption, including inverters, XOR, NAND, NOR, and buffers made by cascaded inverters. A thorough study of both the control gate and polarity gate behavior is conducted, which has previously been lacking. The noise margin of the logic gates is measured and analyzed. The large noise margin enables the implementation of VT-drop circuits, a type of logic with reduced transistor number and simplified circuit design. Finally, the speed performance of the VT-drop and other circuits built by dual-gate devices are qualitatively analyzed. This work lays the foundation for future developments in the field of ambipolar dual-gate TMD transistors, showing their potential for low-power, high-speed and more flexible logic circuits.
AutoWS-Bench-101: Benchmarking Automated Weak Supervision with 100 Labels
Aug 30, 2022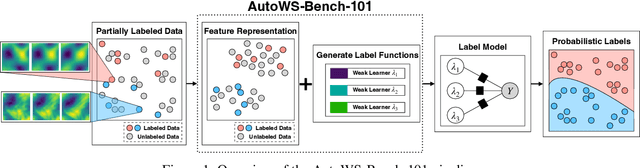
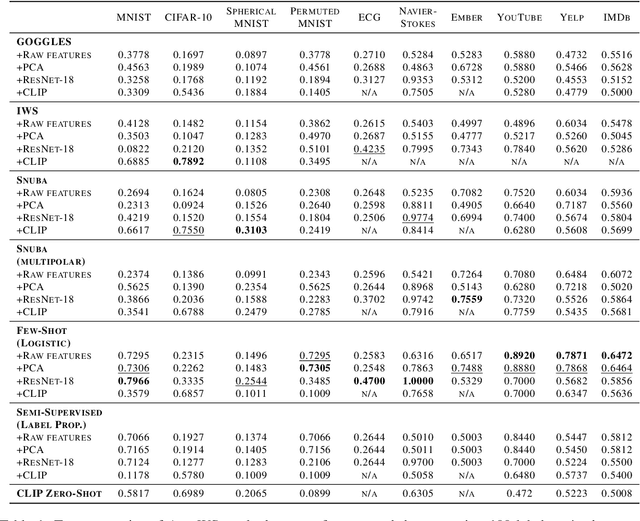
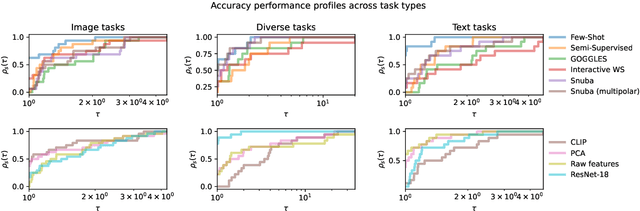

Weak supervision (WS) is a powerful method to build labeled datasets for training supervised models in the face of little-to-no labeled data. It replaces hand-labeling data with aggregating multiple noisy-but-cheap label estimates expressed by labeling functions (LFs). While it has been used successfully in many domains, weak supervision's application scope is limited by the difficulty of constructing labeling functions for domains with complex or high-dimensional features. To address this, a handful of methods have proposed automating the LF design process using a small set of ground truth labels. In this work, we introduce AutoWS-Bench-101: a framework for evaluating automated WS (AutoWS) techniques in challenging WS settings -- a set of diverse application domains on which it has been previously difficult or impossible to apply traditional WS techniques. While AutoWS is a promising direction toward expanding the application-scope of WS, the emergence of powerful methods such as zero-shot foundation models reveals the need to understand how AutoWS techniques compare or cooperate with modern zero-shot or few-shot learners. This informs the central question of AutoWS-Bench-101: given an initial set of 100 labels for each task, we ask whether a practitioner should use an AutoWS method to generate additional labels or use some simpler baseline, such as zero-shot predictions from a foundation model or supervised learning. We observe that in many settings, it is necessary for AutoWS methods to incorporate signal from foundation models if they are to outperform simple few-shot baselines, and AutoWS-Bench-101 promotes future research in this direction. We conclude with a thorough ablation study of AutoWS methods.
PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit
May 20, 2022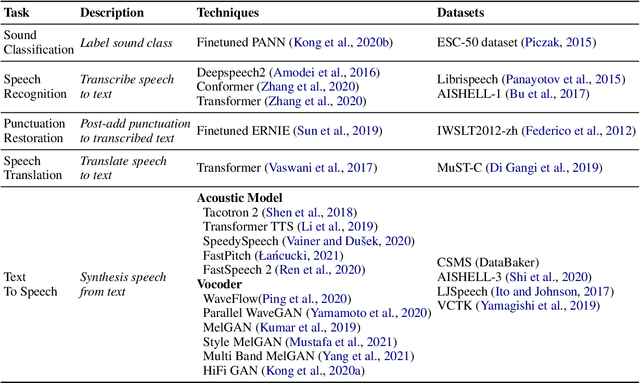
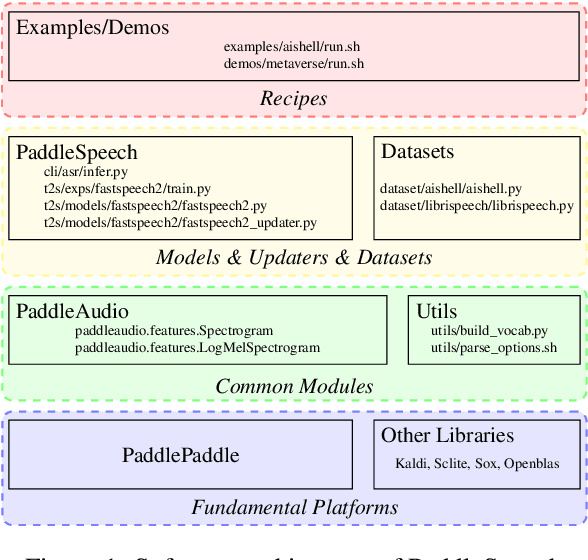
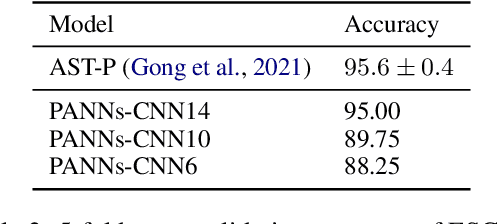
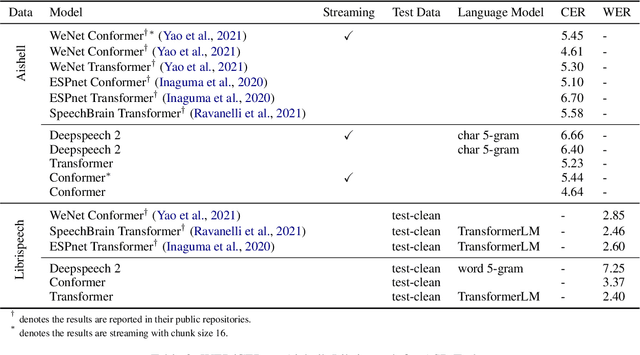
PaddleSpeech is an open-source all-in-one speech toolkit. It aims at facilitating the development and research of speech processing technologies by providing an easy-to-use command-line interface and a simple code structure. This paper describes the design philosophy and core architecture of PaddleSpeech to support several essential speech-to-text and text-to-speech tasks. PaddleSpeech achieves competitive or state-of-the-art performance on various speech datasets and implements the most popular methods. It also provides recipes and pretrained models to quickly reproduce the experimental results in this paper. PaddleSpeech is publicly avaiable at https://github.com/PaddlePaddle/PaddleSpeech.
A$^3$T: Alignment-Aware Acoustic and Text Pretraining for Speech Synthesis and Editing
Mar 18, 2022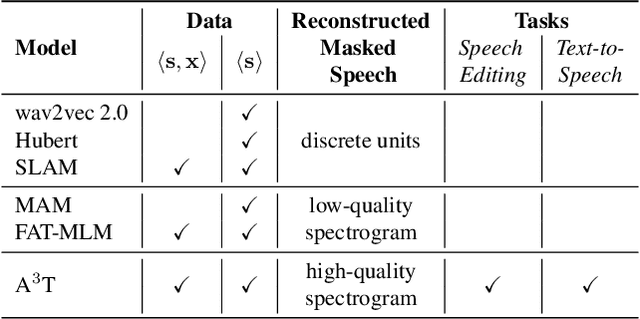
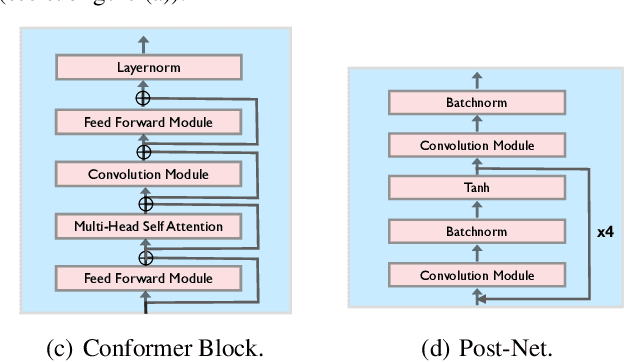

Recently, speech representation learning has improved many speech-related tasks such as speech recognition, speech classification, and speech-to-text translation. However, all the above tasks are in the direction of speech understanding, but for the inverse direction, speech synthesis, the potential of representation learning is yet to be realized, due to the challenging nature of generating high-quality speech. To address this problem, we propose our framework, Alignment-Aware Acoustic-Text Pretraining (A$^3$T), which reconstructs masked acoustic signals with text input and acoustic-text alignment during training. In this way, the pretrained model can generate high quality of reconstructed spectrogram, which can be applied to the speech editing and unseen speaker TTS directly. Experiments show A$^3$T outperforms SOTA models on speech editing, and improves multi-speaker speech synthesis without the external speaker verification model.
A State-of-the-art Survey of U-Net in Microscopic Image Analysis: from Simple Usage to Structure Mortification
Feb 14, 2022



Image analysis technology is used to solve the inadvertences of artificial traditional methods in disease, wastewater treatment, environmental change monitoring analysis and convolutional neural networks (CNN) play an important role in microscopic image analysis. An important step in detection, tracking, monitoring, feature extraction, modeling and analysis is image segmentation, in which U-Net has increasingly applied in microscopic image segmentation. This paper comprehensively reviews the development history of U-Net, and analyzes various research results of various segmentation methods since the emergence of U-Net and conducts a comprehensive review of related papers. First, This paper has summarizes the improved methods of U-Net and then listed the existing significances of image segmentation techniques and their improvements that has introduced over the years. Finally, focusing on the different improvement strategies of U-Net in different papers, the related work of each application target is reviewed according to detailed technical categories to facilitate future research. Researchers can clearly see the dynamics of transmission of technological development and keep up with future trends in this interdisciplinary field.
What Can Machine Vision Do for Lymphatic Histopathology Image Analysis: A Comprehensive Review
Jan 21, 2022



In the past ten years, the computing power of machine vision (MV) has been continuously improved, and image analysis algorithms have developed rapidly. At the same time, histopathological slices can be stored as digital images. Therefore, MV algorithms can provide doctors with diagnostic references. In particular, the continuous improvement of deep learning algorithms has further improved the accuracy of MV in disease detection and diagnosis. This paper reviews the applications of image processing technology based on MV in lymphoma histopathological images in recent years, including segmentation, classification and detection. Finally, the current methods are analyzed, some more potential methods are proposed, and further prospects are made.
A State-of-the-art Survey of Artificial Neural Networks for Whole-slide Image Analysis:from Popular Convolutional Neural Networks to Potential Visual Transformers
May 04, 2021



In recent years, with the advancement of computer-aided diagnosis (CAD) technology and whole slide image (WSI), histopathological WSI has gradually played a crucial aspect in the diagnosis and analysis of diseases. To increase the objectivity and accuracy of pathologists' work, artificial neural network (ANN) methods have been generally needed in the segmentation, classification, and detection of histopathological WSI. In this paper, WSI analysis methods based on ANN are reviewed. Firstly, the development status of WSI and ANN methods is introduced. Secondly, we summarize the common ANN methods. Next, we discuss publicly available WSI datasets and evaluation metrics. These ANN architectures for WSI processing are divided into classical neural networks and deep neural networks (DNNs) and then analyzed. Finally, the application prospect of the analytical method in this field is discussed. The important potential method is Visual Transformers.
A Comprehensive Review of Computer-aided Whole-slide Image Analysis: from Datasets to Feature Extraction, Segmentation, Classification, and Detection Approaches
Feb 21, 2021



With the development of computer-aided diagnosis (CAD) and image scanning technology, Whole-slide Image (WSI) scanners are widely used in the field of pathological diagnosis. Therefore, WSI analysis has become the key to modern digital pathology. Since 2004, WSI has been used more and more in CAD. Since machine vision methods are usually based on semi-automatic or fully automatic computers, they are highly efficient and labor-saving. The combination of WSI and CAD technologies for segmentation, classification, and detection helps histopathologists obtain more stable and quantitative analysis results, save labor costs and improve diagnosis objectivity. This paper reviews the methods of WSI analysis based on machine learning. Firstly, the development status of WSI and CAD methods are introduced. Secondly, we discuss publicly available WSI datasets and evaluation metrics for segmentation, classification, and detection tasks. Then, the latest development of machine learning in WSI segmentation, classification, and detection are reviewed continuously. Finally, the existing methods are studied, the applicabilities of the analysis methods are analyzed, and the application prospects of the analysis methods in this field are forecasted.
Machine-learning classifiers for logographic name matching in public health applications: approaches for incorporating phonetic, visual, and keystroke similarity in large-scale probabilistic record linkage
Jan 07, 2020



Approximate string-matching methods to account for complex variation in highly discriminatory text fields, such as personal names, can enhance probabilistic record linkage. However, discriminating between matching and non-matching strings is challenging for logographic scripts, where similarities in pronunciation, appearance, or keystroke sequence are not directly encoded in the string data. We leverage a large Chinese administrative dataset with known match status to develop logistic regression and Xgboost classifiers integrating measures of visual, phonetic, and keystroke similarity to enhance identification of potentially-matching name pairs. We evaluate three methods of leveraging name similarity scores in large-scale probabilistic record linkage, which can adapt to varying match prevalence and information in supporting fields: (1) setting a threshold score based on predicted quality of name-matching across all record pairs; (2) setting a threshold score based on predicted discriminatory power of the linkage model; and (3) using empirical score distributions among matches and nonmatches to perform Bayesian adjustment of matching probabilities estimated from exact-agreement linkage. In experiments on holdout data, as well as data simulated with varying name error rates and supporting fields, a logistic regression classifier incorporated via the Bayesian method demonstrated marked improvements over exact-agreement linkage with respect to discriminatory power, match probability estimation, and accuracy, reducing the total number of misclassified record pairs by 21% in test data and up to an average of 93% in simulated datasets. Our results demonstrate the value of incorporating visual, phonetic, and keystroke similarity for logographic name matching, as well as the promise of our Bayesian approach to leverage name-matching within large-scale record linkage.