 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinyue Ye
On the Promises and Challenges of Multimodal Foundation Models for Geographical, Environmental, Agricultural, and Urban Planning Applications
Dec 23, 2023
The advent of large language models (LLMs) has heightened interest in their potential for multimodal applications that integrate language and vision. This paper explores the capabilities of GPT-4V in the realms of geography, environmental science, agriculture, and urban planning by evaluating its performance across a variety of tasks. Data sources comprise satellite imagery, aerial photos, ground-level images, field images, and public datasets. The model is evaluated on a series of tasks including geo-localization, textual data extraction from maps, remote sensing image classification, visual question answering, crop type identification, disease/pest/weed recognition, chicken behavior analysis, agricultural object counting, urban planning knowledge question answering, and plan generation. The results indicate the potential of GPT-4V in geo-localization, land cover classification, visual question answering, and basic image understanding. However, there are limitations in several tasks requiring fine-grained recognition and precise counting. While zero-shot learning shows promise, performance varies across problem domains and image complexities. The work provides novel insights into GPT-4V's capabilities and limitations for real-world geospatial, environmental, agricultural, and urban planning challenges. Further research should focus on augmenting the model's knowledge and reasoning for specialized domains through expanded training. Overall, the analysis demonstrates foundational multimodal intelligence, highlighting the potential of multimodal foundation models (FMs) to advance interdisciplinary applications at the nexus of computer vision and language.
Extracting human emotions at different places based on facial expressions and spatial clustering analysis
May 06, 2019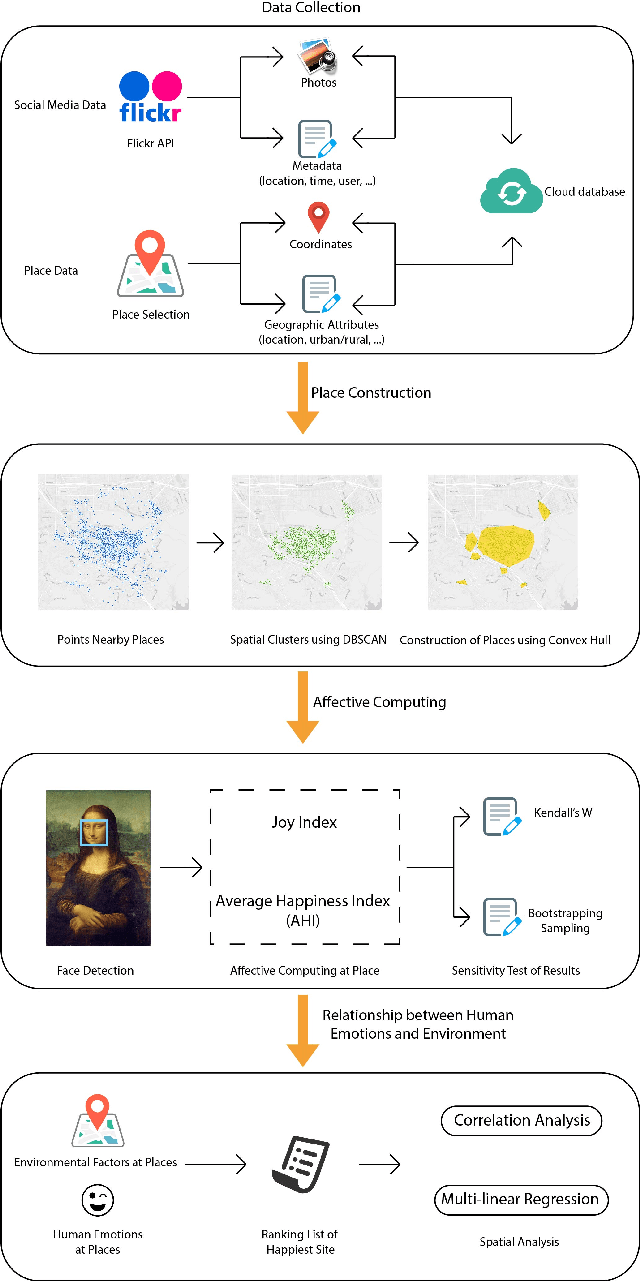
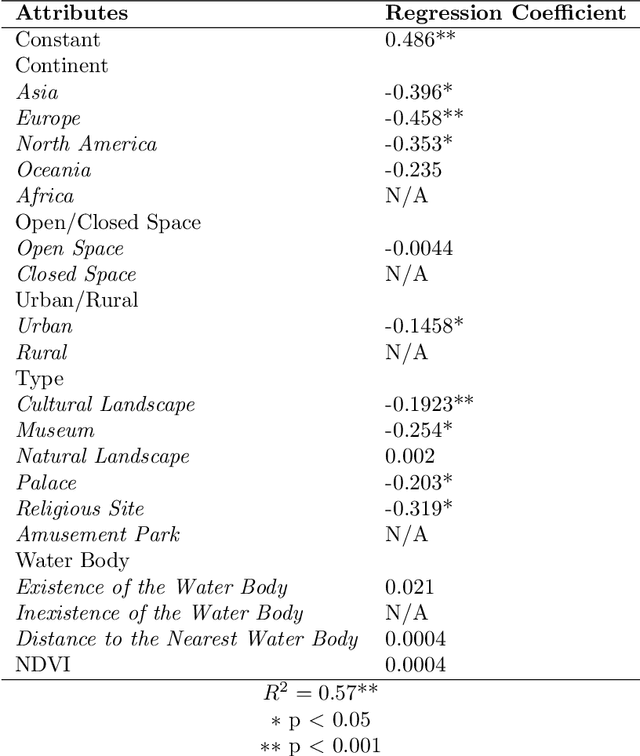
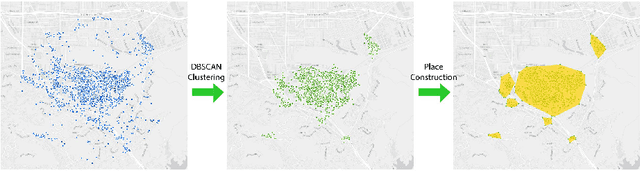
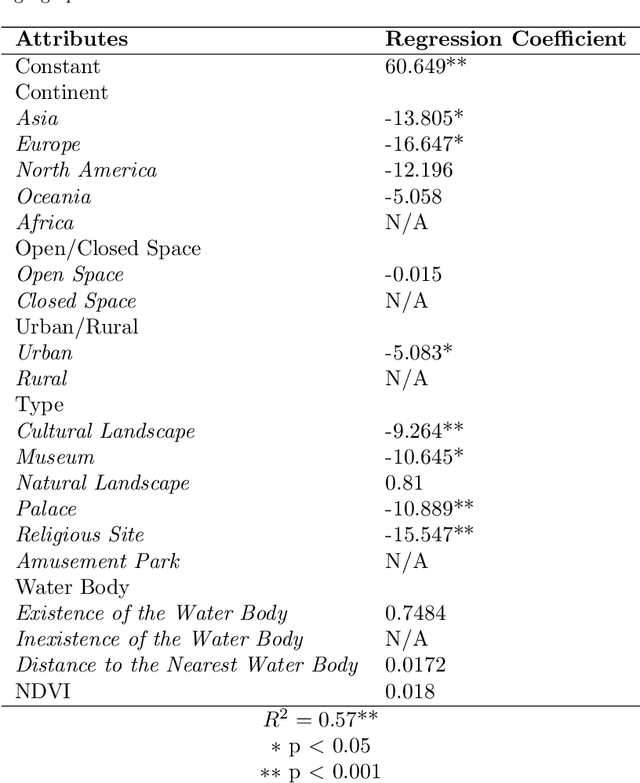
The emergence of big data enables us to evaluate the various human emotions at places from a statistic perspective by applying affective computing. In this study, a novel framework for extracting human emotions from large-scale georeferenced photos at different places is proposed. After the construction of places based on spatial clustering of user generated footprints collected in social media websites, online cognitive services are utilized to extract human emotions from facial expressions using the state-of-the-art computer vision techniques. And two happiness metrics are defined for measuring the human emotions at different places. To validate the feasibility of the framework, we take 80 tourist attractions around the world as an example and a happiness ranking list of places is generated based on human emotions calculated over 2 million faces detected out from over 6 million photos. Different kinds of geographical contexts are taken into consideration to find out the relationship between human emotions and environmental factors. Results show that much of the emotional variation at different places can be explained by a few factors such as openness. The research may offer insights on integrating human emotions to enrich the understanding of sense of place in geography and in place-based GIS.
* 40 pages; 9 figures
Extracting and Analyzing Semantic Relatedness between Cities Using News Articles
Sep 08, 2018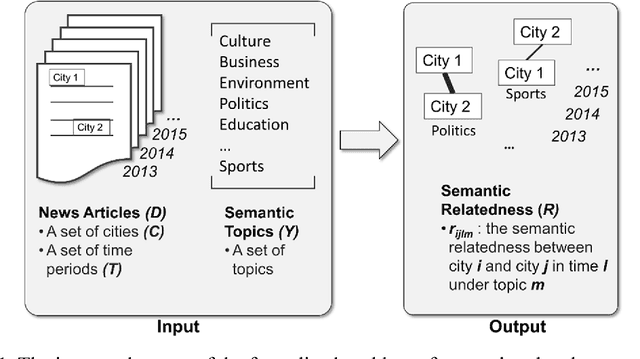
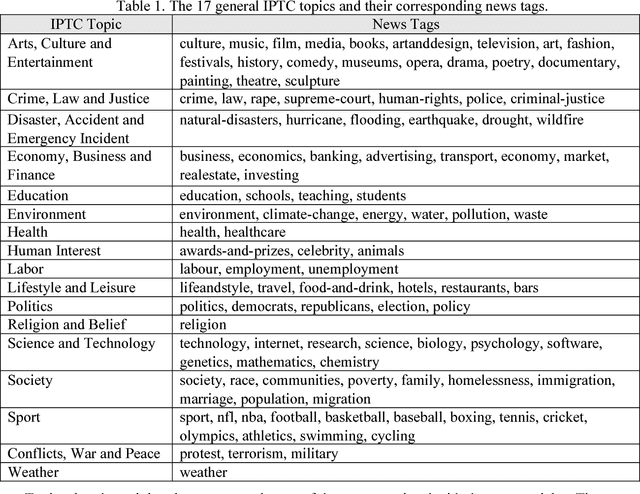
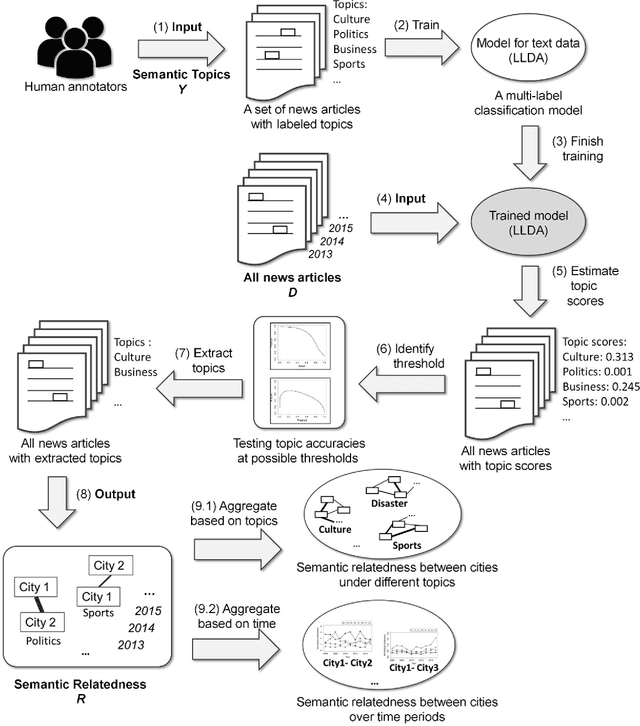
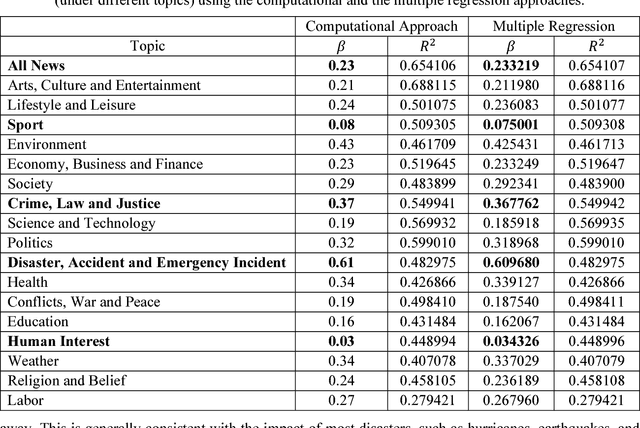
News articles capture a variety of topics about our society. They reflect not only the socioeconomic activities that happened in our physical world, but also some of the cultures, human interests, and public concerns that exist only in the perceptions of people. Cities are frequently mentioned in news articles, and two or more cities may co-occur in the same article. Such co-occurrence often suggests certain relatedness between the mentioned cities, and the relatedness may be under different topics depending on the contents of the news articles. We consider the relatedness under different topics as semantic relatedness. By reading news articles, one can grasp the general semantic relatedness between cities, yet, given hundreds of thousands of news articles, it is very difficult, if not impossible, for anyone to manually read them. This paper proposes a computational framework which can "read" a large number of news articles and extract the semantic relatedness between cities. This framework is based on a natural language processing model and employs a machine learning process to identify the main topics of news articles. We describe the overall structure of this framework and its individual modules, and then apply it to an experimental dataset with more than 500,000 news articles covering the top 100 U.S. cities spanning a 10-year period. We perform exploratory visualization of the extracted semantic relatedness under different topics and over multiple years. We also analyze the impact of geographic distance on semantic relatedness and find varied distance decay effects. The proposed framework can be used to support large-scale content analysis in city network research.