 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXuebin Ren
FedLED: Label-Free Equipment Fault Diagnosis with Vertical Federated Transfer Learning
Dec 29, 2023
Intelligent equipment fault diagnosis based on Federated Transfer Learning (FTL) attracts considerable attention from both academia and industry. It allows real-world industrial agents with limited samples to construct a fault diagnosis model without jeopardizing their raw data privacy. Existing approaches, however, can neither address the intense sample heterogeneity caused by different working conditions of practical agents, nor the extreme fault label scarcity, even zero, of newly deployed equipment. To address these issues, we present FedLED, the first unsupervised vertical FTL equipment fault diagnosis method, where knowledge of the unlabeled target domain is further exploited for effective unsupervised model transfer. Results of extensive experiments using data of real equipment monitoring demonstrate that FedLED obviously outperforms SOTA approaches in terms of both diagnosis accuracy (up to 4.13 times) and generality. We expect our work to inspire further study on label-free equipment fault diagnosis systematically enhanced by target domain knowledge.
Exploring the Benefits of Visual Prompting in Differential Privacy
Mar 22, 2023
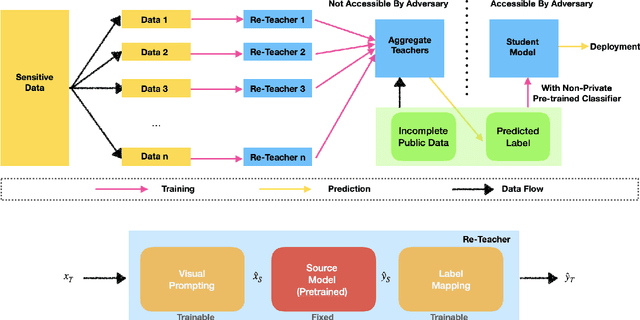
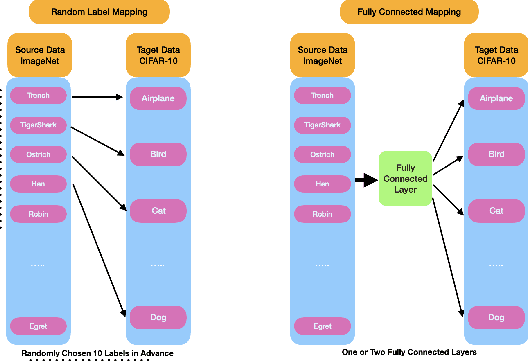

Visual Prompting (VP) is an emerging and powerful technique that allows sample-efficient adaptation to downstream tasks by engineering a well-trained frozen source model. In this work, we explore the benefits of VP in constructing compelling neural network classifiers with differential privacy (DP). We explore and integrate VP into canonical DP training methods and demonstrate its simplicity and efficiency. In particular, we discover that VP in tandem with PATE, a state-of-the-art DP training method that leverages the knowledge transfer from an ensemble of teachers, achieves the state-of-the-art privacy-utility trade-off with minimum expenditure of privacy budget. Moreover, we conduct additional experiments on cross-domain image classification with a sufficient domain gap to further unveil the advantage of VP in DP. Lastly, we also conduct extensive ablation studies to validate the effectiveness and contribution of VP under DP consideration.
Towards Efficient and Stable K-Asynchronous Federated Learning with Unbounded Stale Gradients on Non-IID Data
Mar 02, 2022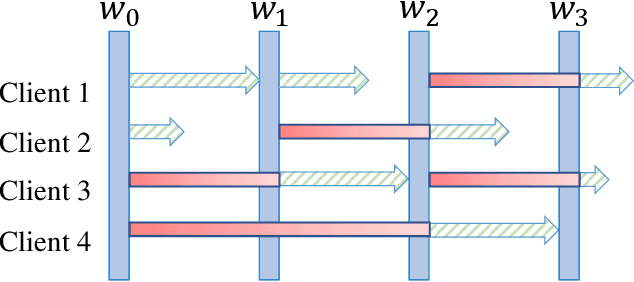

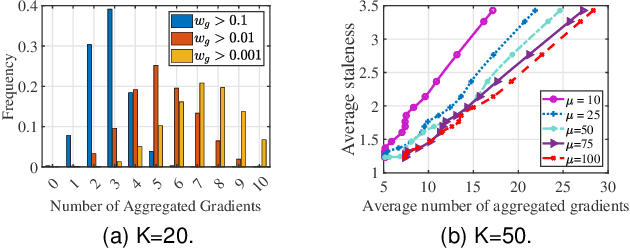
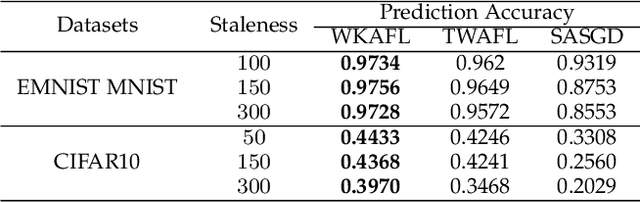
Federated learning (FL) is an emerging privacy-preserving paradigm that enables multiple participants collaboratively to train a global model without uploading raw data. Considering heterogeneous computing and communication capabilities of different participants, asynchronous FL can avoid the stragglers effect in synchronous FL and adapts to scenarios with vast participants. Both staleness and non-IID data in asynchronous FL would reduce the model utility. However, there exists an inherent contradiction between the solutions to the two problems. That is, mitigating the staleness requires to select less but consistent gradients while coping with non-IID data demands more comprehensive gradients. To address the dilemma, this paper proposes a two-stage weighted $K$ asynchronous FL with adaptive learning rate (WKAFL). By selecting consistent gradients and adjusting learning rate adaptively, WKAFL utilizes stale gradients and mitigates the impact of non-IID data, which can achieve multifaceted enhancement in training speed, prediction accuracy and training stability. We also present the convergence analysis for WKAFL under the assumption of unbounded staleness to understand the impact of staleness and non-IID data. Experiments implemented on both benchmark and synthetic FL datasets show that WKAFL has better overall performance compared to existing algorithms.
Latent Dirichlet Allocation Model Training with Differential Privacy
Oct 09, 2020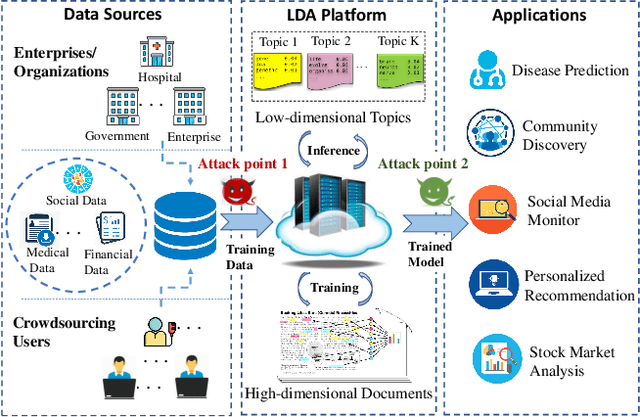
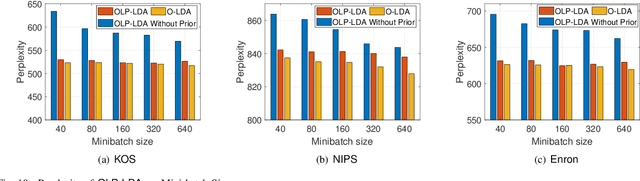
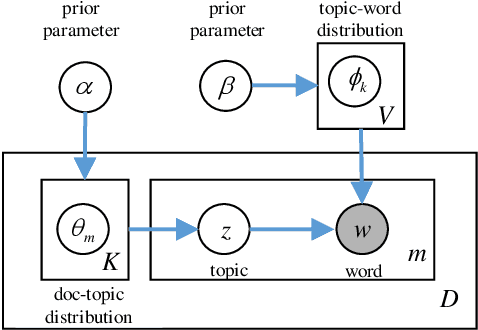
Latent Dirichlet Allocation (LDA) is a popular topic modeling technique for hidden semantic discovery of text data and serves as a fundamental tool for text analysis in various applications. However, the LDA model as well as the training process of LDA may expose the text information in the training data, thus bringing significant privacy concerns. To address the privacy issue in LDA, we systematically investigate the privacy protection of the main-stream LDA training algorithm based on Collapsed Gibbs Sampling (CGS) and propose several differentially private LDA algorithms for typical training scenarios. In particular, we present the first theoretical analysis on the inherent differential privacy guarantee of CGS based LDA training and further propose a centralized privacy-preserving algorithm (HDP-LDA) that can prevent data inference from the intermediate statistics in the CGS training. Also, we propose a locally private LDA training algorithm (LP-LDA) on crowdsourced data to provide local differential privacy for individual data contributors. Furthermore, we extend LP-LDA to an online version as OLP-LDA to achieve LDA training on locally private mini-batches in a streaming setting. Extensive analysis and experiment results validate both the effectiveness and efficiency of our proposed privacy-preserving LDA training algorithms.
OL4EL: Online Learning for Edge-cloud Collaborative Learning on Heterogeneous Edges with Resource Constraints
Apr 23, 2020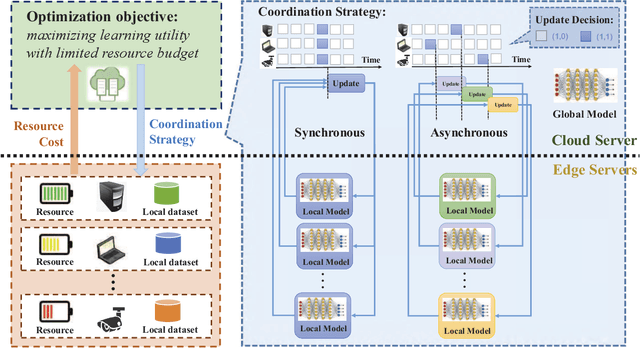
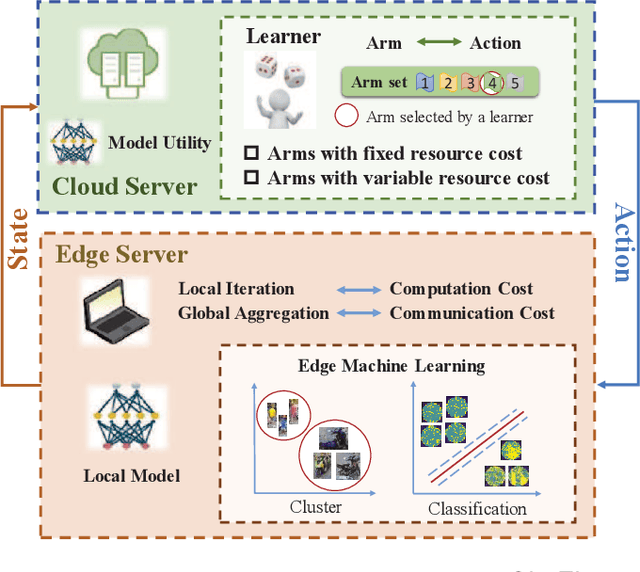
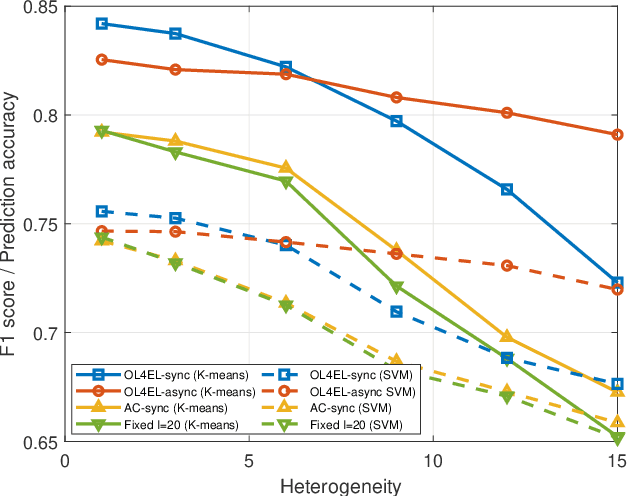
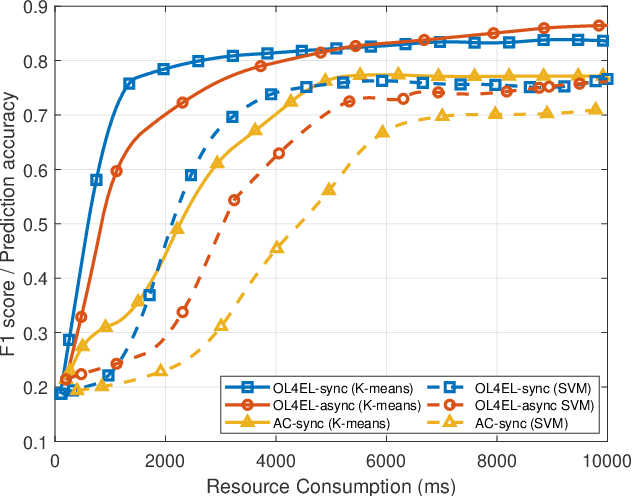
Distributed machine learning (ML) at network edge is a promising paradigm that can preserve both network bandwidth and privacy of data providers. However, heterogeneous and limited computation and communication resources on edge servers (or edges) pose great challenges on distributed ML and formulate a new paradigm of Edge Learning (i.e. edge-cloud collaborative machine learning). In this article, we propose a novel framework of 'learning to learn' for effective Edge Learning (EL) on heterogeneous edges with resource constraints. We first model the dynamic determination of collaboration strategy (i.e. the allocation of local iterations at edge servers and global aggregations on the Cloud during collaborative learning process) as an online optimization problem to achieve the tradeoff between the performance of EL and the resource consumption of edge servers. Then, we propose an Online Learning for EL (OL4EL) framework based on the budget-limited multi-armed bandit model. OL4EL supports both synchronous and asynchronous learning patterns, and can be used for both supervised and unsupervised learning tasks. To evaluate the performance of OL4EL, we conducted both real-world testbed experiments and extensive simulations based on docker containers, where both Support Vector Machine and K-means were considered as use cases. Experimental results demonstrate that OL4EL significantly outperforms state-of-the-art EL and other collaborative ML approaches in terms of the trade-off between learning performance and resource consumption.
Asynchronous Federated Learning with Differential Privacy for Edge Intelligence
Dec 17, 2019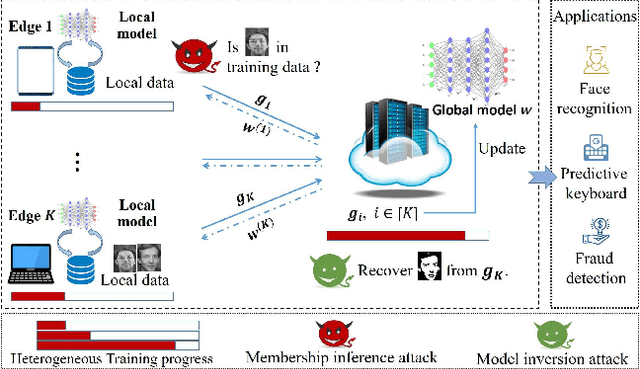

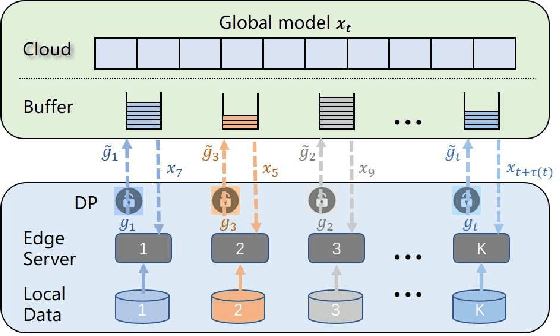

Federated learning has been showing as a promising approach in paving the last mile of artificial intelligence, due to its great potential of solving the data isolation problem in large scale machine learning. Particularly, with consideration of the heterogeneity in practical edge computing systems, asynchronous edge-cloud collaboration based federated learning can further improve the learning efficiency by significantly reducing the straggler effect. Despite no raw data sharing, the open architecture and extensive collaborations of asynchronous federated learning (AFL) still give some malicious participants great opportunities to infer other parties' training data, thus leading to serious concerns of privacy. To achieve a rigorous privacy guarantee with high utility, we investigate to secure asynchronous edge-cloud collaborative federated learning with differential privacy, focusing on the impacts of differential privacy on model convergence of AFL. Formally, we give the first analysis on the model convergence of AFL under DP and propose a multi-stage adjustable private algorithm (MAPA) to improve the trade-off between model utility and privacy by dynamically adjusting both the noise scale and the learning rate. Through extensive simulations and real-world experiments with an edge-could testbed, we demonstrate that MAPA significantly improves both the model accuracy and convergence speed with sufficient privacy guarantee.
Reviewing and Improving the Gaussian Mechanism for Differential Privacy
Dec 07, 2019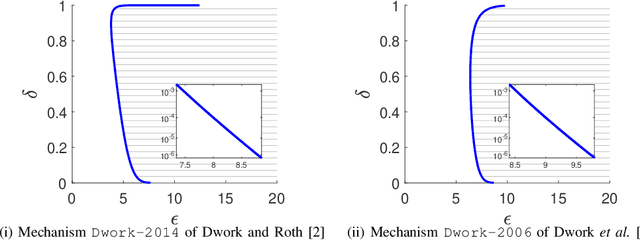
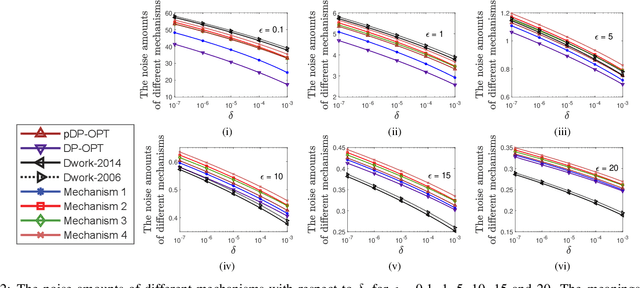

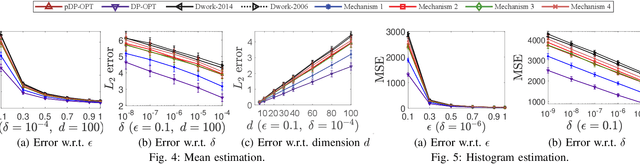
Differential privacy provides a rigorous framework to quantify data privacy, and has received considerable interest recently. A randomized mechanism satisfying $(\epsilon, \delta)$-differential privacy (DP) roughly means that, except with a small probability $\delta$, altering a record in a dataset cannot change the probability that an output is seen by more than a multiplicative factor $e^{\epsilon} $. A well-known solution to $(\epsilon, \delta)$-DP is the Gaussian mechanism initiated by Dwork et al. [1] in 2006 with an improvement by Dwork and Roth [2] in 2014, where a Gaussian noise amount $\sqrt{2\ln \frac{2}{\delta}} \times \frac{\Delta}{\epsilon}$ of [1] or $\sqrt{2\ln \frac{1.25}{\delta}} \times \frac{\Delta}{\epsilon}$ of [2] is added independently to each dimension of the query result, for a query with $\ell_2$-sensitivity $\Delta$. Although both classical Gaussian mechanisms [1,2] assume $0 < \epsilon \leq 1$, our review finds that many studies in the literature have used the classical Gaussian mechanisms under values of $\epsilon$ and $\delta$ where the added noise amounts of [1,2] do not achieve $(\epsilon,\delta)$-DP. We obtain such result by analyzing the optimal noise amount $\sigma_{DP-OPT}$ for $(\epsilon,\delta)$-DP and identifying $\epsilon$ and $\delta$ where the noise amounts of classical mechanisms are even less than $\sigma_{DP-OPT}$. Since $\sigma_{DP-OPT}$ has no closed-form expression and needs to be approximated in an iterative manner, we propose Gaussian mechanisms by deriving closed-form upper bounds for $\sigma_{DP-OPT}$. Our mechanisms achieve $(\epsilon,\delta)$-DP for any $\epsilon$, while the classical mechanisms [1,2] do not achieve $(\epsilon,\delta)$-DP for large $\epsilon$ given $\delta$. Moreover, the utilities of our mechanisms improve those of [1,2] and are close to that of the optimal yet more computationally expensive Gaussian mechanism.
Impact of Prior Knowledge and Data Correlation on Privacy Leakage: A Unified Analysis
Jun 05, 2019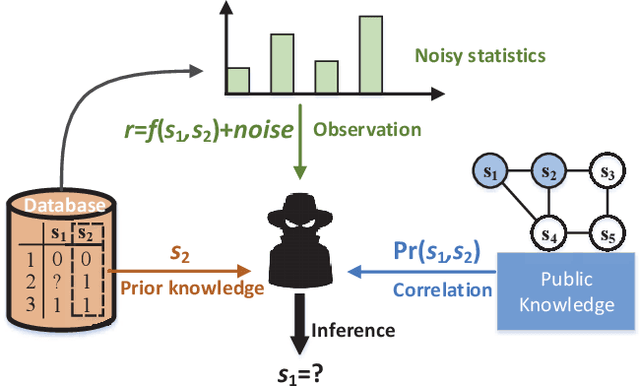
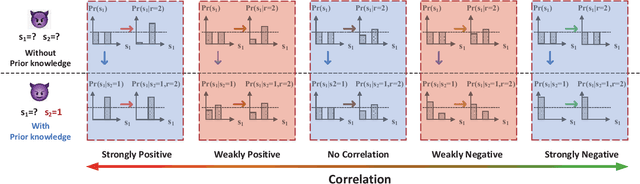
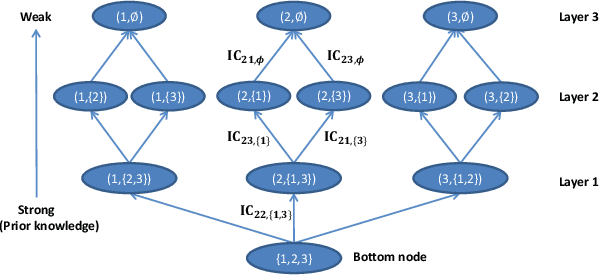
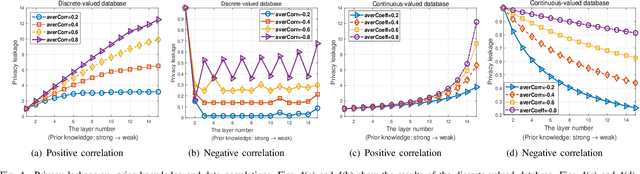
It has been widely understood that differential privacy (DP) can guarantee rigorous privacy against adversaries with arbitrary prior knowledge. However, recent studies demonstrate that this may not be true for correlated data, and indicate that three factors could influence privacy leakage: the data correlation pattern, prior knowledge of adversaries, and sensitivity of the query function. This poses a fundamental problem: what is the mathematical relationship between the three factors and privacy leakage? In this paper, we present a unified analysis of this problem. A new privacy definition, named \textit{prior differential privacy (PDP)}, is proposed to evaluate privacy leakage considering the exact prior knowledge possessed by the adversary. We use two models, the weighted hierarchical graph (WHG) and the multivariate Gaussian model to analyze discrete and continuous data, respectively. We demonstrate that positive, negative, and hybrid correlations have distinct impacts on privacy leakage. Considering general correlations, a closed-form expression of privacy leakage is derived for continuous data, and a chain rule is presented for discrete data. Our results are valid for general linear queries, including count, sum, mean, and histogram. Numerical experiments are presented to verify our theoretical analysis.
Privacy-preserving Crowd-guided AI Decision-making in Ethical Dilemmas
Jun 04, 2019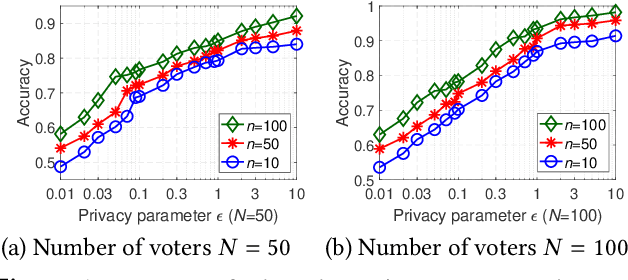
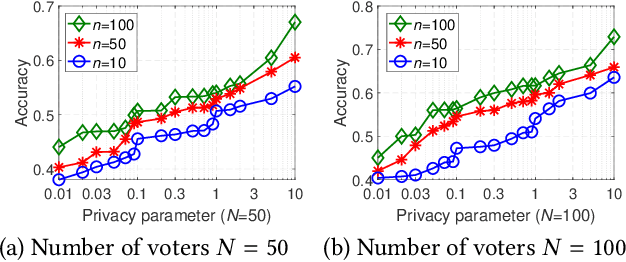
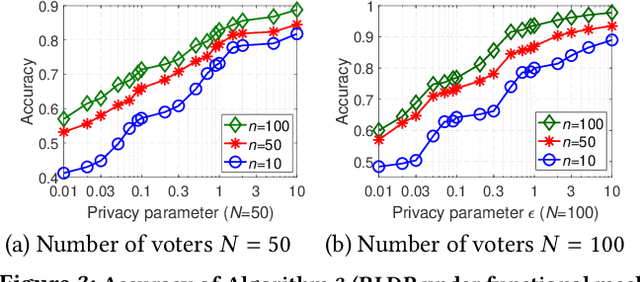
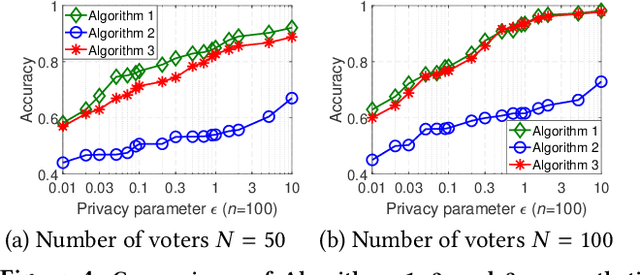
With the rapid development of artificial intelligence (AI), ethical issues surrounding AI have attracted increasing attention. In particular, autonomous vehicles may face moral dilemmas in accident scenarios, such as staying the course resulting in hurting pedestrians or swerving leading to hurting passengers. To investigate such ethical dilemmas, recent studies have adopted preference aggregation, in which each voter expresses her/his preferences over decisions for the possible ethical dilemma scenarios, and a centralized system aggregates these preferences to obtain the winning decision. Although a useful methodology for building ethical AI systems, such an approach can potentially violate the privacy of voters since moral preferences are sensitive information and their disclosure can be exploited by malicious parties. In this paper, we report a first-of-its-kind privacy-preserving crowd-guided AI decision-making approach in ethical dilemmas. We adopt the notion of differential privacy to quantify privacy and consider four granularities of privacy protection by taking voter-/record-level privacy protection and centralized/distributed perturbation into account, resulting in four approaches VLCP, RLCP, VLDP, and RLDP. Moreover, we propose different algorithms to achieve these privacy protection granularities, while retaining the accuracy of the learned moral preference model. Specifically, VLCP and RLCP are implemented with the data aggregator setting a universal privacy parameter and perturbing the averaged moral preference to protect the privacy of voters' data. VLDP and RLDP are implemented in such a way that each voter perturbs her/his local moral preference with a personalized privacy parameter. Extensive experiments on both synthetic and real data demonstrate that the proposed approach can achieve high accuracy of preference aggregation while protecting individual voter's privacy.
On Privacy Protection of Latent Dirichlet Allocation Model Training
Jun 04, 2019
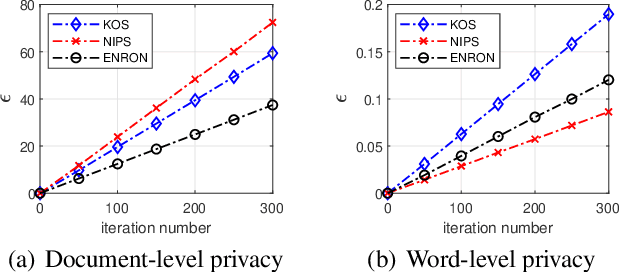
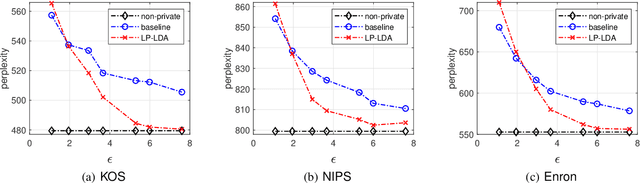
Latent Dirichlet Allocation (LDA) is a popular topic modeling technique for discovery of hidden semantic architecture of text datasets, and plays a fundamental role in many machine learning applications. However, like many other machine learning algorithms, the process of training a LDA model may leak the sensitive information of the training datasets and bring significant privacy risks. To mitigate the privacy issues in LDA, we focus on studying privacy-preserving algorithms of LDA model training in this paper. In particular, we first develop a privacy monitoring algorithm to investigate the privacy guarantee obtained from the inherent randomness of the Collapsed Gibbs Sampling (CGS) process in a typical LDA training algorithm on centralized curated datasets. Then, we further propose a locally private LDA training algorithm on crowdsourced data to provide local differential privacy for individual data contributors. The experimental results on real-world datasets demonstrate the effectiveness of our proposed algorithms.