 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXuelei Sherry Ni
Developing and Improving Risk Models using Machine-learning Based Algorithms
Sep 09, 2020
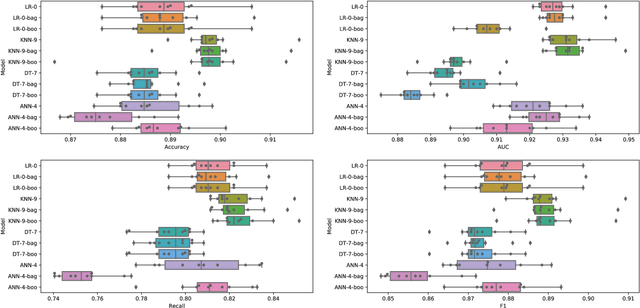
The objective of this study is to develop a good risk model for classifying business delinquency by simultaneously exploring several machine learning based methods including regularization, hyper-parameter optimization, and model ensembling algorithms. The rationale under the analyses is firstly to obtain good base binary classifiers (include Logistic Regression ($LR$), K-Nearest Neighbors ($KNN$), Decision Tree ($DT$), and Artificial Neural Networks ($ANN$)) via regularization and appropriate settings of hyper-parameters. Then two model ensembling algorithms including bagging and boosting are performed on the good base classifiers for further model improvement. The models are evaluated using accuracy, Area Under the Receiver Operating Characteristic Curve (AUC of ROC), recall, and F1 score via repeating 10-fold cross-validation 10 times. The results show the optimal base classifiers along with the hyper-parameter settings are $LR$ without regularization, $KNN$ by using 9 nearest neighbors, $DT$ by setting the maximum level of the tree to be 7, and $ANN$ with three hidden layers. Bagging on $KNN$ with $K$ valued 9 is the optimal model we can get for risk classification as it reaches the average accuracy, AUC, recall, and F1 score valued 0.90, 0.93, 0.82, and 0.89, respectively.
Improving Investment Suggestions for Peer-to-Peer (P2P) Lending via Integrating Credit Scoring into Profit Scoring
Sep 09, 2020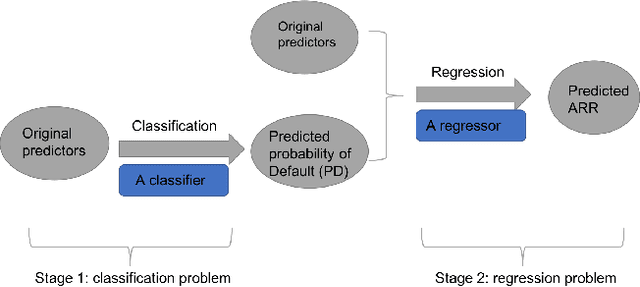


In the peer-to-peer (P2P) lending market, lenders lend the money to the borrowers through a virtual platform and earn the possible profit generated by the interest rate. From the perspective of lenders, they want to maximize the profit while minimizing the risk. Therefore, many studies have used machine learning algorithms to help the lenders identify the "best" loans for making investments. The studies have mainly focused on two categories to guide the lenders' investments: one aims at minimizing the risk of investment (i.e., the credit scoring perspective) while the other aims at maximizing the profit (i.e., the profit scoring perspective). However, they have all focused on one category only and there is seldom research trying to integrate the two categories together. Motivated by this, we propose a two-stage framework that incorporates the credit information into a profit scoring modeling. We conducted the empirical experiment on a real-world P2P lending data from the US P2P market and used the Light Gradient Boosting Machine (lightGBM) algorithm in the two-stage framework. Results show that the proposed two-stage method could identify more profitable loans and thereby provide better investment guidance to the investors compared to the existing one-stage profit scoring alone approach. Therefore, the proposed framework serves as an innovative perspective for making investment decisions in P2P lending.
Predicting class-imbalanced business risk using resampling, regularization, and model ensembling algorithms
Mar 13, 2019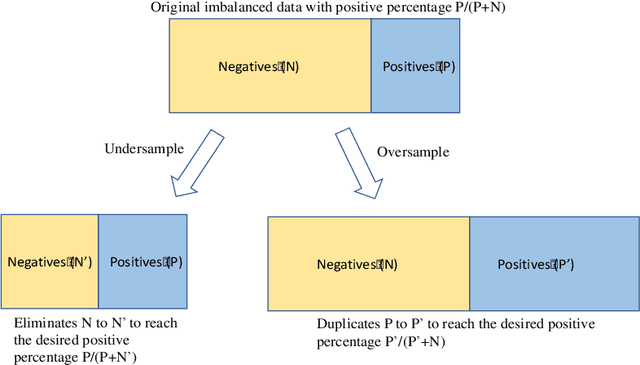
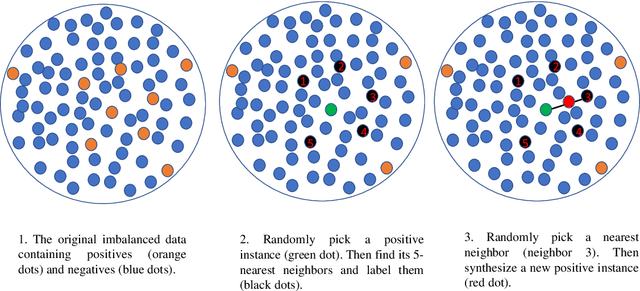
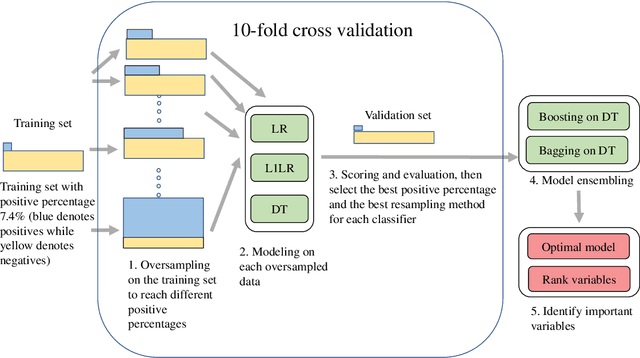
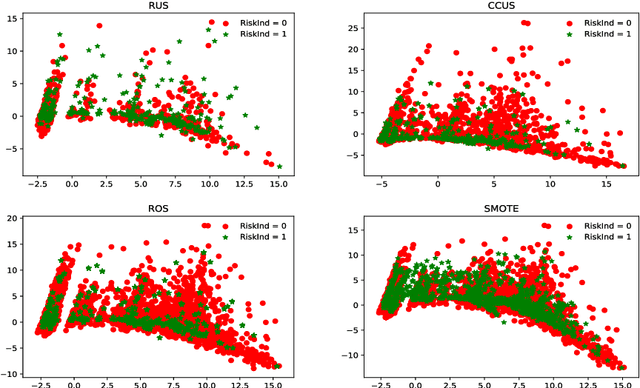
We aim at developing and improving the imbalanced business risk modeling via jointly using proper evaluation criteria, resampling, cross-validation, classifier regularization, and ensembling techniques. Area Under the Receiver Operating Characteristic Curve (AUC of ROC) is used for model comparison based on 10-fold cross validation. Two undersampling strategies including random undersampling (RUS) and cluster centroid undersampling (CCUS), as well as two oversampling methods including random oversampling (ROS) and Synthetic Minority Oversampling Technique (SMOTE), are applied. Three highly interpretable classifiers, including logistic regression without regularization (LR), L1-regularized LR (L1LR), and decision tree (DT) are implemented. Two ensembling techniques, including Bagging and Boosting, are applied on the DT classifier for further model improvement. The results show that, Boosting on DT by using the oversampled data containing 50% positives via SMOTE is the optimal model and it can achieve AUC, recall, and F1 score valued 0.8633, 0.9260, and 0.8907, respectively.
Modeling default rate in P2P lending via LSTM
Feb 13, 2019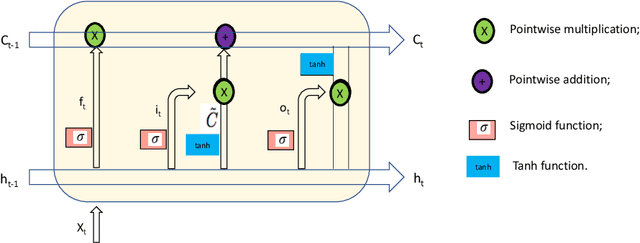
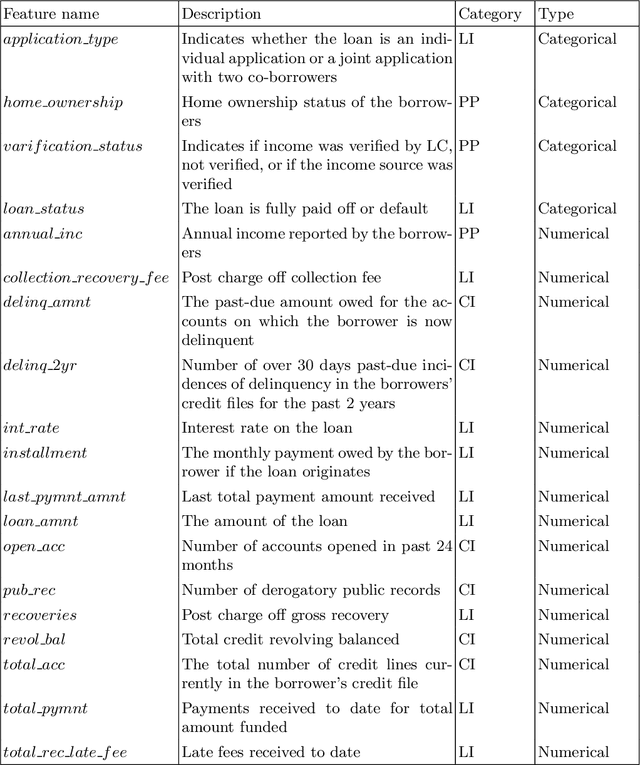
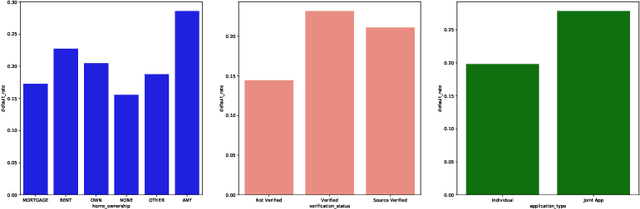
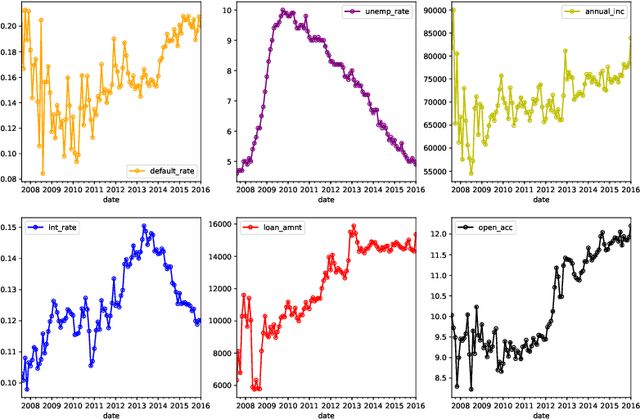
With the fast development of peer to peer (P2P) lending, financial institutions have a substantial challenge from benefit loss due to the delinquent behaviors of the money borrowers. Therefore, having a comprehensive understanding of the changing trend of the default rate in the P2P domain is crucial. In this paper, we comprehensively study the changing trend of the default rate of P2P USA market at the aggregative level from August 2007 to January 2016. From the data visualization perspective, we found that three features, including delinq_2yrs, recoveries, and collection_recovery_fee, could potentially increase the default rate. The long short-term memory (LSTM) approach shows its great potential in modeling the P2P transaction data. Furthermore, incorporating the macroeconomic feature unemp_rate can improve the LSTM performance by decreasing RMSE on both training and testing datasets. Our study can broaden the applications of LSTM approach in the P2P market.
A XGBoost risk model via feature selection and Bayesian hyper-parameter optimization
Jan 24, 2019
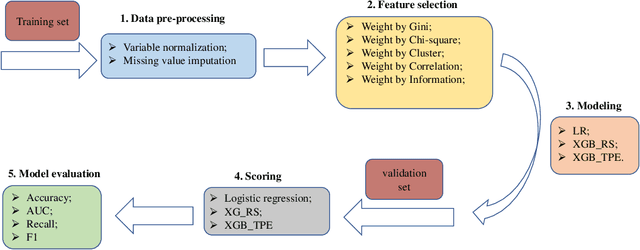


This paper aims to explore models based on the extreme gradient boosting (XGBoost) approach for business risk classification. Feature selection (FS) algorithms and hyper-parameter optimizations are simultaneously considered during model training. The five most commonly used FS methods including weight by Gini, weight by Chi-square, hierarchical variable clustering, weight by correlation, and weight by information are applied to alleviate the effect of redundant features. Two hyper-parameter optimization approaches, random search (RS) and Bayesian tree-structured Parzen Estimator (TPE), are applied in XGBoost. The effect of different FS and hyper-parameter optimization methods on the model performance are investigated by the Wilcoxon Signed Rank Test. The performance of XGBoost is compared to the traditionally utilized logistic regression (LR) model in terms of classification accuracy, area under the curve (AUC), recall, and F1 score obtained from the 10-fold cross validation. Results show that hierarchical clustering is the optimal FS method for LR while weight by Chi-square achieves the best performance in XG-Boost. Both TPE and RS optimization in XGBoost outperform LR significantly. TPE optimization shows a superiority over RS since it results in a significantly higher accuracy and a marginally higher AUC, recall and F1 score. Furthermore, XGBoost with TPE tuning shows a lower variability than the RS method. Finally, the ranking of feature importance based on XGBoost enhances the model interpretation. Therefore, XGBoost with Bayesian TPE hyper-parameter optimization serves as an operative while powerful approach for business risk modeling.
An Automatic Interaction Detection Hybrid Model for Bankcard Response Classification
Jan 02, 2019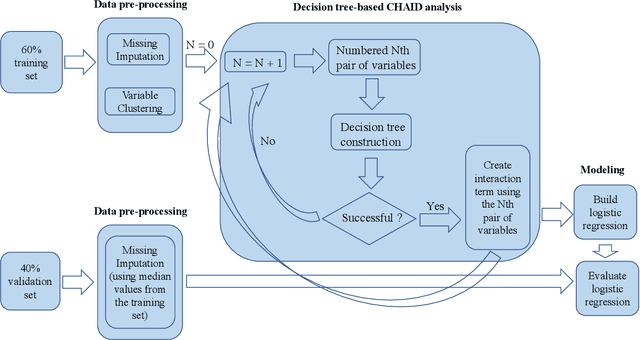
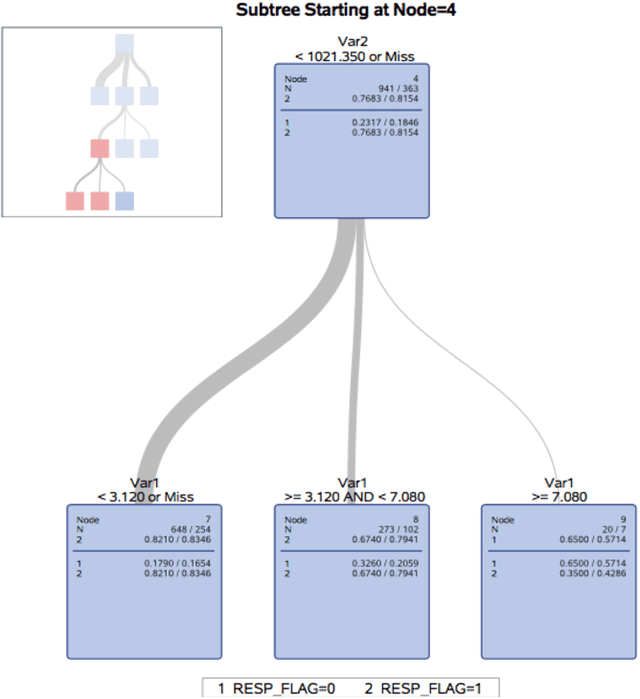
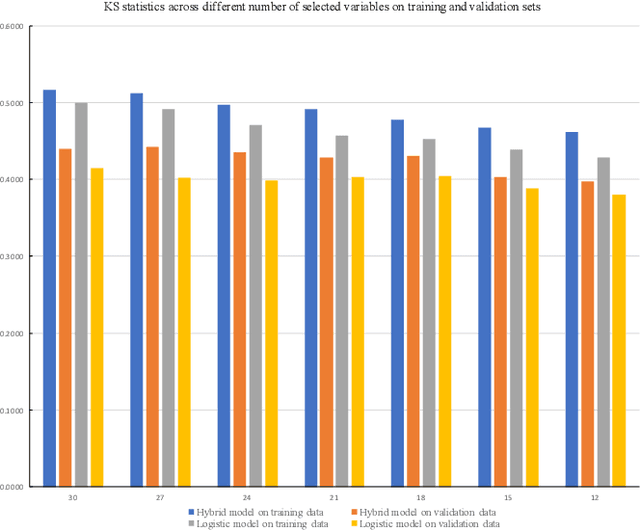
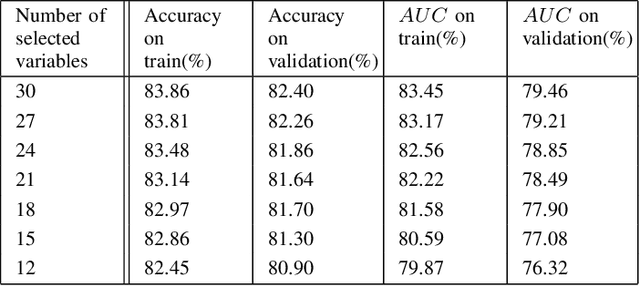
In this paper, we propose a hybrid bankcard response model, which integrates decision tree based chi-square automatic interaction detection (CHAID) into logistic regression. In the first stage of the hybrid model, CHAID analysis is used to detect the possibly potential variable interactions. Then in the second stage, these potential interactions are served as the additional input variables in logistic regression. The motivation of the proposed hybrid model is that adding variable interactions may improve the performance of logistic regression. To demonstrate the effectiveness of the proposed hybrid model, it is evaluated on a real credit customer response data set. As the results reveal, by identifying potential interactions among independent variables, the proposed hybrid approach outperforms the logistic regression without searching for interactions in terms of classification accuracy, the area under the receiver operating characteristic curve (ROC), and Kolmogorov-Smirnov (KS) statistics. Furthermore, CHAID analysis for interaction detection is much more computationally efficient than the stepwise search mentioned above and some identified interactions are shown to have statistically significant predictive power on the target variable. Last but not least, the customer profile created based on the CHAID tree provides a reasonable interpretation of the interactions, which is the required by regulations of the credit industry. Hence, this study provides an alternative for handling bankcard classification tasks.
A two-stage hybrid model by using artificial neural networks as feature construction algorithms
Dec 06, 2018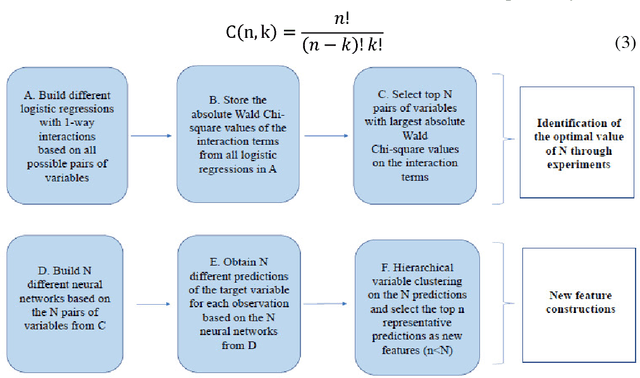
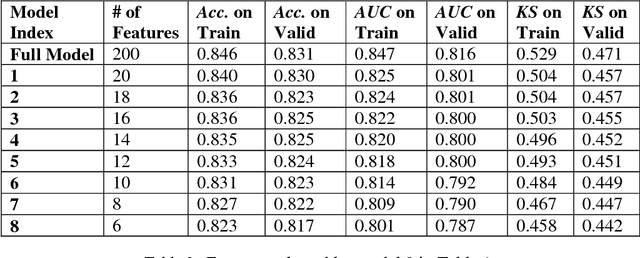
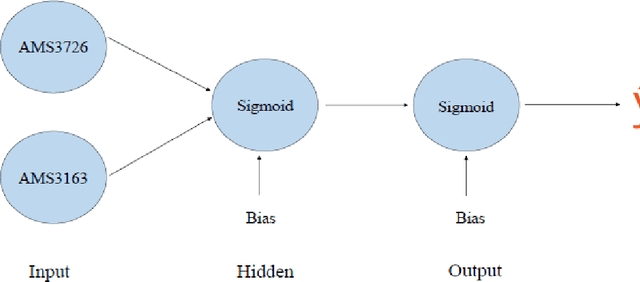
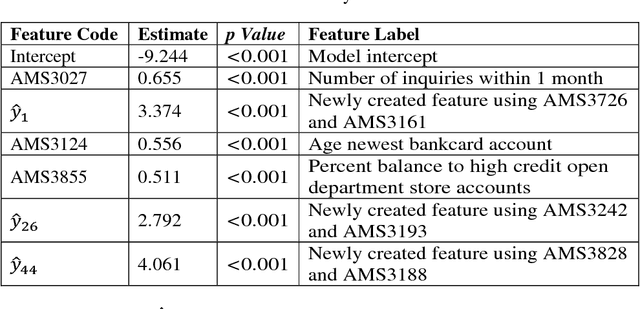
We propose a two-stage hybrid approach with neural networks as the new feature construction algorithms for bankcard response classifications. The hybrid model uses a very simple neural network structure as the new feature construction tool in the first stage, then the newly created features are used as the additional input variables in logistic regression in the second stage. The model is compared with the traditional one-stage model in credit customer response classification. It is observed that the proposed two-stage model outperforms the one-stage model in terms of accuracy, the area under ROC curve, and KS statistic. By creating new features with the neural network technique, the underlying nonlinear relationships between variables are identified. Furthermore, by using a very simple neural network structure, the model could overcome the drawbacks of neural networks in terms of its long training time, complex topology, and limited interpretability.