 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXuhui Zhang
Joint Signal Detection and Automatic Modulation Classification via Deep Learning
Apr 29, 2024
Signal detection and modulation classification are two crucial tasks in various wireless communication systems. Different from prior works that investigate them independently, this paper studies the joint signal detection and automatic modulation classification (AMC) by considering a realistic and complex scenario, in which multiple signals with different modulation schemes coexist at different carrier frequencies. We first generate a coexisting RADIOML dataset (CRML23) to facilitate the joint design. Different from the publicly available AMC dataset ignoring the signal detection step and containing only one signal, our synthetic dataset covers the more realistic multiple-signal coexisting scenario. Then, we present a joint framework for detection and classification (JDM) for such a multiple-signal coexisting environment, which consists of two modules for signal detection and AMC, respectively. In particular, these two modules are interconnected using a designated data structure called "proposal". Finally, we conduct extensive simulations over the newly developed dataset, which demonstrate the effectiveness of our designs. Our code and dataset are now available as open-source (https://github.com/Singingkettle/ChangShuoRadioData).
A Class of Geometric Structures in Transfer Learning: Minimax Bounds and Optimality
Feb 23, 2022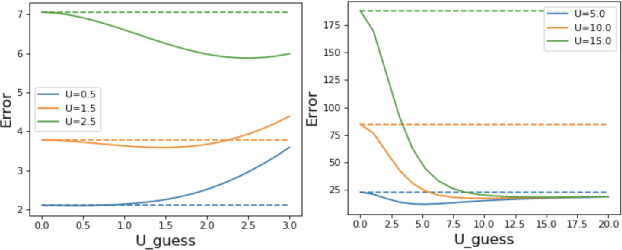
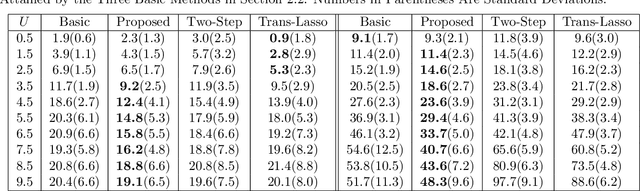

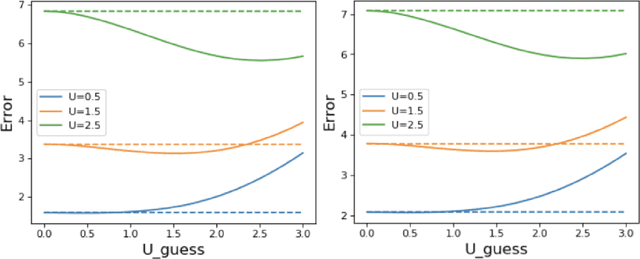
We study the problem of transfer learning, observing that previous efforts to understand its information-theoretic limits do not fully exploit the geometric structure of the source and target domains. In contrast, our study first illustrates the benefits of incorporating a natural geometric structure within a linear regression model, which corresponds to the generalized eigenvalue problem formed by the Gram matrices of both domains. We next establish a finite-sample minimax lower bound, propose a refined model interpolation estimator that enjoys a matching upper bound, and then extend our framework to multiple source domains and generalized linear models. Surprisingly, as long as information is available on the distance between the source and target parameters, negative-transfer does not occur. Simulation studies show that our proposed interpolation estimator outperforms state-of-the-art transfer learning methods in both moderate- and high-dimensional settings.
Time-Series Imputation with Wasserstein Interpolation for Optimal Look-Ahead-Bias and Variance Tradeoff
Feb 25, 2021



Missing time-series data is a prevalent practical problem. Imputation methods in time-series data often are applied to the full panel data with the purpose of training a model for a downstream out-of-sample task. For example, in finance, imputation of missing returns may be applied prior to training a portfolio optimization model. Unfortunately, this practice may result in a look-ahead-bias in the future performance on the downstream task. There is an inherent trade-off between the look-ahead-bias of using the full data set for imputation and the larger variance in the imputation from using only the training data. By connecting layers of information revealed in time, we propose a Bayesian posterior consensus distribution which optimally controls the variance and look-ahead-bias trade-off in the imputation. We demonstrate the benefit of our methodology both in synthetic and real financial data.
Distributionally Robust Parametric Maximum Likelihood Estimation
Oct 11, 2020


We consider the parameter estimation problem of a probabilistic generative model prescribed using a natural exponential family of distributions. For this problem, the typical maximum likelihood estimator usually overfits under limited training sample size, is sensitive to noise and may perform poorly on downstream predictive tasks. To mitigate these issues, we propose a distributionally robust maximum likelihood estimator that minimizes the worst-case expected log-loss uniformly over a parametric Kullback-Leibler ball around a parametric nominal distribution. Leveraging the analytical expression of the Kullback-Leibler divergence between two distributions in the same natural exponential family, we show that the min-max estimation problem is tractable in a broad setting, including the robust training of generalized linear models. Our novel robust estimator also enjoys statistical consistency and delivers promising empirical results in both regression and classification tasks.
Machine Learning's Dropout Training is Distributionally Robust Optimal
Sep 13, 2020



This paper shows that dropout training in Generalized Linear Models is the minimax solution of a two-player, zero-sum game where an adversarial nature corrupts a statistician's covariates using a multiplicative nonparametric errors-in-variables model. In this game---known as a Distributionally Robust Optimization problem---nature's least favorable distribution is dropout noise, where nature independently deletes entries of the covariate vector with some fixed probability $\delta$. Our decision-theoretic analysis shows that dropout training---the statistician's minimax strategy in the game---indeed provides out-of-sample expected loss guarantees for distributions that arise from multiplicative perturbations of in-sample data. This paper also provides a novel, parallelizable, Unbiased Multi-Level Monte Carlo algorithm to speed-up the implementation of dropout training. Our algorithm has a much smaller computational cost compared to the naive implementation of dropout, provided the number of data points is much smaller than the dimension of the covariate vector.
Latent Variable Discovery Using Dependency Patterns
Jul 22, 2016



The causal discovery of Bayesian networks is an active and important research area, and it is based upon searching the space of causal models for those which can best explain a pattern of probabilistic dependencies shown in the data. However, some of those dependencies are generated by causal structures involving variables which have not been measured, i.e., latent variables. Some such patterns of dependency "reveal" themselves, in that no model based solely upon the observed variables can explain them as well as a model using a latent variable. That is what latent variable discovery is based upon. Here we did a search for finding them systematically, so that they may be applied in latent variable discovery in a more rigorous fashion.