 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXun Yu Zhou
Learning Merton's Strategies in an Incomplete Market: Recursive Entropy Regularization and Biased Gaussian Exploration
Dec 19, 2023
We study Merton's expected utility maximization problem in an incomplete market, characterized by a factor process in addition to the stock price process, where all the model primitives are unknown. We take the reinforcement learning (RL) approach to learn optimal portfolio policies directly by exploring the unknown market, without attempting to estimate the model parameters. Based on the entropy-regularization framework for general continuous-time RL formulated in Wang et al. (2020), we propose a recursive weighting scheme on exploration that endogenously discounts the current exploration reward by the past accumulative amount of exploration. Such a recursive regularization restores the optimality of Gaussian exploration. However, contrary to the existing results, the optimal Gaussian policy turns out to be biased in general, due to the interwinding needs for hedging and for exploration. We present an asymptotic analysis of the resulting errors to show how the level of exploration affects the learned policies. Furthermore, we establish a policy improvement theorem and design several RL algorithms to learn Merton's optimal strategies. At last, we carry out both simulation and empirical studies with a stochastic volatility environment to demonstrate the efficiency and robustness of the RL algorithms in comparison to the conventional plug-in method.
Variable Clustering via Distributionally Robust Nodewise Regression
Dec 21, 2022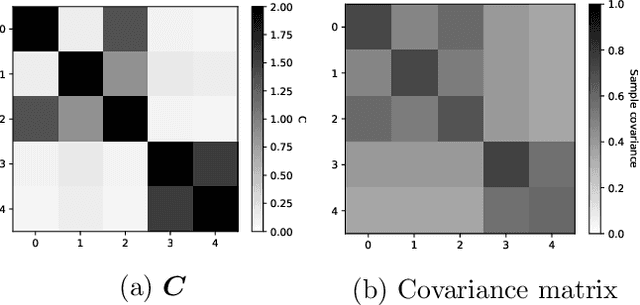

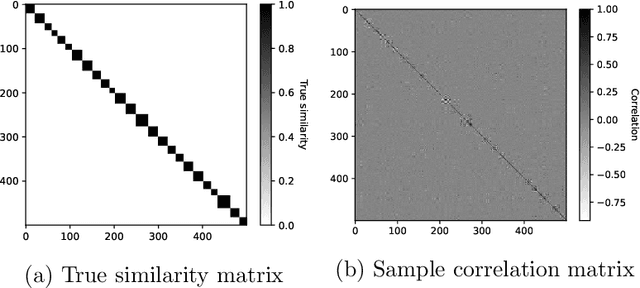
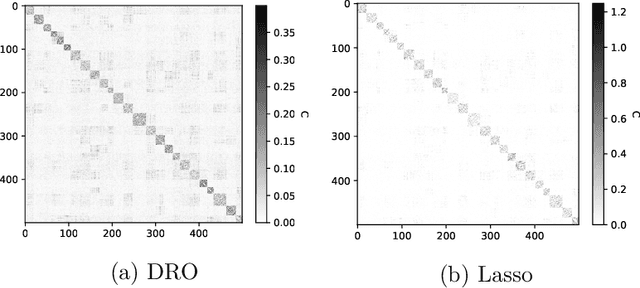
We study a multi-factor block model for variable clustering and connect it to the regularized subspace clustering by formulating a distributionally robust version of the nodewise regression. To solve the latter problem, we derive a convex relaxation, provide guidance on selecting the size of the robust region, and hence the regularization weighting parameter, based on the data, and propose an ADMM algorithm for implementation. We validate our method in an extensive simulation study. Finally, we propose and apply a variant of our method to stock return data, obtain interpretable clusters that facilitate portfolio selection and compare its out-of-sample performance with other clustering methods in an empirical study.
Square-root regret bounds for continuous-time episodic Markov decision processes
Oct 03, 2022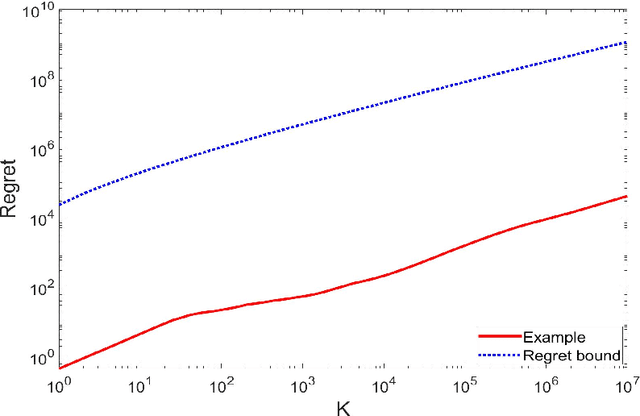
We study reinforcement learning for continuous-time Markov decision processes (MDPs) in the finite-horizon episodic setting. We present a learning algorithm based on the methods of value iteration and upper confidence bound. We derive an upper bound on the worst-case expected regret for the proposed algorithm, and establish a worst-case lower bound, both bounds are of the order of square-root on the number of episodes. Finally, we conduct simulation experiments to illustrate the performance of our algorithm.
Choquet regularization for reinforcement learning
Aug 17, 2022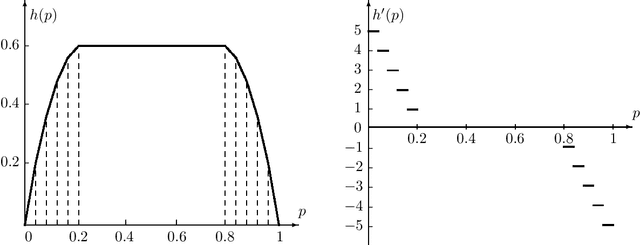
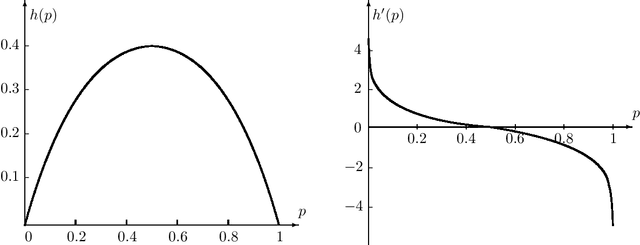
We propose \emph{Choquet regularizers} to measure and manage the level of exploration for reinforcement learning (RL), and reformulate the continuous-time entropy-regularized RL problem of Wang et al. (2020, JMLR, 21(198)) in which we replace the differential entropy used for regularization with a Choquet regularizer. We derive the Hamilton--Jacobi--Bellman equation of the problem, and solve it explicitly in the linear--quadratic (LQ) case via maximizing statically a mean--variance constrained Choquet regularizer. Under the LQ setting, we derive explicit optimal distributions for several specific Choquet regularizers, and conversely identify the Choquet regularizers that generate a number of broadly used exploratory samplers such as $\epsilon$-greedy, exponential, uniform and Gaussian.
q-Learning in Continuous Time
Jul 02, 2022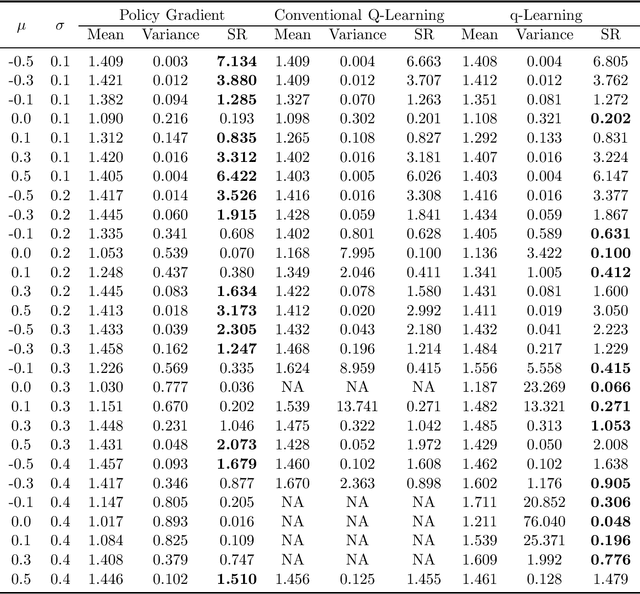
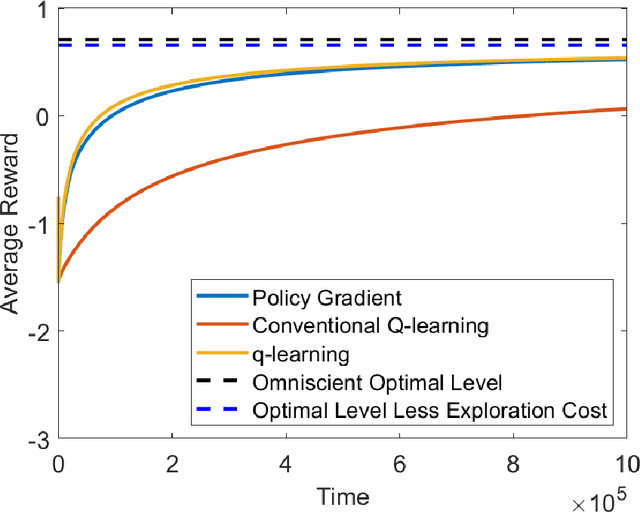
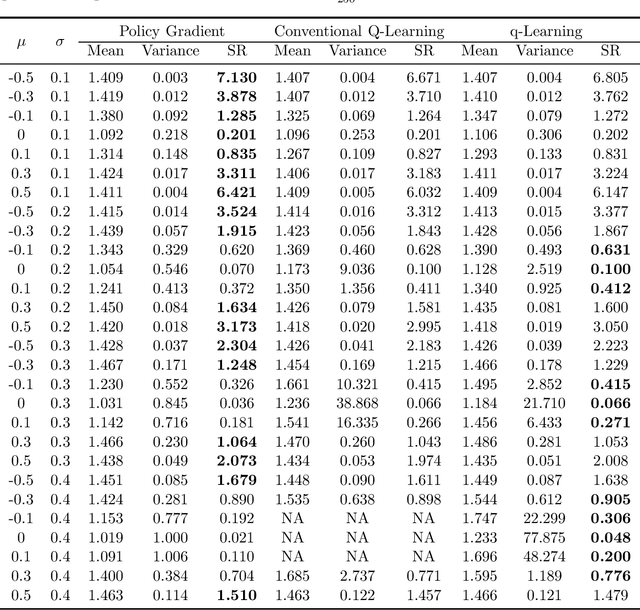

We study the continuous-time counterpart of Q-learning for reinforcement learning (RL) under the entropy-regularized, exploratory diffusion process formulation introduced by Wang et al. (2020) As the conventional (big) Q-function collapses in continuous time, we consider its first-order approximation and coin the term "(little) q-function". This function is related to the instantaneous advantage rate function as well as the Hamiltonian. We develop a "q-learning" theory around the q-function that is independent of time discretization. Given a stochastic policy, we jointly characterize the associated q-function and value function by martingale conditions of certain stochastic processes. We then apply the theory to devise different actor-critic algorithms for solving underlying RL problems, depending on whether or not the density function of the Gibbs measure generated from the q-function can be computed explicitly. One of our algorithms interprets the well-known Q-learning algorithm SARSA, and another recovers a policy gradient (PG) based continuous-time algorithm proposed in Jia and Zhou (2021). Finally, we conduct simulation experiments to compare the performance of our algorithms with those of PG-based algorithms in Jia and Zhou (2021) and time-discretized conventional Q-learning algorithms.
Logarithmic regret bounds for continuous-time average-reward Markov decision processes
May 24, 2022We consider reinforcement learning for continuous-time Markov decision processes (MDPs) in the infinite-horizon, average-reward setting. In contrast to discrete-time MDPs, a continuous-time process moves to a state and stays there for a random holding time after an action is taken. With unknown transition probabilities and rates of exponential holding times, we derive instance-dependent regret lower bounds that are logarithmic in the time horizon. Moreover, we design a learning algorithm and establish a finite-time regret bound that achieves the logarithmic growth rate. Our analysis builds upon upper confidence reinforcement learning, a delicate estimation of the mean holding times, and stochastic comparison of point processes.
Policy Gradient and Actor-Critic Learning in Continuous Time and Space: Theory and Algorithms
Nov 22, 2021
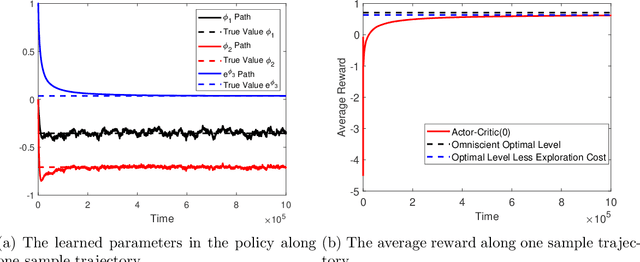
We study policy gradient (PG) for reinforcement learning in continuous time and space under the regularized exploratory formulation developed by Wang et al. (2020). We represent the gradient of the value function with respect to a given parameterized stochastic policy as the expected integration of an auxiliary running reward function that can be evaluated using samples and the current value function. This effectively turns PG into a policy evaluation (PE) problem, enabling us to apply the martingale approach recently developed by Jia and Zhou (2021) for PE to solve our PG problem. Based on this analysis, we propose two types of the actor-critic algorithms for RL, where we learn and update value functions and policies simultaneously and alternatingly. The first type is based directly on the aforementioned representation which involves future trajectories and hence is offline. The second type, designed for online learning, employs the first-order condition of the policy gradient and turns it into martingale orthogonality conditions. These conditions are then incorporated using stochastic approximation when updating policies. Finally, we demonstrate the algorithms by simulations in two concrete examples.
Policy Evaluation and Temporal-Difference Learning in Continuous Time and Space: A Martingale Approach
Aug 15, 2021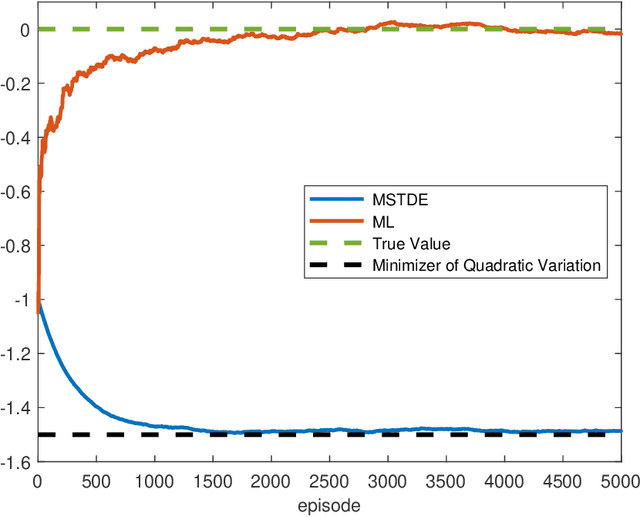


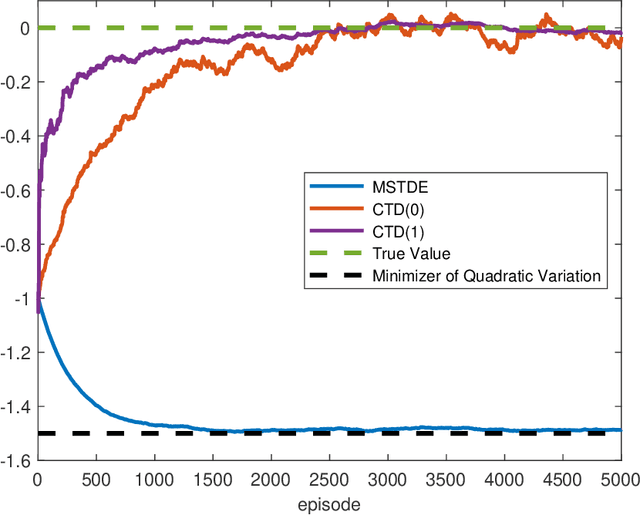
We propose a unified framework to study policy evaluation (PE) and the associated temporal difference (TD) methods for reinforcement learning in continuous time and space. We show that PE is equivalent to maintaining the martingale condition of a process. From this perspective, we find that the mean--square TD error approximates the quadratic variation of the martingale and thus is not a suitable objective for PE. We present two methods to use the martingale characterization for designing PE algorithms. The first one minimizes a "martingale loss function", whose solution is proved to be the best approximation of the true value function in the mean--square sense. This method interprets the classical gradient Monte-Carlo algorithm. The second method is based on a system of equations called the "martingale orthogonality conditions" with "test functions". Solving these equations in different ways recovers various classical TD algorithms, such as TD($\lambda$), LSTD, and GTD. Different choices of test functions determine in what sense the resulting solutions approximate the true value function. Moreover, we prove that any convergent time-discretized algorithm converges to its continuous-time counterpart as the mesh size goes to zero. We demonstrate the theoretical results and corresponding algorithms with numerical experiments and applications.
Simulated annealing from continuum to discretization: a convergence analysis via the Eyring--Kramers law
Feb 09, 2021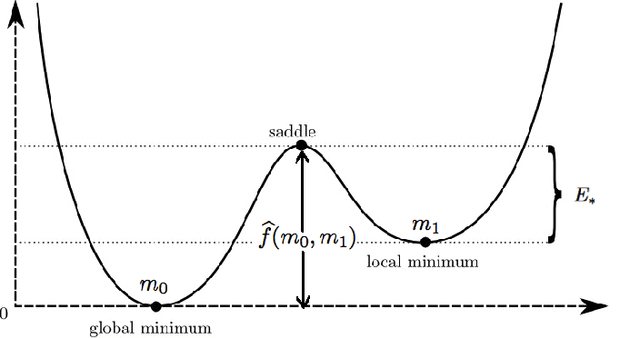
We study the convergence rate of continuous-time simulated annealing $(X_t; \, t \ge 0)$ and its discretization $(x_k; \, k =0,1, \ldots)$ for approximating the global optimum of a given function $f$. We prove that the tail probability $\mathbb{P}(f(X_t) > \min f +\delta)$ (resp. $\mathbb{P}(f(x_k) > \min f +\delta)$) decays polynomial in time (resp. in cumulative step size), and provide an explicit rate as a function of the model parameters. Our argument applies the recent development on functional inequalities for the Gibbs measure at low temperatures -- the Eyring-Kramers law. In the discrete setting, we obtain a condition on the step size to ensure the convergence.
Continuous-Time Mean-Variance Portfolio Selection: A Reinforcement Learning Framework
May 05, 2019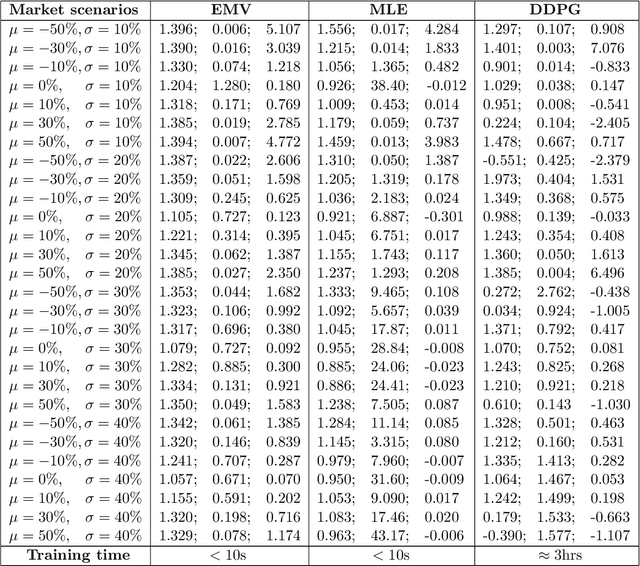
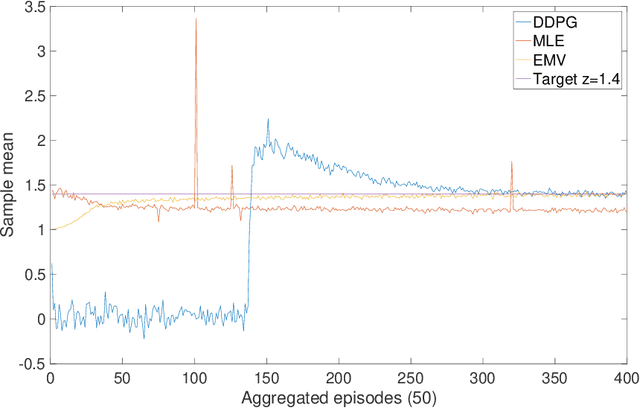
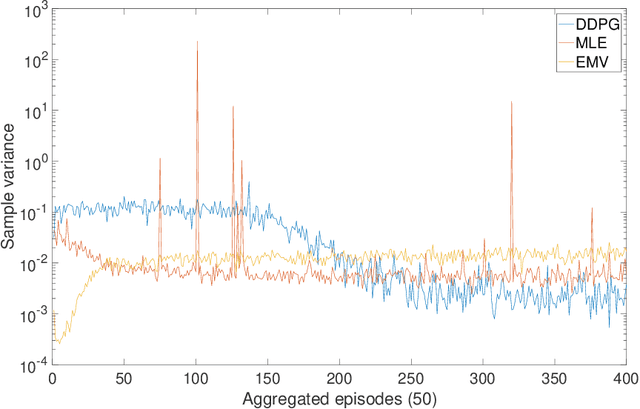
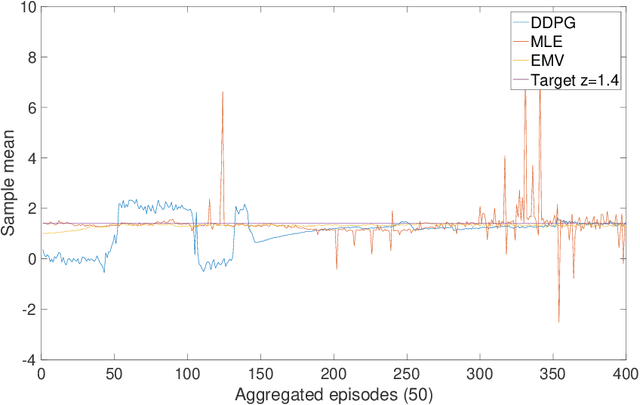
We approach the continuous-time mean-variance (MV) portfolio selection with reinforcement learning (RL). The problem is to achieve the best tradeoff between exploration and exploitation, and is formulated as an entropy-regularized, relaxed stochastic control problem. We prove that the optimal feedback policy for this problem must be Gaussian, with time-decaying variance. We then establish connections between the entropy-regularized MV and the classical MV, including the solvability equivalence and the convergence as exploration weighting parameter decays to zero. Finally, we prove a policy improvement theorem, based on which we devise an implementable RL algorithm. We find that our algorithm outperforms both an adaptive control based method and a deep neural networks based algorithm by a large margin in our simulations.