 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan Kang
Attention-Driven Training-Free Efficiency Enhancement of Diffusion Models
May 08, 2024
Diffusion Models (DMs) have exhibited superior performance in generating high-quality and diverse images. However, this exceptional performance comes at the cost of expensive architectural design, particularly due to the attention module heavily used in leading models. Existing works mainly adopt a retraining process to enhance DM efficiency. This is computationally expensive and not very scalable. To this end, we introduce the Attention-driven Training-free Efficient Diffusion Model (AT-EDM) framework that leverages attention maps to perform run-time pruning of redundant tokens, without the need for any retraining. Specifically, for single-denoising-step pruning, we develop a novel ranking algorithm, Generalized Weighted Page Rank (G-WPR), to identify redundant tokens, and a similarity-based recovery method to restore tokens for the convolution operation. In addition, we propose a Denoising-Steps-Aware Pruning (DSAP) approach to adjust the pruning budget across different denoising timesteps for better generation quality. Extensive evaluations show that AT-EDM performs favorably against prior art in terms of efficiency (e.g., 38.8% FLOPs saving and up to 1.53x speed-up over Stable Diffusion XL) while maintaining nearly the same FID and CLIP scores as the full model. Project webpage: https://atedm.github.io.
FedProK: Trustworthy Federated Class-Incremental Learning via Prototypical Feature Knowledge Transfer
May 04, 2024Federated Class-Incremental Learning (FCIL) focuses on continually transferring the previous knowledge to learn new classes in dynamic Federated Learning (FL). However, existing methods do not consider the trustworthiness of FCIL, i.e., improving continual utility, privacy, and efficiency simultaneously, which is greatly influenced by catastrophic forgetting and data heterogeneity among clients. To address this issue, we propose FedProK (Federated Prototypical Feature Knowledge Transfer), leveraging prototypical feature as a novel representation of knowledge to perform spatial-temporal knowledge transfer. Specifically, FedProK consists of two components: (1) feature translation procedure on the client side by temporal knowledge transfer from the learned classes and (2) prototypical knowledge fusion on the server side by spatial knowledge transfer among clients. Extensive experiments conducted in both synchronous and asynchronous settings demonstrate that our FedProK outperforms the other state-of-the-art methods in three perspectives of trustworthiness, validating its effectiveness in selectively transferring spatial-temporal knowledge.
FedEval-LLM: Federated Evaluation of Large Language Models on Downstream Tasks with Collective Wisdom
Apr 18, 2024Federated Learning (FL) has emerged as a promising solution for collaborative training of large language models (LLMs). However, the integration of LLMs into FL introduces new challenges, particularly concerning the evaluation of LLMs. Traditional evaluation methods that rely on labeled test sets and similarity-based metrics cover only a subset of the acceptable answers, thereby failing to accurately reflect the performance of LLMs on generative tasks. Meanwhile, although automatic evaluation methods that leverage advanced LLMs present potential, they face critical risks of data leakage due to the need to transmit data to external servers and suboptimal performance on downstream tasks due to the lack of domain knowledge. To address these issues, we propose a Federated Evaluation framework of Large Language Models, named FedEval-LLM, that provides reliable performance measurements of LLMs on downstream tasks without the reliance on labeled test sets and external tools, thus ensuring strong privacy-preserving capability. FedEval-LLM leverages a consortium of personalized LLMs from participants as referees to provide domain knowledge and collective evaluation capability, thus aligning to the respective downstream tasks and mitigating uncertainties and biases associated with a single referee. Experimental results demonstrate a significant improvement in the evaluation capability of personalized evaluation models on downstream tasks. When applied to FL, these evaluation models exhibit strong agreement with human preference and RougeL-score on meticulously curated test sets. FedEval-LLM effectively overcomes the limitations of traditional metrics and the reliance on external services, making it a promising framework for the evaluation of LLMs within collaborative training scenarios.
Hyperparameter Optimization for SecureBoost via Constrained Multi-Objective Federated Learning
Apr 06, 2024



SecureBoost is a tree-boosting algorithm that leverages homomorphic encryption (HE) to protect data privacy in vertical federated learning. SecureBoost and its variants have been widely adopted in fields such as finance and healthcare. However, the hyperparameters of SecureBoost are typically configured heuristically for optimizing model performance (i.e., utility) solely, assuming that privacy is secured. Our study found that SecureBoost and some of its variants are still vulnerable to label leakage. This vulnerability may lead the current heuristic hyperparameter configuration of SecureBoost to a suboptimal trade-off between utility, privacy, and efficiency, which are pivotal elements toward a trustworthy federated learning system. To address this issue, we propose the Constrained Multi-Objective SecureBoost (CMOSB) algorithm, which aims to approximate Pareto optimal solutions that each solution is a set of hyperparameters achieving an optimal trade-off between utility loss, training cost, and privacy leakage. We design measurements of the three objectives, including a novel label inference attack named instance clustering attack (ICA) to measure the privacy leakage of SecureBoost. Additionally, we provide two countermeasures against ICA. The experimental results demonstrate that the CMOSB yields superior hyperparameters over those optimized by grid search and Bayesian optimization regarding the trade-off between utility loss, training cost, and privacy leakage.
UMAIR-FPS: User-aware Multi-modal Animation Illustration Recommendation Fusion with Painting Style
Feb 16, 2024The rapid advancement of high-quality image generation models based on AI has generated a deluge of anime illustrations. Recommending illustrations to users within massive data has become a challenging and popular task. However, existing anime recommendation systems have focused on text features but still need to integrate image features. In addition, most multi-modal recommendation research is constrained by tightly coupled datasets, limiting its applicability to anime illustrations. We propose the User-aware Multi-modal Animation Illustration Recommendation Fusion with Painting Style (UMAIR-FPS) to tackle these gaps. In the feature extract phase, for image features, we are the first to combine image painting style features with semantic features to construct a dual-output image encoder for enhancing representation. For text features, we obtain text embeddings based on fine-tuning Sentence-Transformers by incorporating domain knowledge that composes a variety of domain text pairs from multilingual mappings, entity relationships, and term explanation perspectives, respectively. In the multi-modal fusion phase, we novelly propose a user-aware multi-modal contribution measurement mechanism to weight multi-modal features dynamically according to user features at the interaction level and employ the DCN-V2 module to model bounded-degree multi-modal crosses effectively. UMAIR-FPS surpasses the stat-of-the-art baselines on large real-world datasets, demonstrating substantial performance enhancements.
A Theoretical Analysis of Efficiency Constrained Utility-Privacy Bi-Objective Optimization in Federated Learning
Dec 27, 2023Federated learning (FL) enables multiple clients to collaboratively learn a shared model without sharing their individual data. Concerns about utility, privacy, and training efficiency in FL have garnered significant research attention. Differential privacy has emerged as a prevalent technique in FL, safeguarding the privacy of individual user data while impacting utility and training efficiency. Within Differential Privacy Federated Learning (DPFL), previous studies have primarily focused on the utility-privacy trade-off, neglecting training efficiency, which is crucial for timely completion. Moreover, differential privacy achieves privacy by introducing controlled randomness (noise) on selected clients in each communication round. Previous work has mainly examined the impact of noise level ($\sigma$) and communication rounds ($T$) on the privacy-utility dynamic, overlooking other influential factors like the sample ratio ($q$, the proportion of selected clients). This paper systematically formulates an efficiency-constrained utility-privacy bi-objective optimization problem in DPFL, focusing on $\sigma$, $T$, and $q$. We provide a comprehensive theoretical analysis, yielding analytical solutions for the Pareto front. Extensive empirical experiments verify the validity and efficacy of our analysis, offering valuable guidance for low-cost parameter design in DPFL.
Quantitative perfusion maps using a novelty spatiotemporal convolutional neural network
Dec 08, 2023Dynamic susceptibility contrast magnetic resonance imaging (DSC-MRI) is widely used to evaluate acute ischemic stroke to distinguish salvageable tissue and infarct core. For this purpose, traditional methods employ deconvolution techniques, like singular value decomposition, which are known to be vulnerable to noise, potentially distorting the derived perfusion parameters. However, deep learning technology could leverage it, which can accurately estimate clinical perfusion parameters compared to traditional clinical approaches. Therefore, this study presents a perfusion parameters estimation network that considers spatial and temporal information, the Spatiotemporal Network (ST-Net), for the first time. The proposed network comprises a designed physical loss function to enhance model performance further. The results indicate that the network can accurately estimate perfusion parameters, including cerebral blood volume (CBV), cerebral blood flow (CBF), and time to maximum of the residual function (Tmax). The structural similarity index (SSIM) mean values for CBV, CBF, and Tmax parameters were 0.952, 0.943, and 0.863, respectively. The DICE score for the hypo-perfused region reached 0.859, demonstrating high consistency. The proposed model also maintains time efficiency, closely approaching the performance of commercial gold-standard software.
Grounding Foundation Models through Federated Transfer Learning: A General Framework
Dec 05, 2023Foundation Models (FMs) such as GPT-4 encoded with vast knowledge and powerful emergent abilities have achieved remarkable success in various natural language processing and computer vision tasks. Grounding FMs by adapting them to domain-specific tasks or augmenting them with domain-specific knowledge enables us to exploit the full potential of FMs. However, grounding FMs faces several challenges, stemming primarily from constrained computing resources, data privacy, model heterogeneity, and model ownership. Federated Transfer Learning (FTL), the combination of federated learning and transfer learning, provides promising solutions to address these challenges. In recent years, the need for grounding FMs leveraging FTL, coined FTL-FM, has arisen strongly in both academia and industry. Motivated by the strong growth in FTL-FM research and the potential impact of FTL-FM on industrial applications, we propose an FTL-FM framework that formulates problems of grounding FMs in the federated learning setting, construct a detailed taxonomy based on the FTL-FM framework to categorize state-of-the-art FTL-FM works, and comprehensively overview FTL-FM works based on the proposed taxonomy. We also establish correspondences between FTL-FM and conventional phases of adapting FM so that FM practitioners can align their research works with FTL-FM. In addition, we overview advanced efficiency-improving and privacy-preserving techniques because efficiency and privacy are critical concerns in FTL-FM. Last, we discuss opportunities and future research directions of FTL-FM.
FATE-LLM: A Industrial Grade Federated Learning Framework for Large Language Models
Oct 16, 2023
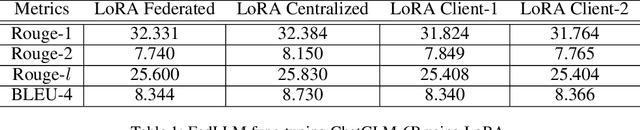


Large Language Models (LLMs), such as ChatGPT, LLaMA, GLM, and PaLM, have exhibited remarkable performances across various tasks in recent years. However, LLMs face two main challenges in real-world applications. One challenge is that training LLMs consumes vast computing resources, preventing LLMs from being adopted by small and medium-sized enterprises with limited computing resources. Another is that training LLM requires a large amount of high-quality data, which are often scattered among enterprises. To address these challenges, we propose FATE-LLM, an industrial-grade federated learning framework for large language models. FATE-LLM (1) facilitates federated learning for large language models (coined FedLLM); (2) promotes efficient training of FedLLM using parameter-efficient fine-tuning methods; (3) protects the intellectual property of LLMs; (4) preserves data privacy during training and inference through privacy-preserving mechanisms. We release the code of FATE-LLM at https://github.com/FederatedAI/FATE-LLM to facilitate the research of FedLLM and enable a broad range of industrial applications.
Privacy in Large Language Models: Attacks, Defenses and Future Directions
Oct 16, 2023The advancement of large language models (LLMs) has significantly enhanced the ability to effectively tackle various downstream NLP tasks and unify these tasks into generative pipelines. On the one hand, powerful language models, trained on massive textual data, have brought unparalleled accessibility and usability for both models and users. On the other hand, unrestricted access to these models can also introduce potential malicious and unintentional privacy risks. Despite ongoing efforts to address the safety and privacy concerns associated with LLMs, the problem remains unresolved. In this paper, we provide a comprehensive analysis of the current privacy attacks targeting LLMs and categorize them according to the adversary's assumed capabilities to shed light on the potential vulnerabilities present in LLMs. Then, we present a detailed overview of prominent defense strategies that have been developed to counter these privacy attacks. Beyond existing works, we identify upcoming privacy concerns as LLMs evolve. Lastly, we point out several potential avenues for future exploration.