 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYang Ma
PTR-PPO: Proximal Policy Optimization with Prioritized Trajectory Replay
Dec 08, 2021
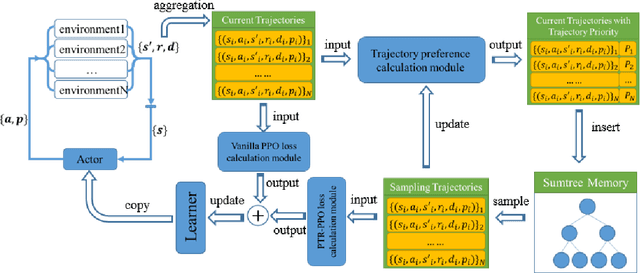
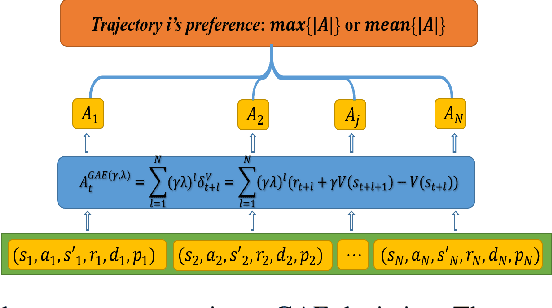

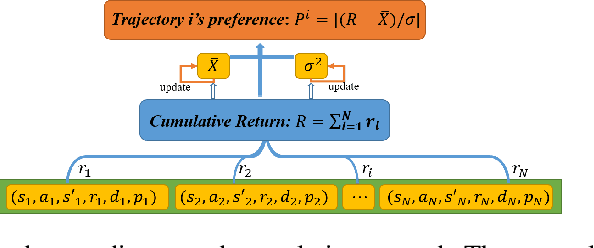
On-policy deep reinforcement learning algorithms have low data utilization and require significant experience for policy improvement. This paper proposes a proximal policy optimization algorithm with prioritized trajectory replay (PTR-PPO) that combines on-policy and off-policy methods to improve sampling efficiency by prioritizing the replay of trajectories generated by old policies. We first design three trajectory priorities based on the characteristics of trajectories: the first two being max and mean trajectory priorities based on one-step empirical generalized advantage estimation (GAE) values and the last being reward trajectory priorities based on normalized undiscounted cumulative reward. Then, we incorporate the prioritized trajectory replay into the PPO algorithm, propose a truncated importance weight method to overcome the high variance caused by large importance weights under multistep experience, and design a policy improvement loss function for PPO under off-policy conditions. We evaluate the performance of PTR-PPO in a set of Atari discrete control tasks, achieving state-of-the-art performance. In addition, by analyzing the heatmap of priority changes at various locations in the priority memory during training, we find that memory size and rollout length can have a significant impact on the distribution of trajectory priorities and, hence, on the performance of the algorithm.
Multiple Sclerosis Lesion Analysis in Brain Magnetic Resonance Images: Techniques and Clinical Applications
Apr 20, 2021
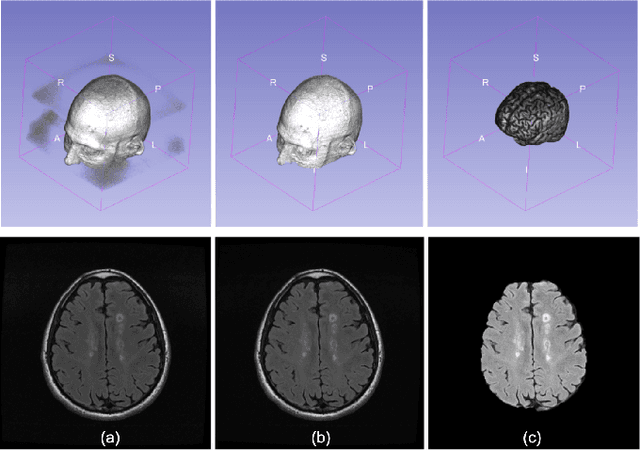
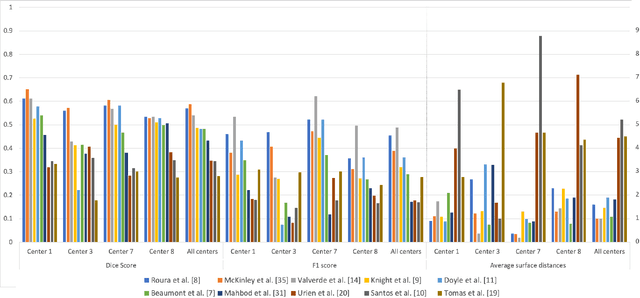
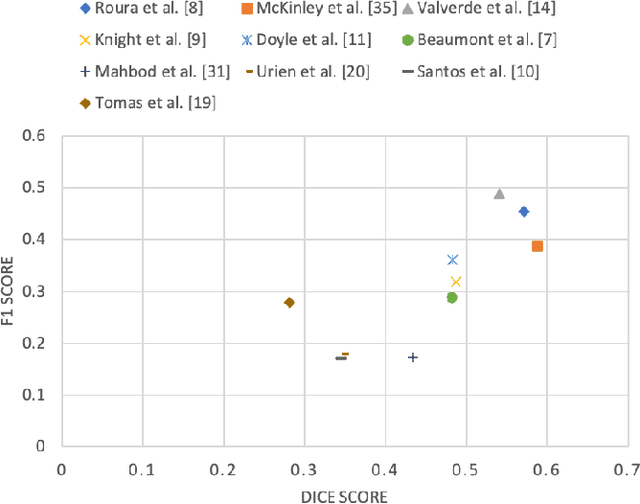
Multiple sclerosis (MS) is a chronic inflammatory and degenerative disease of the central nervous system, characterized by the appearance of focal lesions in the white and gray matter that topographically correlate with an individual patient's neurological symptoms and signs. Magnetic resonance imaging (MRI) provides detailed in-vivo structural information, permitting the quantification and categorization of MS lesions that critically inform disease management. Traditionally, MS lesions have been manually annotated on 2D MRI slices, a process that is inefficient and prone to inter-/intra-observer errors. Recently, automated statistical imaging analysis techniques have been proposed to extract and segment MS lesions based on MRI voxel intensity. However, their effectiveness is limited by the heterogeneity of both MRI data acquisition techniques and the appearance of MS lesions. By learning complex lesion representations directly from images, deep learning techniques have achieved remarkable breakthroughs in the MS lesion segmentation task. Here, we provide a comprehensive review of state-of-the-art automatic statistical and deep-learning MS segmentation methods and discuss current and future clinical applications. Further, we review technical strategies, such as domain adaptation, to enhance MS lesion segmentation in real-world clinical settings.
PILOT: A Pixel Intensity Driven Illuminant Color Estimation Framework for Color Constancy
Jun 25, 2018



In this study, a CNN based Pixel Intensity driven iLluminant cOlor esTimation framework, PILOT, is proposed. The framework consists of a local illuminant estimation module and an illuminant uncertainty prediction module, obtained using a 3-phase training approach. The network with the well-designed microarchitecture of distillation building block and the macroarchitecture of bifurcated organization is of great representational capacity and efficacy for color-relevant vision tasks, which helps obtain a >20% relative improvement over prior algorithms and achieve state-of-the-art accuracy of illuminant estimation on benchmark datasets. The proposed framework is also computationally efficient and parameter-economic, making it suitable for applications deployed on mobile platforms. The great interpretability also makes PILOT possible to serve as a guidance for designing statistics-based models for those low-end devices with tight budgets of power consumption and computational capacity.