 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYanlin Chen
Thyroid ultrasound diagnosis improvement via multi-view self-supervised learning and two-stage pre-training
Feb 18, 2024
Thyroid nodule classification and segmentation in ultrasound images are crucial for computer-aided diagnosis; however, they face limitations owing to insufficient labeled data. In this study, we proposed a multi-view contrastive self-supervised method to improve thyroid nodule classification and segmentation performance with limited manual labels. Our method aligns the transverse and longitudinal views of the same nodule, thereby enabling the model to focus more on the nodule area. We designed an adaptive loss function that eliminates the limitations of the paired data. Additionally, we adopted a two-stage pre-training to exploit the pre-training on ImageNet and thyroid ultrasound images. Extensive experiments were conducted on a large-scale dataset collected from multiple centers. The results showed that the proposed method significantly improves nodule classification and segmentation performance with limited manual labels and outperforms state-of-the-art self-supervised methods. The two-stage pre-training also significantly exceeded ImageNet pre-training.
OnUVS: Online Feature Decoupling Framework for High-Fidelity Ultrasound Video Synthesis
Aug 16, 2023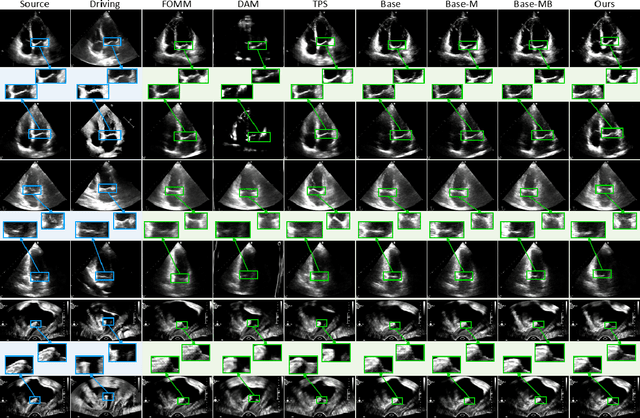
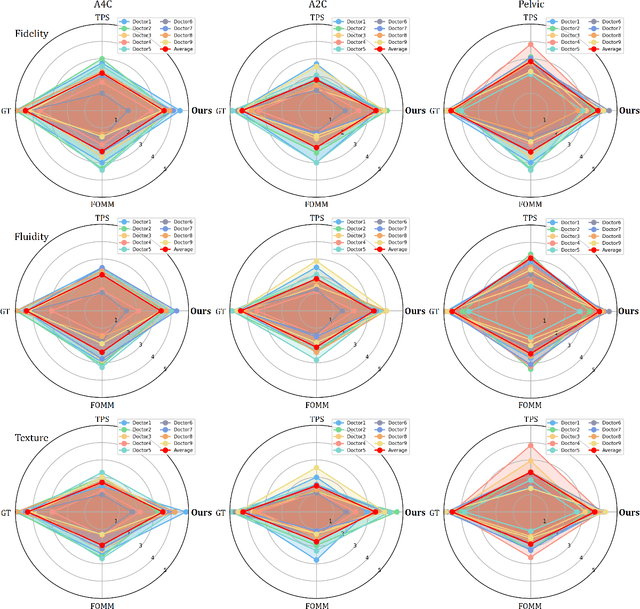
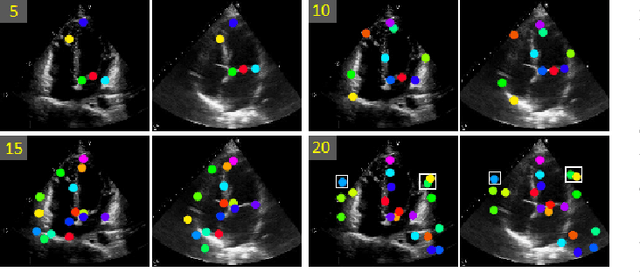
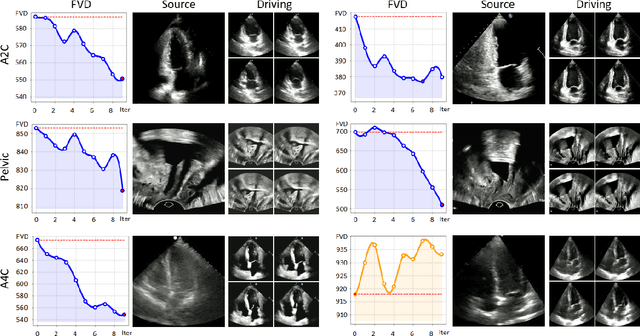
Ultrasound (US) imaging is indispensable in clinical practice. To diagnose certain diseases, sonographers must observe corresponding dynamic anatomic structures to gather comprehensive information. However, the limited availability of specific US video cases causes teaching difficulties in identifying corresponding diseases, which potentially impacts the detection rate of such cases. The synthesis of US videos may represent a promising solution to this issue. Nevertheless, it is challenging to accurately animate the intricate motion of dynamic anatomic structures while preserving image fidelity. To address this, we present a novel online feature-decoupling framework called OnUVS for high-fidelity US video synthesis. Our highlights can be summarized by four aspects. First, we introduced anatomic information into keypoint learning through a weakly-supervised training strategy, resulting in improved preservation of anatomical integrity and motion while minimizing the labeling burden. Second, to better preserve the integrity and textural information of US images, we implemented a dual-decoder that decouples the content and textural features in the generator. Third, we adopted a multiple-feature discriminator to extract a comprehensive range of visual cues, thereby enhancing the sharpness and fine details of the generated videos. Fourth, we constrained the motion trajectories of keypoints during online learning to enhance the fluidity of generated videos. Our validation and user studies on in-house echocardiographic and pelvic floor US videos showed that OnUVS synthesizes US videos with high fidelity.
SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images
Apr 25, 2022



The existing deep learning fusion methods mainly concentrate on the convolutional neural networks, and few attempts are made with transformer. Meanwhile, the convolutional operation is a content-independent interaction between the image and convolution kernel, which may lose some important contexts and further limit fusion performance. Towards this end, we present a simple and strong fusion baseline for infrared and visible images, namely\textit{ Residual Swin Transformer Fusion Network}, termed as SwinFuse. Our SwinFuse includes three parts: the global feature extraction, fusion layer and feature reconstruction. In particular, we build a fully attentional feature encoding backbone to model the long-range dependency, which is a pure transformer network and has a stronger representation ability compared with the convolutional neural networks. Moreover, we design a novel feature fusion strategy based on $L_{1}$-norm for sequence matrices, and measure the corresponding activity levels from row and column vector dimensions, which can well retain competitive infrared brightness and distinct visible details. Finally, we testify our SwinFuse with nine state-of-the-art traditional and deep learning methods on three different datasets through subjective observations and objective comparisons, and the experimental results manifest that the proposed SwinFuse obtains surprising fusion performance with strong generalization ability and competitive computational efficiency. The code will be available at https://github.com/Zhishe-Wang/SwinFuse.
Infrared and Visible Image Fusion via Interactive Compensatory Attention Adversarial Learning
Mar 29, 2022



The existing generative adversarial fusion methods generally concatenate source images and extract local features through convolution operation, without considering their global characteristics, which tends to produce an unbalanced result and is biased towards the infrared image or visible image. Toward this end, we propose a novel end-to-end mode based on generative adversarial training to achieve better fusion balance, termed as \textit{interactive compensatory attention fusion network} (ICAFusion). In particular, in the generator, we construct a multi-level encoder-decoder network with a triple path, and adopt infrared and visible paths to provide additional intensity and gradient information. Moreover, we develop interactive and compensatory attention modules to communicate their pathwise information, and model their long-range dependencies to generate attention maps, which can more focus on infrared target perception and visible detail characterization, and further increase the representation power for feature extraction and feature reconstruction. In addition, dual discriminators are designed to identify the similar distribution between fused result and source images, and the generator is optimized to produce a more balanced result. Extensive experiments illustrate that our ICAFusion obtains superior fusion performance and better generalization ability, which precedes other advanced methods in the subjective visual description and objective metric evaluation. Our codes will be public at \url{https://github.com/Zhishe-Wang/ICAFusion}
Quantum Algorithms and Lower Bounds for Linear Regression with Norm Constraints
Oct 25, 2021


Lasso and Ridge are important minimization problems in machine learning and statistics. They are versions of linear regression with squared loss where the vector $\theta\in\mathbb{R}^d$ of coefficients is constrained in either $\ell_1$-norm (for Lasso) or in $\ell_2$-norm (for Ridge). We study the complexity of quantum algorithms for finding $\varepsilon$-minimizers for these minimization problems. We show that for Lasso we can get a quadratic quantum speedup in terms of $d$ by speeding up the cost-per-iteration of the Frank-Wolfe algorithm, while for Ridge the best quantum algorithms are linear in $d$, as are the best classical algorithms.
Semi-supervised Optimal Transport with Self-paced Ensemble for Cross-hospital Sepsis Early Detection
Jun 18, 2021



The utilization of computer technology to solve problems in medical scenarios has attracted considerable attention in recent years, which still has great potential and space for exploration. Among them, machine learning has been widely used in the prediction, diagnosis and even treatment of Sepsis. However, state-of-the-art methods require large amounts of labeled medical data for supervised learning. In real-world applications, the lack of labeled data will cause enormous obstacles if one hospital wants to deploy a new Sepsis detection system. Different from the supervised learning setting, we need to use known information (e.g., from another hospital with rich labeled data) to help build a model with acceptable performance, i.e., transfer learning. In this paper, we propose a semi-supervised optimal transport with self-paced ensemble framework for Sepsis early detection, called SPSSOT, to transfer knowledge from the other that has rich labeled data. In SPSSOT, we first extract the same clinical indicators from the source domain (e.g., hospital with rich labeled data) and the target domain (e.g., hospital with little labeled data), then we combine the semi-supervised domain adaptation based on optimal transport theory with self-paced under-sampling to avoid a negative transfer possibly caused by covariate shift and class imbalance. On the whole, SPSSOT is an end-to-end transfer learning method for Sepsis early detection which can automatically select suitable samples from two domains respectively according to the number of iterations and align feature space of two domains. Extensive experiments on two open clinical datasets demonstrate that comparing with other methods, our proposed SPSSOT, can significantly improve the AUC values with only 1% labeled data in the target domain in two transfer learning scenarios, MIMIC $rightarrow$ Challenge and Challenge $rightarrow$ MIMIC.
To Explain or Not to Explain: A Study on the Necessity of Explanations for Autonomous Vehicles
Jun 21, 2020



Explainable AI, in the context of autonomous systems, like self driving cars, has drawn broad interests from researchers. Recent studies have found that providing explanations for an autonomous vehicle actions has many benefits, e.g., increase trust and acceptance, but put little emphasis on when an explanation is needed and how the content of explanation changes with context. In this work, we investigate which scenarios people need explanations and how the critical degree of explanation shifts with situations and driver types. Through a user experiment, we ask participants to evaluate how necessary an explanation is and measure the impact on their trust in the self driving cars in different contexts. We also present a self driving explanation dataset with first person explanations and associated measure of the necessity for 1103 video clips, augmenting the Berkeley Deep Drive Attention dataset. Additionally, we propose a learning based model that predicts how necessary an explanation for a given situation in real time, using camera data inputs. Our research reveals that driver types and context dictates whether or not an explanation is necessary and what is helpful for improved interaction and understanding.