 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYaxiong Wang
Beyond Known Clusters: Probe New Prototypes for Efficient Generalized Class Discovery
Apr 13, 2024
Generalized Class Discovery (GCD) aims to dynamically assign labels to unlabelled data partially based on knowledge learned from labelled data, where the unlabelled data may come from known or novel classes. The prevailing approach generally involves clustering across all data and learning conceptions by prototypical contrastive learning. However, existing methods largely hinge on the performance of clustering algorithms and are thus subject to their inherent limitations. Firstly, the estimated cluster number is often smaller than the ground truth, making the existing methods suffer from the lack of prototypes for comprehensive conception learning. To address this issue, we propose an adaptive probing mechanism that introduces learnable potential prototypes to expand cluster prototypes (centers). As there is no ground truth for the potential prototype, we develop a self-supervised prototype learning framework to optimize the potential prototype in an end-to-end fashion. Secondly, clustering is computationally intensive, and the conventional strategy of clustering both labelled and unlabelled instances exacerbates this issue. To counteract this inefficiency, we opt to cluster only the unlabelled instances and subsequently expand the cluster prototypes with our introduced potential prototypes to fast explore novel classes. Despite the simplicity of our proposed method, extensive empirical analysis on a wide range of datasets confirms that our method consistently delivers state-of-the-art results. Specifically, our method surpasses the nearest competitor by a significant margin of \textbf{9.7}$\%$ within the Stanford Cars dataset and \textbf{12$\times$} clustering efficiency within the Herbarium 19 dataset. We will make the code and checkpoints publicly available at \url{https://github.com/xjtuYW/PNP.git}.
Towards Geometric-Photometric Joint Alignment for Facial Mesh Registration
Mar 05, 2024
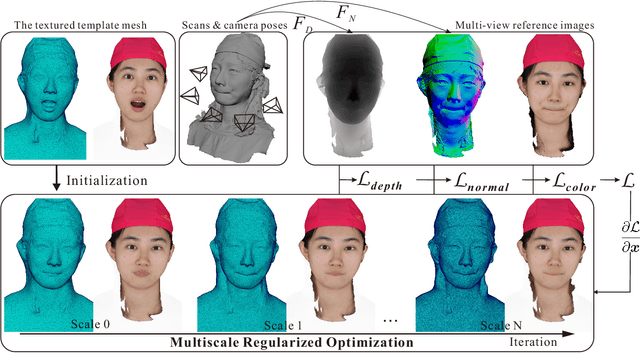

This paper presents a Geometric-Photometric Joint Alignment(GPJA) method, for accurately aligning human expressions by combining geometry and photometric information. Common practices for registering human heads typically involve aligning landmarks with facial template meshes using geometry processing approaches, but often overlook photometric consistency. GPJA overcomes this limitation by leveraging differentiable rendering to align vertices with target expressions, achieving joint alignment in geometry and photometric appearances automatically, without the need for semantic annotation or aligned meshes for training. It features a holistic rendering alignment strategy and a multiscale regularized optimization for robust and fast convergence. The method utilizes derivatives at vertex positions for supervision and employs a gradient-based algorithm which guarantees smoothness and avoids topological defects during the geometry evolution. Experimental results demonstrate faithful alignment under various expressions, surpassing the conventional ICP-based methods and the state-of-the-art deep learning based method. In practical, our method enhances the efficiency of obtaining topology-consistent face models from multi-view stereo facial scanning.
Optimal Noise pursuit for Augmenting Text-to-Video Generation
Nov 02, 2023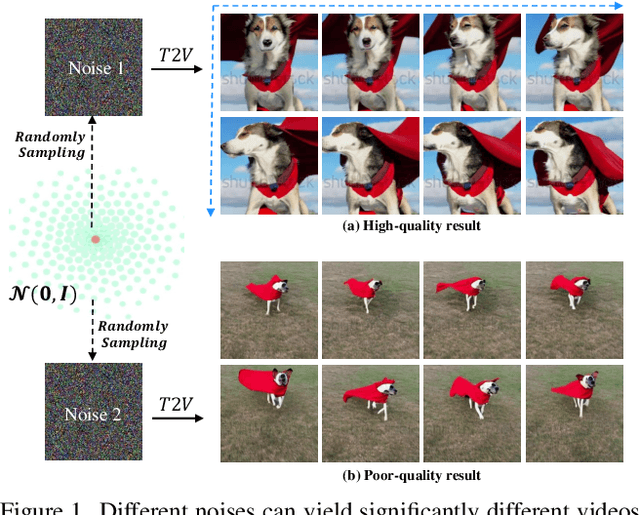

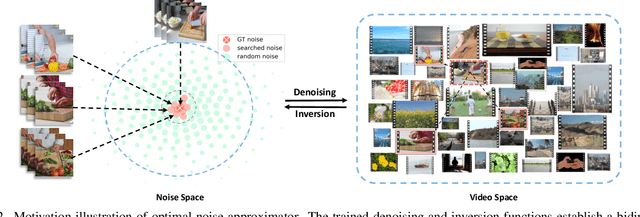

Despite the remarkable progress in text-to-video generation, existing diffusion-based models often exhibit instability in terms of noise during inference. Specifically, when different noises are fed for the given text, these models produce videos that differ significantly in terms of both frame quality and temporal consistency. With this observation, we posit that there exists an optimal noise matched to each textual input; however, the widely adopted strategies of random noise sampling often fail to capture it. In this paper, we argue that the optimal noise can be approached through inverting the groundtruth video using the established noise-video mapping derived from the diffusion model. Nevertheless, the groundtruth video for the text prompt is not available during inference. To address this challenge, we propose to approximate the optimal noise via a search and inversion pipeline. Given a text prompt, we initially search for a video from a predefined candidate pool that closely relates to the text prompt. Subsequently, we invert the searched video into the noise space, which serves as an improved noise prompt for the textual input. In addition to addressing noise, we also observe that the text prompt with richer details often leads to higher-quality videos. Motivated by this, we further design a semantic-preserving rewriter to enrich the text prompt, where a reference-guided rewriting is devised for reasonable details compensation, and a denoising with a hybrid semantics strategy is proposed to preserve the semantic consistency. Extensive experiments on the WebVid-10M benchmark show that our proposed method can improve the text-to-video models with a clear margin, while introducing no optimization burden.
Dual Relation Alignment for Composed Image Retrieval
Sep 05, 2023
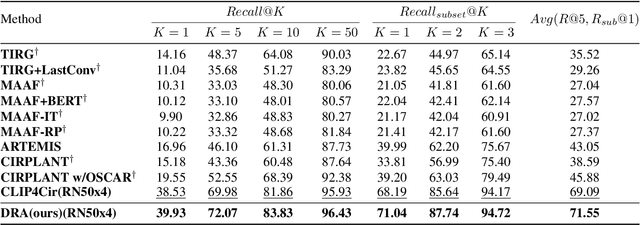

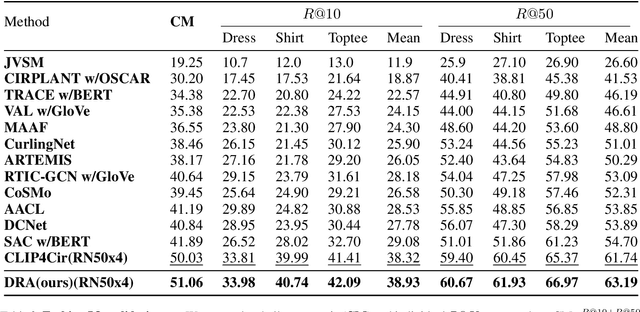
Composed image retrieval, a task involving the search for a target image using a reference image and a complementary text as the query, has witnessed significant advancements owing to the progress made in cross-modal modeling. Unlike the general image-text retrieval problem with only one alignment relation, i.e., image-text, we argue for the existence of two types of relations in composed image retrieval. The explicit relation pertains to the reference image & complementary text-target image, which is commonly exploited by existing methods. Besides this intuitive relation, the observations during our practice have uncovered another implicit yet crucial relation, i.e., reference image & target image-complementary text, since we found that the complementary text can be inferred by studying the relation between the target image and the reference image. Regrettably, existing methods largely focus on leveraging the explicit relation to learn their networks, while overlooking the implicit relation. In response to this weakness, We propose a new framework for composed image retrieval, termed dual relation alignment, which integrates both explicit and implicit relations to fully exploit the correlations among the triplets. Specifically, we design a vision compositor to fuse reference image and target image at first, then the resulted representation will serve two roles: (1) counterpart for semantic alignment with the complementary text and (2) compensation for the complementary text to boost the explicit relation modeling, thereby implant the implicit relation into the alignment learning. Our method is evaluated on two popular datasets, CIRR and FashionIQ, through extensive experiments. The results confirm the effectiveness of our dual-relation learning in substantially enhancing composed image retrieval performance.
DiverseMotion: Towards Diverse Human Motion Generation via Discrete Diffusion
Sep 04, 2023We present DiverseMotion, a new approach for synthesizing high-quality human motions conditioned on textual descriptions while preserving motion diversity.Despite the recent significant process in text-based human motion generation,existing methods often prioritize fitting training motions at the expense of action diversity. Consequently, striking a balance between motion quality and diversity remains an unresolved challenge. This problem is compounded by two key factors: 1) the lack of diversity in motion-caption pairs in existing benchmarks and 2) the unilateral and biased semantic understanding of the text prompt, focusing primarily on the verb component while neglecting the nuanced distinctions indicated by other words.In response to the first issue, we construct a large-scale Wild Motion-Caption dataset (WMC) to extend the restricted action boundary of existing well-annotated datasets, enabling the learning of diverse motions through a more extensive range of actions. To this end, a motion BLIP is trained upon a pretrained vision-language model, then we automatically generate diverse motion captions for the collected motion sequences. As a result, we finally build a dataset comprising 8,888 motions coupled with 141k text.To comprehensively understand the text command, we propose a Hierarchical Semantic Aggregation (HSA) module to capture the fine-grained semantics.Finally,we involve the above two designs into an effective Motion Discrete Diffusion (MDD) framework to strike a balance between motion quality and diversity. Extensive experiments on HumanML3D and KIT-ML show that our DiverseMotion achieves the state-of-the-art motion quality and competitive motion diversity. Dataset, code, and pretrained models will be released to reproduce all of our results.
Knowledge Transfer-Driven Few-Shot Class-Incremental Learning
Jun 19, 2023
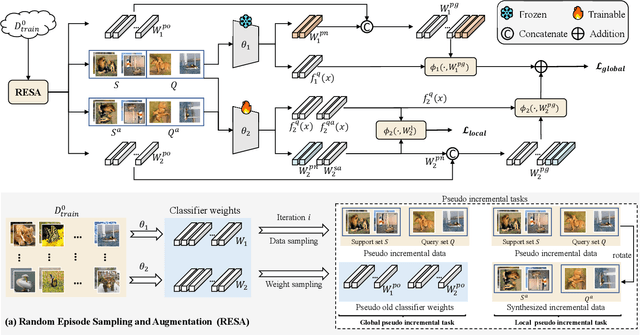
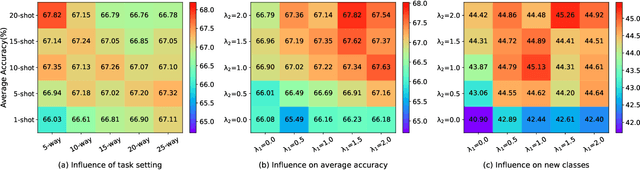
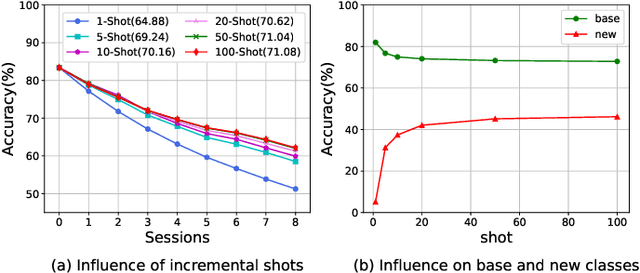
Few-shot class-incremental learning (FSCIL) aims to continually learn new classes using a few samples while not forgetting the old classes. The key of this task is effective knowledge transfer from the base session to the incremental sessions. Despite the advance of existing FSCIL methods, the proposed knowledge transfer learning schemes are sub-optimal due to the insufficient optimization for the model's plasticity. To address this issue, we propose a Random Episode Sampling and Augmentation (RESA) strategy that relies on diverse pseudo incremental tasks as agents to achieve the knowledge transfer. Concretely, RESA mimics the real incremental setting and constructs pseudo incremental tasks globally and locally, where the global pseudo incremental tasks are designed to coincide with the learning objective of FSCIL and the local pseudo incremental tasks are designed to improve the model's plasticity, respectively. Furthermore, to make convincing incremental predictions, we introduce a complementary model with a squared Euclidean-distance classifier as the auxiliary module, which couples with the widely used cosine classifier to form our whole architecture. By such a way, equipped with model decoupling strategy, we can maintain the model's stability while enhancing the model's plasticity. Extensive quantitative and qualitative experiments on three popular FSCIL benchmark datasets demonstrate that our proposed method, named Knowledge Transfer-driven Relation Complementation Network (KT-RCNet), outperforms almost all prior methods. More precisely, the average accuracy of our proposed KT-RCNet outperforms the second-best method by a margin of 5.26%, 3.49%, and 2.25% on miniImageNet, CIFAR100, and CUB200, respectively. Our code is available at https://github.com/YeZiLaiXi/KT-RCNet.git.
Towards Unified Text-based Person Retrieval: A Large-scale Multi-Attribute and Language Search Benchmark
Jun 06, 2023
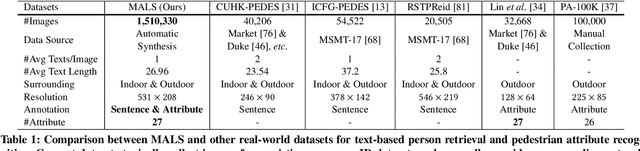
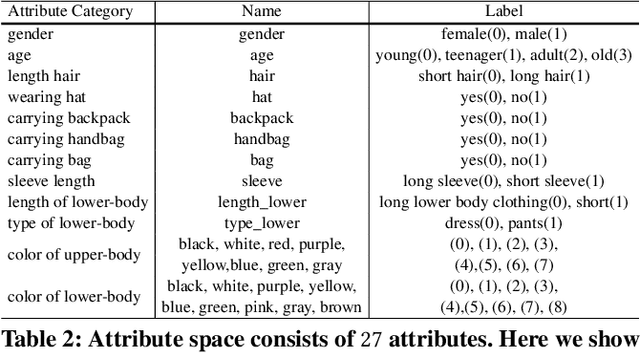

In this paper, we introduce a large Multi-Attribute and Language Search dataset for text-based person retrieval, called MALS, and explore the feasibility of performing pre-training on both attribute recognition and image-text matching tasks in one stone. In particular, MALS contains 1,510,330 image-text pairs, which is about 37.5 times larger than prevailing CUHK-PEDES, and all images are annotated with 27 attributes. Considering the privacy concerns and annotation costs, we leverage the off-the-shelf diffusion models to generate the dataset. To verify the feasibility of learning from the generated data, we develop a new joint Attribute Prompt Learning and Text Matching Learning (APTM) framework, considering the shared knowledge between attribute and text. As the name implies, APTM contains an attribute prompt learning stream and a text matching learning stream. (1) The attribute prompt learning leverages the attribute prompts for image-attribute alignment, which enhances the text matching learning. (2) The text matching learning facilitates the representation learning on fine-grained details, and in turn, boosts the attribute prompt learning. Extensive experiments validate the effectiveness of the pre-training on MALS, achieving state-of-the-art retrieval performance via APTM on three challenging real-world benchmarks. In particular, APTM achieves a consistent improvement of +6.60%, +7.39%, and +15.90% Recall@1 accuracy on CUHK-PEDES, ICFG-PEDES, and RSTPReid datasets by a clear margin, respectively.
Multimodal Learning for Non-small Cell Lung Cancer Prognosis
Nov 07, 2022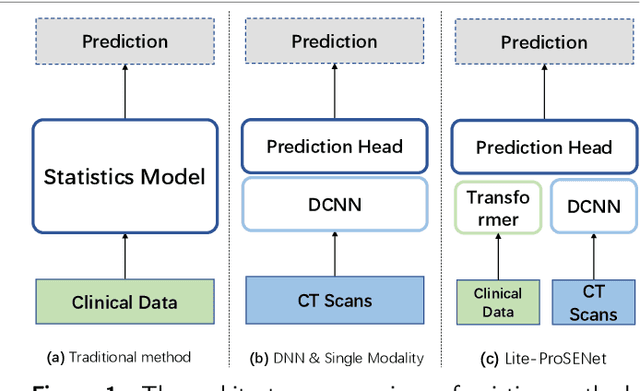
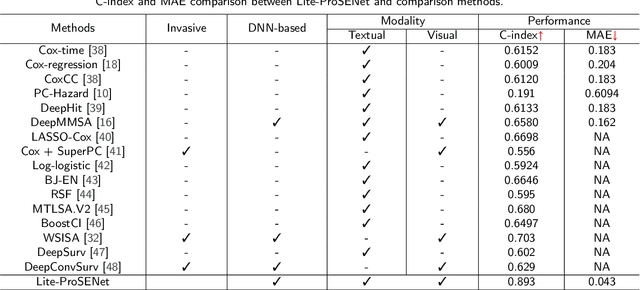
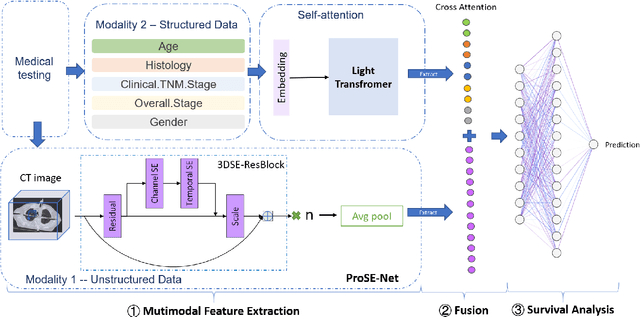
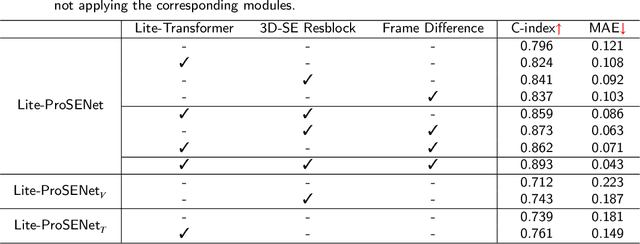
This paper focuses on the task of survival time analysis for lung cancer. Although much progress has been made in this problem in recent years, the performance of existing methods is still far from satisfactory. Traditional and some deep learning-based survival time analyses for lung cancer are mostly based on textual clinical information such as staging, age, histology, etc. Unlike existing methods that predicting on the single modality, we observe that a human clinician usually takes multimodal data such as text clinical data and visual scans to estimate survival time. Motivated by this, in this work, we contribute a smart cross-modality network for survival analysis network named Lite-ProSENet that simulates a human's manner of decision making. Extensive experiments were conducted using data from 422 NSCLC patients from The Cancer Imaging Archive (TCIA). The results show that our Lite-ProSENet outperforms favorably again all comparison methods and achieves the new state of the art with the 89.3% on concordance. The code will be made publicly available.
Learning a Condensed Frame for Memory-Efficient Video Class-Incremental Learning
Nov 02, 2022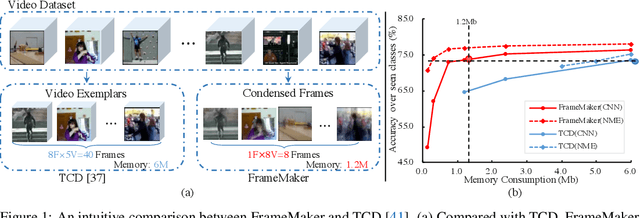
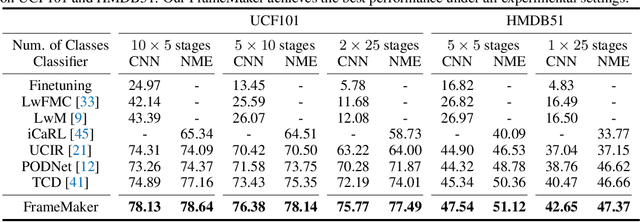
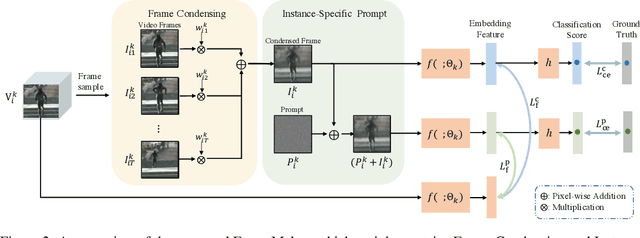
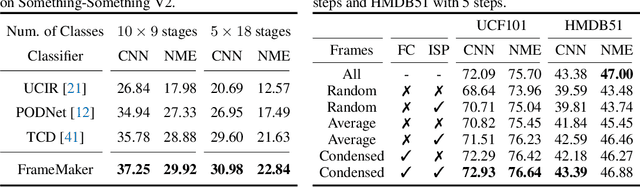
Recent incremental learning for action recognition usually stores representative videos to mitigate catastrophic forgetting. However, only a few bulky videos can be stored due to the limited memory. To address this problem, we propose FrameMaker, a memory-efficient video class-incremental learning approach that learns to produce a condensed frame for each selected video. Specifically, FrameMaker is mainly composed of two crucial components: Frame Condensing and Instance-Specific Prompt. The former is to reduce the memory cost by preserving only one condensed frame instead of the whole video, while the latter aims to compensate the lost spatio-temporal details in the Frame Condensing stage. By this means, FrameMaker enables a remarkable reduction in memory but keep enough information that can be applied to following incremental tasks. Experimental results on multiple challenging benchmarks, i.e., HMDB51, UCF101 and Something-Something V2, demonstrate that FrameMaker can achieve better performance to recent advanced methods while consuming only 20% memory. Additionally, under the same memory consumption conditions, FrameMaker significantly outperforms existing state-of-the-arts by a convincing margin.
Generating Superpixels for High-resolution Images with Decoupled Patch Calibration
Aug 23, 2021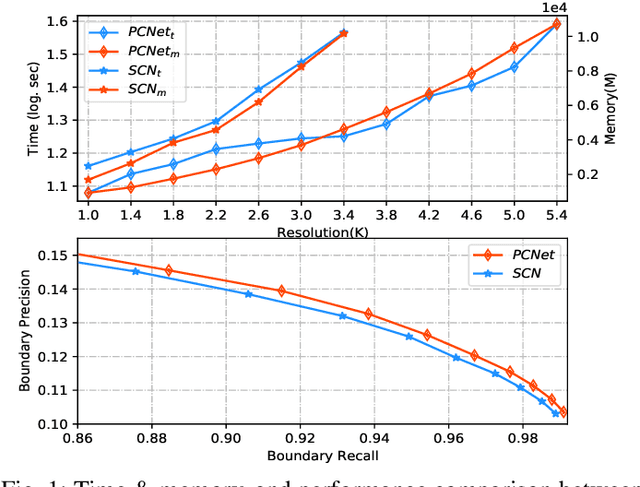

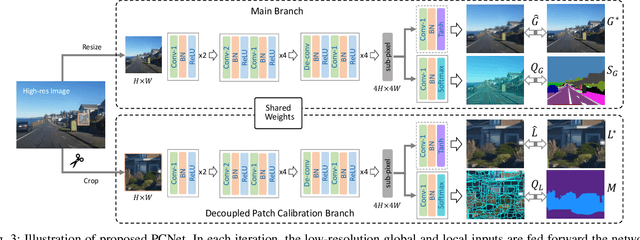
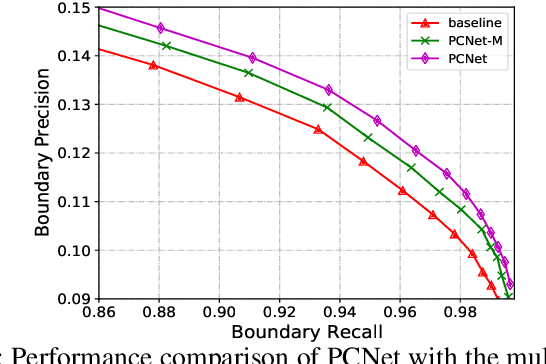
Superpixel segmentation has recently seen important progress benefiting from the advances in differentiable deep learning. However, the very high-resolution superpixel segmentation still remains challenging due to the expensive memory and computation cost, making the current advanced superpixel networks fail to process. In this paper, we devise Patch Calibration Networks (PCNet), aiming to efficiently and accurately implement high-resolution superpixel segmentation. PCNet follows the principle of producing high-resolution output from low-resolution input for saving GPU memory and relieving computation cost. To recall the fine details destroyed by the down-sampling operation, we propose a novel Decoupled Patch Calibration (DPC) branch for collaboratively augment the main superpixel generation branch. In particular, DPC takes a local patch from the high-resolution images and dynamically generates a binary mask to impose the network to focus on region boundaries. By sharing the parameters of DPC and main branches, the fine-detailed knowledge learned from high-resolution patches will be transferred to help calibrate the destroyed information. To the best of our knowledge, we make the first attempt to consider the deep-learning-based superpixel generation for high-resolution cases. To facilitate this research, we build evaluation benchmarks from two public datasets and one new constructed one, covering a wide range of diversities from fine-grained human parts to cityscapes. Extensive experiments demonstrate that our PCNet can not only perform favorably against the state-of-the-arts in the quantitative results but also improve the resolution upper bound from 3K to 5K on 1080Ti GPUs.