 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYazhou Yao
AdaFPP: Adapt-Focused Bi-Propagating Prototype Learning for Panoramic Activity Recognition
May 04, 2024
Panoramic Activity Recognition (PAR) aims to identify multi-granularity behaviors performed by multiple persons in panoramic scenes, including individual activities, group activities, and global activities. Previous methods 1) heavily rely on manually annotated detection boxes in training and inference, hindering further practical deployment; or 2) directly employ normal detectors to detect multiple persons with varying size and spatial occlusion in panoramic scenes, blocking the performance gain of PAR. To this end, we consider learning a detector adapting varying-size occluded persons, which is optimized along with the recognition module in the all-in-one framework. Therefore, we propose a novel Adapt-Focused bi-Propagating Prototype learning (AdaFPP) framework to jointly recognize individual, group, and global activities in panoramic activity scenes by learning an adapt-focused detector and multi-granularity prototypes as the pretext tasks in an end-to-end way. Specifically, to accommodate the varying sizes and spatial occlusion of multiple persons in crowed panoramic scenes, we introduce a panoramic adapt-focuser, achieving the size-adapting detection of individuals by comprehensively selecting and performing fine-grained detections on object-dense sub-regions identified through original detections. In addition, to mitigate information loss due to inaccurate individual localizations, we introduce a bi-propagation prototyper that promotes closed-loop interaction and informative consistency across different granularities by facilitating bidirectional information propagation among the individual, group, and global levels. Extensive experiments demonstrate the significant performance of AdaFPP and emphasize its powerful applicability for PAR.
A Light-weight Transformer-based Self-supervised Matching Network for Heterogeneous Images
Apr 30, 2024Matching visible and near-infrared (NIR) images remains a significant challenge in remote sensing image fusion. The nonlinear radiometric differences between heterogeneous remote sensing images make the image matching task even more difficult. Deep learning has gained substantial attention in computer vision tasks in recent years. However, many methods rely on supervised learning and necessitate large amounts of annotated data. Nevertheless, annotated data is frequently limited in the field of remote sensing image matching. To address this challenge, this paper proposes a novel keypoint descriptor approach that obtains robust feature descriptors via a self-supervised matching network. A light-weight transformer network, termed as LTFormer, is designed to generate deep-level feature descriptors. Furthermore, we implement an innovative triplet loss function, LT Loss, to enhance the matching performance further. Our approach outperforms conventional hand-crafted local feature descriptors and proves equally competitive compared to state-of-the-art deep learning-based methods, even amidst the shortage of annotated data.
Dynamic in Static: Hybrid Visual Correspondence for Self-Supervised Video Object Segmentation
Apr 21, 2024Conventional video object segmentation (VOS) methods usually necessitate a substantial volume of pixel-level annotated video data for fully supervised learning. In this paper, we present HVC, a \textbf{h}ybrid static-dynamic \textbf{v}isual \textbf{c}orrespondence framework for self-supervised VOS. HVC extracts pseudo-dynamic signals from static images, enabling an efficient and scalable VOS model. Our approach utilizes a minimalist fully-convolutional architecture to capture static-dynamic visual correspondence in image-cropped views. To achieve this objective, we present a unified self-supervised approach to learn visual representations of static-dynamic feature similarity. Firstly, we establish static correspondence by utilizing a priori coordinate information between cropped views to guide the formation of consistent static feature representations. Subsequently, we devise a concise convolutional layer to capture the forward / backward pseudo-dynamic signals between two views, serving as cues for dynamic representations. Finally, we propose a hybrid visual correspondence loss to learn joint static and dynamic consistency representations. Our approach, without bells and whistles, necessitates only one training session using static image data, significantly reducing memory consumption ($\sim$16GB) and training time ($\sim$\textbf{2h}). Moreover, HVC achieves state-of-the-art performance in several self-supervised VOS benchmarks and additional video label propagation tasks.
Group Benefits Instances Selection for Data Purification
Mar 23, 2024Manually annotating datasets for training deep models is very labor-intensive and time-consuming. To overcome such inferiority, directly leveraging web images to conduct training data becomes a natural choice. Nevertheless, the presence of label noise in web data usually degrades the model performance. Existing methods for combating label noise are typically designed and tested on synthetic noisy datasets. However, they tend to fail to achieve satisfying results on real-world noisy datasets. To this end, we propose a method named GRIP to alleviate the noisy label problem for both synthetic and real-world datasets. Specifically, GRIP utilizes a group regularization strategy that estimates class soft labels to improve noise robustness. Soft label supervision reduces overfitting on noisy labels and learns inter-class similarities to benefit classification. Furthermore, an instance purification operation globally identifies noisy labels by measuring the difference between each training sample and its class soft label. Through operations at both group and instance levels, our approach integrates the advantages of noise-robust and noise-cleaning methods and remarkably alleviates the performance degradation caused by noisy labels. Comprehensive experimental results on synthetic and real-world datasets demonstrate the superiority of GRIP over the existing state-of-the-art methods.
Poly Kernel Inception Network for Remote Sensing Detection
Mar 20, 2024
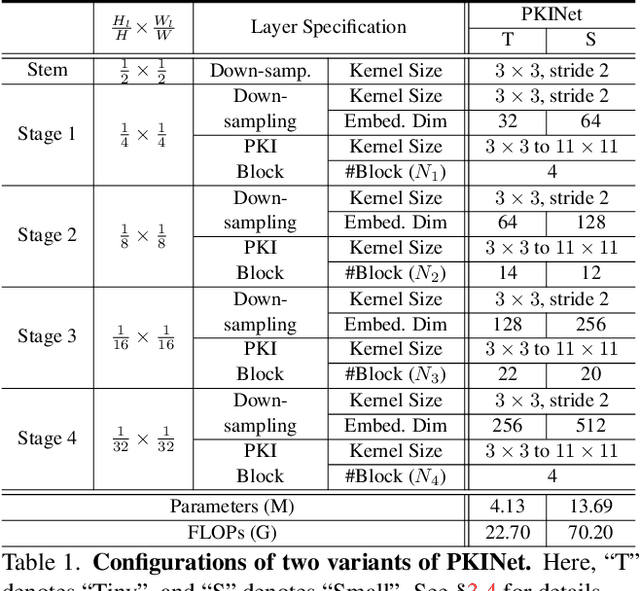
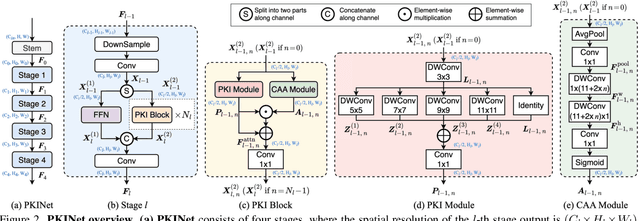
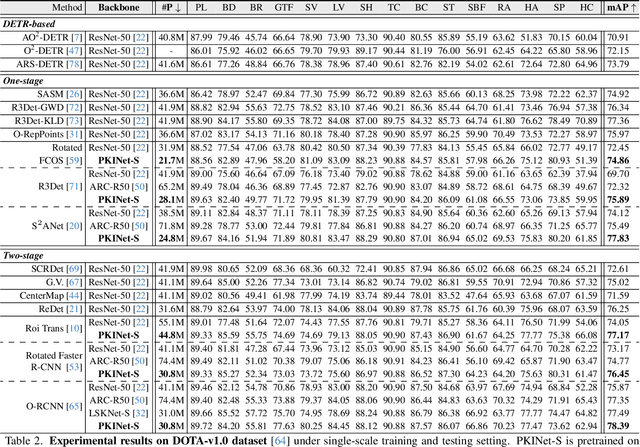
Object detection in remote sensing images (RSIs) often suffers from several increasing challenges, including the large variation in object scales and the diverse-ranging context. Prior methods tried to address these challenges by expanding the spatial receptive field of the backbone, either through large-kernel convolution or dilated convolution. However, the former typically introduces considerable background noise, while the latter risks generating overly sparse feature representations. In this paper, we introduce the Poly Kernel Inception Network (PKINet) to handle the above challenges. PKINet employs multi-scale convolution kernels without dilation to extract object features of varying scales and capture local context. In addition, a Context Anchor Attention (CAA) module is introduced in parallel to capture long-range contextual information. These two components work jointly to advance the performance of PKINet on four challenging remote sensing detection benchmarks, namely DOTA-v1.0, DOTA-v1.5, HRSC2016, and DIOR-R.
VideoMAC: Video Masked Autoencoders Meet ConvNets
Feb 29, 2024Recently, the advancement of self-supervised learning techniques, like masked autoencoders (MAE), has greatly influenced visual representation learning for images and videos. Nevertheless, it is worth noting that the predominant approaches in existing masked image / video modeling rely excessively on resource-intensive vision transformers (ViTs) as the feature encoder. In this paper, we propose a new approach termed as \textbf{VideoMAC}, which combines video masked autoencoders with resource-friendly ConvNets. Specifically, VideoMAC employs symmetric masking on randomly sampled pairs of video frames. To prevent the issue of mask pattern dissipation, we utilize ConvNets which are implemented with sparse convolutional operators as encoders. Simultaneously, we present a simple yet effective masked video modeling (MVM) approach, a dual encoder architecture comprising an online encoder and an exponential moving average target encoder, aimed to facilitate inter-frame reconstruction consistency in videos. Additionally, we demonstrate that VideoMAC, empowering classical (ResNet) / modern (ConvNeXt) convolutional encoders to harness the benefits of MVM, outperforms ViT-based approaches on downstream tasks, including video object segmentation (+\textbf{5.2\%} / \textbf{6.4\%} $\mathcal{J}\&\mathcal{F}$), body part propagation (+\textbf{6.3\%} / \textbf{3.1\%} mIoU), and human pose tracking (+\textbf{10.2\%} / \textbf{11.1\%} PCK@0.1).
Learning with Imbalanced Noisy Data by Preventing Bias in Sample Selection
Feb 17, 2024Learning with noisy labels has gained increasing attention because the inevitable imperfect labels in real-world scenarios can substantially hurt the deep model performance. Recent studies tend to regard low-loss samples as clean ones and discard high-loss ones to alleviate the negative impact of noisy labels. However, real-world datasets contain not only noisy labels but also class imbalance. The imbalance issue is prone to causing failure in the loss-based sample selection since the under-learning of tail classes also leans to produce high losses. To this end, we propose a simple yet effective method to address noisy labels in imbalanced datasets. Specifically, we propose Class-Balance-based sample Selection (CBS) to prevent the tail class samples from being neglected during training. We propose Confidence-based Sample Augmentation (CSA) for the chosen clean samples to enhance their reliability in the training process. To exploit selected noisy samples, we resort to prediction history to rectify labels of noisy samples. Moreover, we introduce the Average Confidence Margin (ACM) metric to measure the quality of corrected labels by leveraging the model's evolving training dynamics, thereby ensuring that low-quality corrected noisy samples are appropriately masked out. Lastly, consistency regularization is imposed on filtered label-corrected noisy samples to boost model performance. Comprehensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method, especially in imbalanced scenarios. Comprehensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method, especially in imbalanced scenarios.
Spatial Structure Constraints for Weakly Supervised Semantic Segmentation
Jan 20, 2024The image-level label has prevailed in weakly supervised semantic segmentation tasks due to its easy availability. Since image-level labels can only indicate the existence or absence of specific categories of objects, visualization-based techniques have been widely adopted to provide object location clues. Considering class activation maps (CAMs) can only locate the most discriminative part of objects, recent approaches usually adopt an expansion strategy to enlarge the activation area for more integral object localization. However, without proper constraints, the expanded activation will easily intrude into the background region. In this paper, we propose spatial structure constraints (SSC) for weakly supervised semantic segmentation to alleviate the unwanted object over-activation of attention expansion. Specifically, we propose a CAM-driven reconstruction module to directly reconstruct the input image from deep CAM features, which constrains the diffusion of last-layer object attention by preserving the coarse spatial structure of the image content. Moreover, we propose an activation self-modulation module to refine CAMs with finer spatial structure details by enhancing regional consistency. Without external saliency models to provide background clues, our approach achieves 72.7\% and 47.0\% mIoU on the PASCAL VOC 2012 and COCO datasets, respectively, demonstrating the superiority of our proposed approach.
Adaptive Integration of Partial Label Learning and Negative Learning for Enhanced Noisy Label Learning
Dec 15, 2023There has been significant attention devoted to the effectiveness of various domains, such as semi-supervised learning, contrastive learning, and meta-learning, in enhancing the performance of methods for noisy label learning (NLL) tasks. However, most existing methods still depend on prior assumptions regarding clean samples amidst different sources of noise (\eg, a pre-defined drop rate or a small subset of clean samples). In this paper, we propose a simple yet powerful idea called \textbf{NPN}, which revolutionizes \textbf{N}oisy label learning by integrating \textbf{P}artial label learning (PLL) and \textbf{N}egative learning (NL). Toward this goal, we initially decompose the given label space adaptively into the candidate and complementary labels, thereby establishing the conditions for PLL and NL. We propose two adaptive data-driven paradigms of label disambiguation for PLL: hard disambiguation and soft disambiguation. Furthermore, we generate reliable complementary labels using all non-candidate labels for NL to enhance model robustness through indirect supervision. To maintain label reliability during the later stage of model training, we introduce a consistency regularization term that encourages agreement between the outputs of multiple augmentations. Experiments conducted on both synthetically corrupted and real-world noisy datasets demonstrate the superiority of NPN compared to other state-of-the-art (SOTA) methods. The source code has been made available at {\color{purple}{\url{https://github.com/NUST-Machine-Intelligence-Laboratory/NPN}}}.
Hierarchical Graph Pattern Understanding for Zero-Shot VOS
Dec 15, 2023The optical flow guidance strategy is ideal for obtaining motion information of objects in the video. It is widely utilized in video segmentation tasks. However, existing optical flow-based methods have a significant dependency on optical flow, which results in poor performance when the optical flow estimation fails for a particular scene. The temporal consistency provided by the optical flow could be effectively supplemented by modeling in a structural form. This paper proposes a new hierarchical graph neural network (GNN) architecture, dubbed hierarchical graph pattern understanding (HGPU), for zero-shot video object segmentation (ZS-VOS). Inspired by the strong ability of GNNs in capturing structural relations, HGPU innovatively leverages motion cues (\ie, optical flow) to enhance the high-order representations from the neighbors of target frames. Specifically, a hierarchical graph pattern encoder with message aggregation is introduced to acquire different levels of motion and appearance features in a sequential manner. Furthermore, a decoder is designed for hierarchically parsing and understanding the transformed multi-modal contexts to achieve more accurate and robust results. HGPU achieves state-of-the-art performance on four publicly available benchmarks (DAVIS-16, YouTube-Objects, Long-Videos and DAVIS-17). Code and pre-trained model can be found at \url{https://github.com/NUST-Machine-Intelligence-Laboratory/HGPU}.
* accepted by IEEE Transactions on Image Processing