 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuafeng Liu
Unsupervised Learning of Hybrid Latent Dynamics: A Learn-to-Identify Framework
Mar 13, 2024
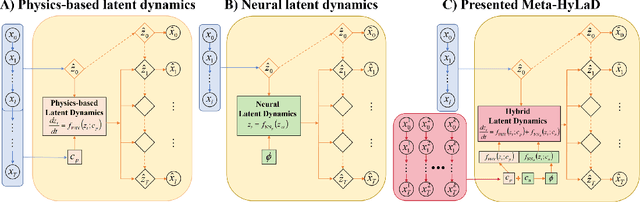
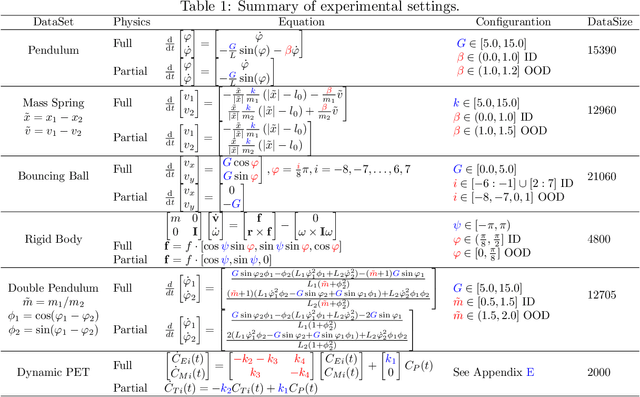
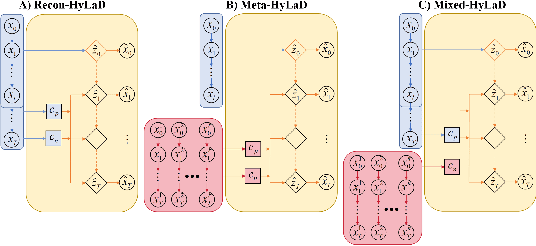

Modern applications increasingly require unsupervised learning of latent dynamics from high-dimensional time-series. This presents a significant challenge of identifiability: many abstract latent representations may reconstruct observations, yet do they guarantee an adequate identification of the governing dynamics? This paper investigates this challenge from two angles: the use of physics inductive bias specific to the data being modeled, and a learn-to-identify strategy that separates forecasting objectives from the data used for the identification. We combine these two strategies in a novel framework for unsupervised meta-learning of hybrid latent dynamics (Meta-HyLaD) with: 1) a latent dynamic function that hybridize known mathematical expressions of prior physics with neural functions describing its unknown errors, and 2) a meta-learning formulation to learn to separately identify both components of the hybrid dynamics. Through extensive experiments on five physics and one biomedical systems, we provide strong evidence for the benefits of Meta-HyLaD to integrate rich prior knowledge while identifying their gap to observed data.
Hybrid Kinetics Embedding Framework for Dynamic PET Reconstruction
Mar 12, 2024
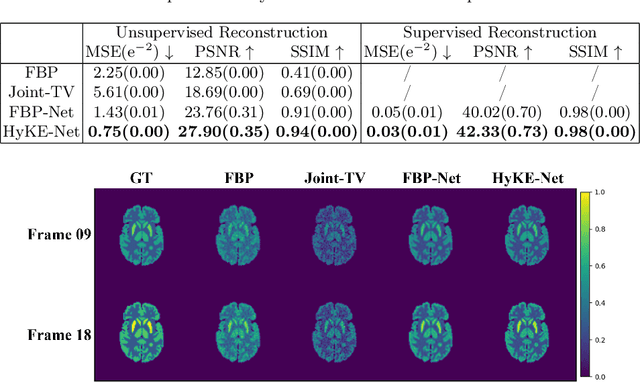
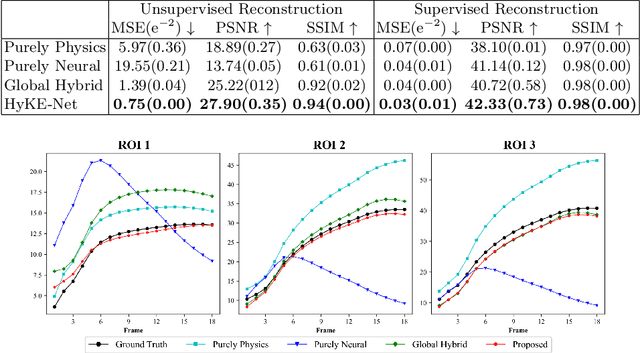

In dynamic positron emission tomography (PET) reconstruction, the importance of leveraging the temporal dependence of the data has been well appreciated. Current deep-learning solutions can be categorized in two groups in the way the temporal dynamics is modeled: data-driven approaches use spatiotemporal neural networks to learn the temporal dynamics of tracer kinetics from data, which relies heavily on data supervision; physics-based approaches leverage \textit{a priori} tracer kinetic models to focus on inferring their parameters, which relies heavily on the accuracy of the prior kinetic model. In this paper, we marry the strengths of these two approaches in a hybrid kinetics embedding (HyKE-Net) framework for dynamic PET reconstruction. We first introduce a novel \textit{hybrid} model of tracer kinetics consisting of a physics-based function augmented by a neural component to account for its gap to data-generating tracer kinetics, both identifiable from data. We then embed this hybrid model at the latent space of an encoding-decoding framework to enable both supervised and unsupervised identification of the hybrid kinetics and thereby dynamic PET reconstruction. Through both phantom and real-data experiments, we demonstrate the benefits of HyKE-Net -- especially in unsupervised reconstructions -- over existing physics-based and data-driven baselines as well as its ablated formulations where the embedded tracer kinetics are purely physics-based, purely neural, or hybrid but with a non-adaptable neural component.
VideoMAC: Video Masked Autoencoders Meet ConvNets
Feb 29, 2024Recently, the advancement of self-supervised learning techniques, like masked autoencoders (MAE), has greatly influenced visual representation learning for images and videos. Nevertheless, it is worth noting that the predominant approaches in existing masked image / video modeling rely excessively on resource-intensive vision transformers (ViTs) as the feature encoder. In this paper, we propose a new approach termed as \textbf{VideoMAC}, which combines video masked autoencoders with resource-friendly ConvNets. Specifically, VideoMAC employs symmetric masking on randomly sampled pairs of video frames. To prevent the issue of mask pattern dissipation, we utilize ConvNets which are implemented with sparse convolutional operators as encoders. Simultaneously, we present a simple yet effective masked video modeling (MVM) approach, a dual encoder architecture comprising an online encoder and an exponential moving average target encoder, aimed to facilitate inter-frame reconstruction consistency in videos. Additionally, we demonstrate that VideoMAC, empowering classical (ResNet) / modern (ConvNeXt) convolutional encoders to harness the benefits of MVM, outperforms ViT-based approaches on downstream tasks, including video object segmentation (+\textbf{5.2\%} / \textbf{6.4\%} $\mathcal{J}\&\mathcal{F}$), body part propagation (+\textbf{6.3\%} / \textbf{3.1\%} mIoU), and human pose tracking (+\textbf{10.2\%} / \textbf{11.1\%} PCK@0.1).
Learning with Imbalanced Noisy Data by Preventing Bias in Sample Selection
Feb 17, 2024Learning with noisy labels has gained increasing attention because the inevitable imperfect labels in real-world scenarios can substantially hurt the deep model performance. Recent studies tend to regard low-loss samples as clean ones and discard high-loss ones to alleviate the negative impact of noisy labels. However, real-world datasets contain not only noisy labels but also class imbalance. The imbalance issue is prone to causing failure in the loss-based sample selection since the under-learning of tail classes also leans to produce high losses. To this end, we propose a simple yet effective method to address noisy labels in imbalanced datasets. Specifically, we propose Class-Balance-based sample Selection (CBS) to prevent the tail class samples from being neglected during training. We propose Confidence-based Sample Augmentation (CSA) for the chosen clean samples to enhance their reliability in the training process. To exploit selected noisy samples, we resort to prediction history to rectify labels of noisy samples. Moreover, we introduce the Average Confidence Margin (ACM) metric to measure the quality of corrected labels by leveraging the model's evolving training dynamics, thereby ensuring that low-quality corrected noisy samples are appropriately masked out. Lastly, consistency regularization is imposed on filtered label-corrected noisy samples to boost model performance. Comprehensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method, especially in imbalanced scenarios. Comprehensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method, especially in imbalanced scenarios.
Is ChatGPT A Good Keyphrase Generator? A Preliminary Study
Mar 23, 2023
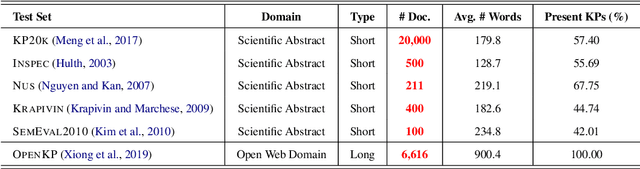


The emergence of ChatGPT has recently garnered significant attention from the computational linguistics community. To demonstrate its capabilities as a keyphrase generator, we conduct a preliminary evaluation of ChatGPT for the keyphrase generation task. We evaluate its performance in various aspects, including keyphrase generation prompts, keyphrase generation diversity, multi-domain keyphrase generation, and long document understanding. Our evaluation is based on six benchmark datasets, and we adopt the prompt suggested by OpenAI while extending it to six candidate prompts. We find that ChatGPT performs exceptionally well on all six candidate prompts, with minor performance differences observed across the datasets. Based on our findings, we conclude that ChatGPT has great potential for keyphrase generation. Moreover, we discover that ChatGPT still faces challenges when it comes to generating absent keyphrases. Meanwhile, in the final section, we also present some limitations and future expansions of this report.
DULDA: Dual-domain Unsupervised Learned Descent Algorithm for PET image reconstruction
Mar 10, 2023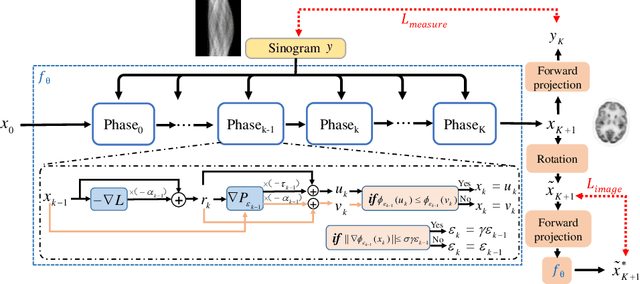
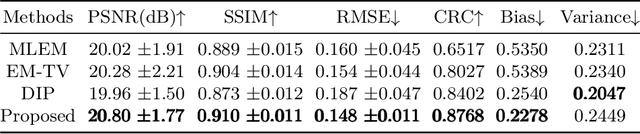


Deep learning based PET image reconstruction methods have achieved promising results recently. However, most of these methods follow a supervised learning paradigm, which rely heavily on the availability of high-quality training labels. In particular, the long scanning time required and high radiation exposure associated with PET scans make obtaining this labels impractical. In this paper, we propose a dual-domain unsupervised PET image reconstruction method based on learned decent algorithm, which reconstructs high-quality PET images from sinograms without the need for image labels. Specifically, we unroll the proximal gradient method with a learnable l2,1 norm for PET image reconstruction problem. The training is unsupervised, using measurement domain loss based on deep image prior as well as image domain loss based on rotation equivariance property. The experimental results domonstrate the superior performance of proposed method compared with maximum likelihood expectation maximazation (MLEM), total-variation regularized EM (EM-TV) and deep image prior based method (DIP).
STPDnet: Spatial-temporal convolutional primal dual network for dynamic PET image reconstruction
Mar 08, 2023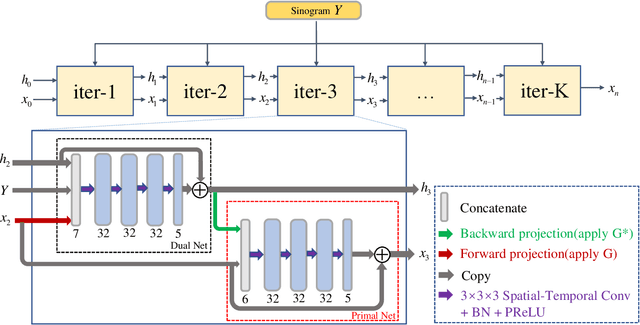
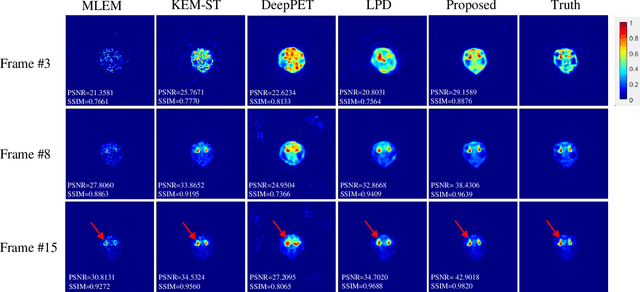
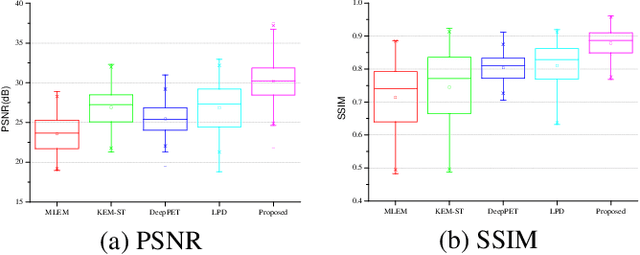
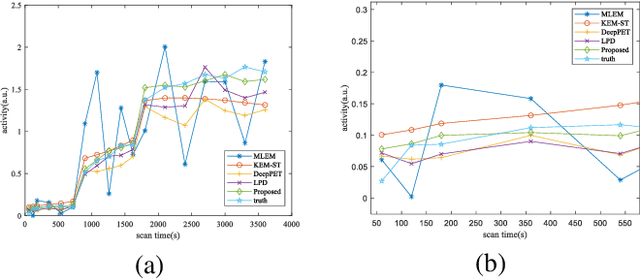
Dynamic positron emission tomography (dPET) image reconstruction is extremely challenging due to the limited counts received in individual frame. In this paper, we propose a spatial-temporal convolutional primal dual network (STPDnet) for dynamic PET image reconstruction. Both spatial and temporal correlations are encoded by 3D convolution operators. The physical projection of PET is embedded in the iterative learning process of the network, which provides the physical constraints and enhances interpretability. The experiments of real rat scan data have shown that the proposed method can achieve substantial noise reduction in both temporal and spatial domains and outperform the maximum likelihood expectation maximization (MLEM), spatial-temporal kernel method (KEM-ST), DeepPET and Learned Primal Dual (LPD).
LMPDNet: TOF-PET list-mode image reconstruction using model-based deep learning method
Feb 21, 2023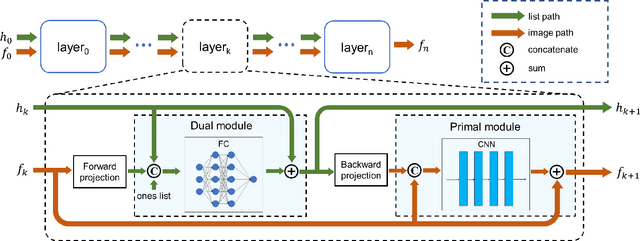
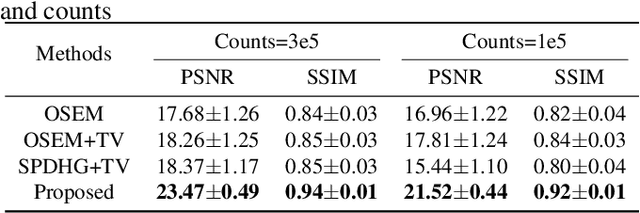
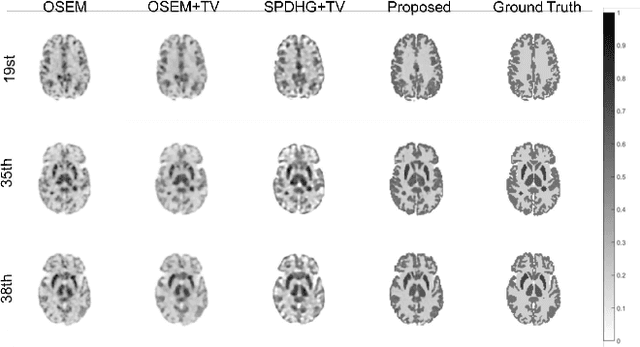
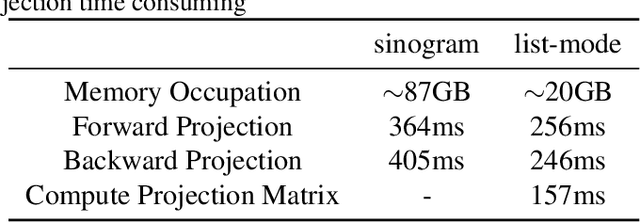
The integration of Time-of-Flight (TOF) information in the reconstruction process of Positron Emission Tomography (PET) yields improved image properties. However, implementing the cutting-edge model-based deep learning methods for TOF-PET reconstruction is challenging due to the substantial memory requirements. In this study, we present a novel model-based deep learning approach, LMPDNet, for TOF-PET reconstruction from list-mode data. We address the issue of real-time parallel computation of the projection matrix for list-mode data, and propose an iterative model-based module that utilizes a dedicated network model for list-mode data. Our experimental results indicate that the proposed LMPDNet outperforms traditional iteration-based TOF-PET list-mode reconstruction algorithms. Additionally, we compare the spatial and temporal consumption of list-mode data and sinogram data in model-based deep learning methods, demonstrating the superiority of list-mode data in model-based TOF-PET reconstruction.
FECANet: Boosting Few-Shot Semantic Segmentation with Feature-Enhanced Context-Aware Network
Jan 19, 2023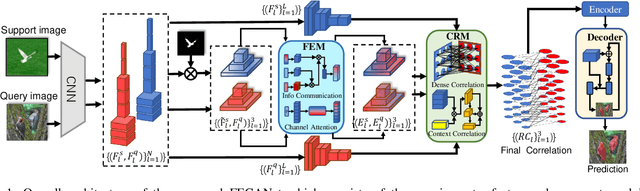
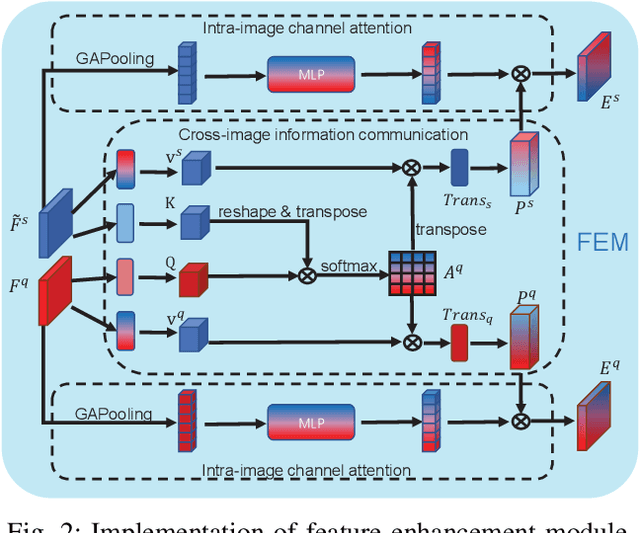
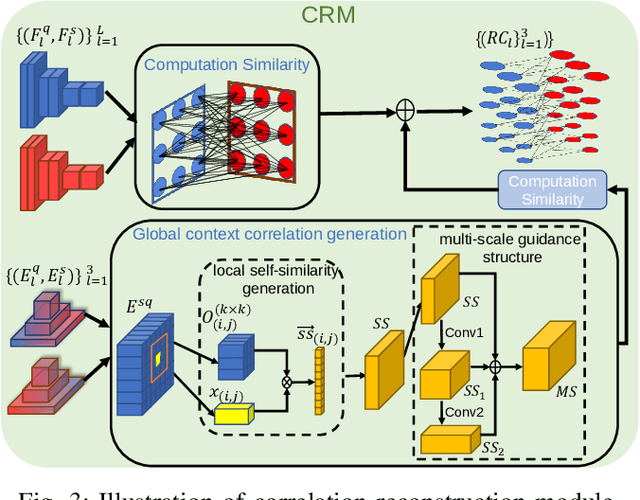

Few-shot semantic segmentation is the task of learning to locate each pixel of the novel class in the query image with only a few annotated support images. The current correlation-based methods construct pair-wise feature correlations to establish the many-to-many matching because the typical prototype-based approaches cannot learn fine-grained correspondence relations. However, the existing methods still suffer from the noise contained in naive correlations and the lack of context semantic information in correlations. To alleviate these problems mentioned above, we propose a Feature-Enhanced Context-Aware Network (FECANet). Specifically, a feature enhancement module is proposed to suppress the matching noise caused by inter-class local similarity and enhance the intra-class relevance in the naive correlation. In addition, we propose a novel correlation reconstruction module that encodes extra correspondence relations between foreground and background and multi-scale context semantic features, significantly boosting the encoder to capture a reliable matching pattern. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets demonstrate that our proposed FECANet leads to remarkable improvement compared to previous state-of-the-arts, demonstrating its effectiveness.
HessianFR: An Efficient Hessian-based Follow-the-Ridge Algorithm for Minimax Optimization
May 23, 2022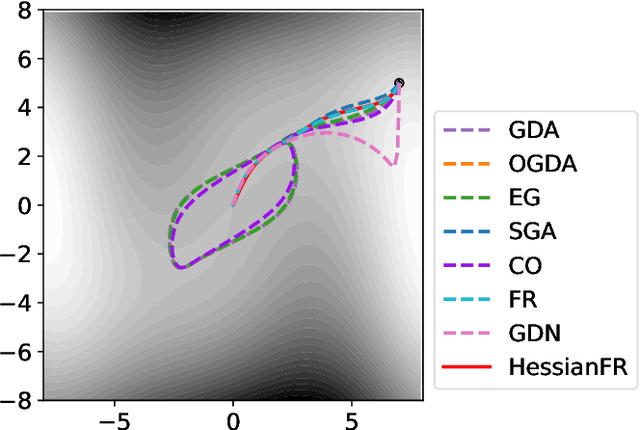
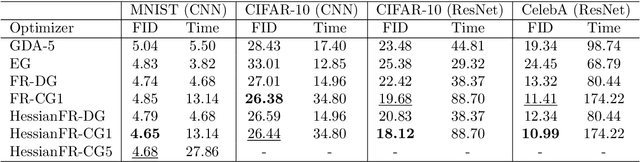
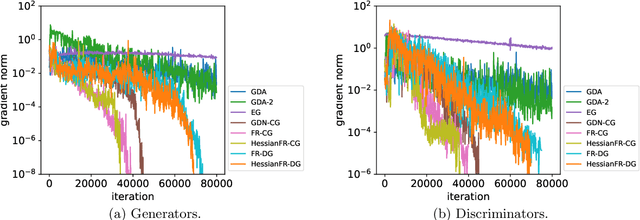
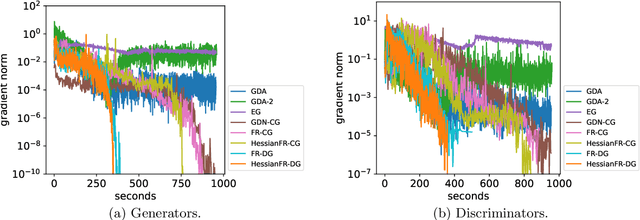
Wide applications of differentiable two-player sequential games (e.g., image generation by GANs) have raised much interest and attention of researchers to study efficient and fast algorithms. Most of the existing algorithms are developed based on nice properties of simultaneous games, i.e., convex-concave payoff functions, but are not applicable in solving sequential games with different settings. Some conventional gradient descent ascent algorithms theoretically and numerically fail to find the local Nash equilibrium of the simultaneous game or the local minimax (i.e., local Stackelberg equilibrium) of the sequential game. In this paper, we propose the HessianFR, an efficient Hessian-based Follow-the-Ridge algorithm with theoretical guarantees. Furthermore, the convergence of the stochastic algorithm and the approximation of Hessian inverse are exploited to improve algorithm efficiency. A series of experiments of training generative adversarial networks (GANs) have been conducted on both synthetic and real-world large-scale image datasets (e.g. MNIST, CIFAR-10 and CelebA). The experimental results demonstrate that the proposed HessianFR outperforms baselines in terms of convergence and image generation quality.