 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaiyun Jiang
Sequence can Secretly Tell You What to Discard
Apr 24, 2024
Large Language Models (LLMs), despite their impressive performance on a wide range of tasks, require significant GPU memory and consume substantial computational resources. In addition to model weights, the memory occupied by KV cache increases linearly with sequence length, becoming a main bottleneck for inference. In this paper, we introduce a novel approach for optimizing the KV cache which significantly reduces its memory footprint. Through a comprehensive investigation, we find that on LLaMA2 series models, (i) the similarity between adjacent tokens' query vectors is remarkably high, and (ii) current query's attention calculation can rely solely on the attention information of a small portion of the preceding queries. Based on these observations, we propose CORM, a KV cache eviction policy that dynamically retains important key-value pairs for inference without finetuning the model. We validate that CORM reduces the inference memory usage of KV cache by up to 70% without noticeable performance degradation across six tasks in LongBench.
MIKE: A New Benchmark for Fine-grained Multimodal Entity Knowledge Editing
Feb 18, 2024Multimodal knowledge editing represents a critical advancement in enhancing the capabilities of Multimodal Large Language Models (MLLMs). Despite its potential, current benchmarks predominantly focus on coarse-grained knowledge, leaving the intricacies of fine-grained (FG) multimodal entity knowledge largely unexplored. This gap presents a notable challenge, as FG entity recognition is pivotal for the practical deployment and effectiveness of MLLMs in diverse real-world scenarios. To bridge this gap, we introduce MIKE, a comprehensive benchmark and dataset specifically designed for the FG multimodal entity knowledge editing. MIKE encompasses a suite of tasks tailored to assess different perspectives, including Vanilla Name Answering, Entity-Level Caption, and Complex-Scenario Recognition. In addition, a new form of knowledge editing, Multi-step Editing, is introduced to evaluate the editing efficiency. Through our extensive evaluations, we demonstrate that the current state-of-the-art methods face significant challenges in tackling our proposed benchmark, underscoring the complexity of FG knowledge editing in MLLMs. Our findings spotlight the urgent need for novel approaches in this domain, setting a clear agenda for future research and development efforts within the community.
Challenge LLMs to Reason About Reasoning: A Benchmark to Unveil Cognitive Depth in LLMs
Dec 28, 2023
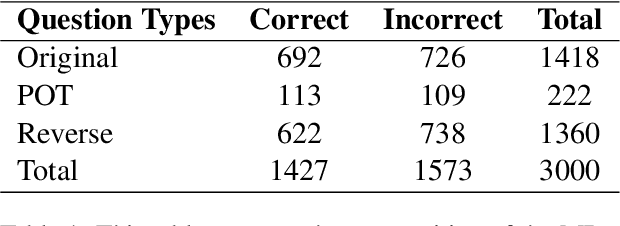
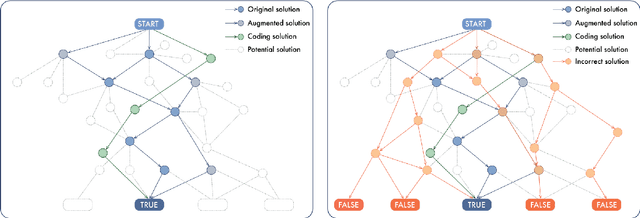
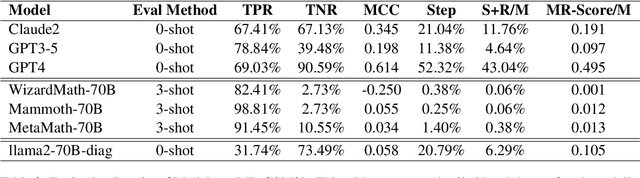
In this work, we introduce a novel evaluation paradigm for Large Language Models, one that challenges them to engage in meta-reasoning. This approach addresses critical shortcomings in existing math problem-solving benchmarks, traditionally used to evaluate the cognitive capabilities of agents. Our paradigm shifts the focus from result-oriented assessments, which often overlook the reasoning process, to a more holistic evaluation that effectively differentiates the cognitive capabilities among models. For example, in our benchmark, GPT-4 demonstrates a performance ten times more accurate than GPT3-5. The significance of this new paradigm lies in its ability to reveal potential cognitive deficiencies in LLMs that current benchmarks, such as GSM8K, fail to uncover due to their saturation and lack of effective differentiation among varying reasoning abilities. Our comprehensive analysis includes several state-of-the-art math models from both open-source and closed-source communities, uncovering fundamental deficiencies in their training and evaluation approaches. This paper not only advocates for a paradigm shift in the assessment of LLMs but also contributes to the ongoing discourse on the trajectory towards Artificial General Intelligence (AGI). By promoting the adoption of meta-reasoning evaluation methods similar to ours, we aim to facilitate a more accurate assessment of the true cognitive abilities of LLMs.
When Graph Data Meets Multimodal: A New Paradigm for Graph Understanding and Reasoning
Dec 16, 2023Graph data is ubiquitous in the physical world, and it has always been a challenge to efficiently model graph structures using a unified paradigm for the understanding and reasoning on various graphs. Moreover, in the era of large language models, integrating complex graph information into text sequences has become exceptionally difficult, which hinders the ability to interact with graph data through natural language instructions.The paper presents a new paradigm for understanding and reasoning about graph data by integrating image encoding and multimodal technologies. This approach enables the comprehension of graph data through an instruction-response format, utilizing GPT-4V's advanced capabilities. The study evaluates this paradigm on various graph types, highlighting the model's strengths and weaknesses, particularly in Chinese OCR performance and complex reasoning tasks. The findings suggest new direction for enhancing graph data processing and natural language interaction.
StrategyLLM: Large Language Models as Strategy Generators, Executors, Optimizers, and Evaluators for Problem Solving
Nov 15, 2023Most existing chain-of-thought (CoT) prompting methods suffer from the issues of generalizability and consistency, as they often rely on instance-specific solutions that may not be applicable to other cases and lack task-level consistency in their reasoning steps. To address these limitations, we propose a comprehensive framework, StrategyLLM, harnessing the capabilities of LLMs to tackle various tasks. The framework improves generalizability by formulating general problem-solving strategies and enhances consistency by producing consistent solutions using these strategies. StrategyLLM employs four LLM-based agents: strategy generator, executor, optimizer, and evaluator, working together to generate, evaluate, and select promising strategies for a given task automatically. The experimental results demonstrate that StrategyLLM outperforms the competitive baseline CoT-SC that requires human-annotated solutions on 13 datasets across 4 challenging tasks without human involvement, including math reasoning (39.2% $\rightarrow$ 43.3%), commonsense reasoning (70.3% $\rightarrow$ 72.5%), algorithmic reasoning (51.7% $\rightarrow$ 62.0%), and symbolic reasoning (30.0% $\rightarrow$ 79.2%).
Hint-enhanced In-Context Learning wakes Large Language Models up for knowledge-intensive tasks
Nov 03, 2023In-context learning (ICL) ability has emerged with the increasing scale of large language models (LLMs), enabling them to learn input-label mappings from demonstrations and perform well on downstream tasks. However, under the standard ICL setting, LLMs may sometimes neglect query-related information in demonstrations, leading to incorrect predictions. To address this limitation, we propose a new paradigm called Hint-enhanced In-Context Learning (HICL) to explore the power of ICL in open-domain question answering, an important form in knowledge-intensive tasks. HICL leverages LLMs' reasoning ability to extract query-related knowledge from demonstrations, then concatenates the knowledge to prompt LLMs in a more explicit way. Furthermore, we track the source of this knowledge to identify specific examples, and introduce a Hint-related Example Retriever (HER) to select informative examples for enhanced demonstrations. We evaluate HICL with HER on 3 open-domain QA benchmarks, and observe average performance gains of 2.89 EM score and 2.52 F1 score on gpt-3.5-turbo, 7.62 EM score and 7.27 F1 score on LLaMA-2-Chat-7B compared with standard setting.
A Benchmark for Text Expansion: Datasets, Metrics, and Baselines
Sep 17, 2023



This work presents a new task of Text Expansion (TE), which aims to insert fine-grained modifiers into proper locations of the plain text to concretize or vivify human writings. Different from existing insertion-based writing assistance tasks, TE requires the model to be more flexible in both locating and generation, and also more cautious in keeping basic semantics. We leverage four complementary approaches to construct a dataset with 12 million automatically generated instances and 2K human-annotated references for both English and Chinese. To facilitate automatic evaluation, we design various metrics from multiple perspectives. In particular, we propose Info-Gain to effectively measure the informativeness of expansions, which is an important quality dimension in TE. On top of a pre-trained text-infilling model, we build both pipelined and joint Locate&Infill models, which demonstrate the superiority over the Text2Text baselines, especially in expansion informativeness. Experiments verify the feasibility of the TE task and point out potential directions for future research toward better automatic text expansion.
Towards Visual Taxonomy Expansion
Sep 12, 2023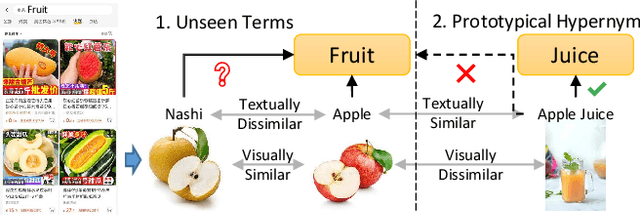
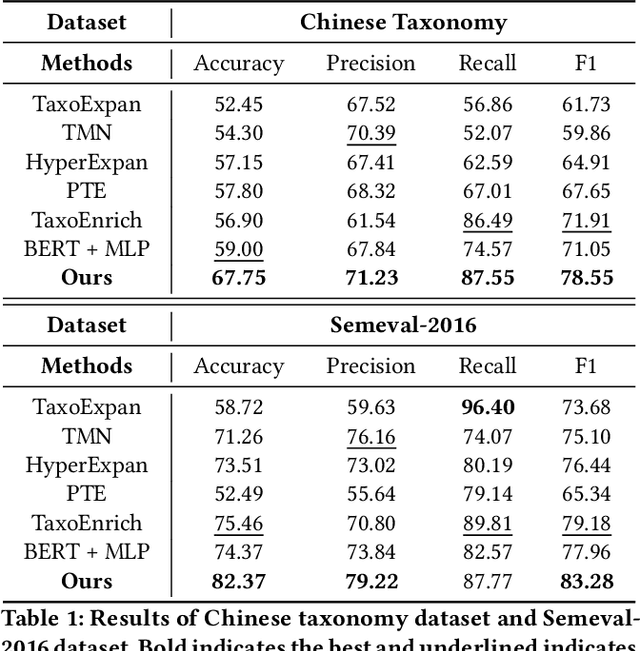
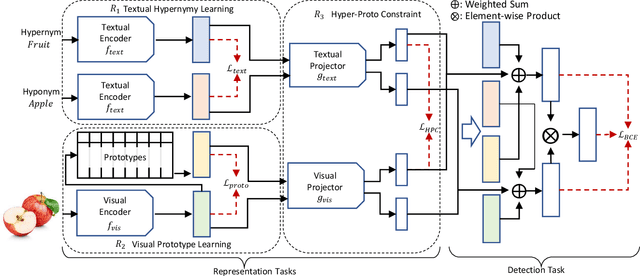
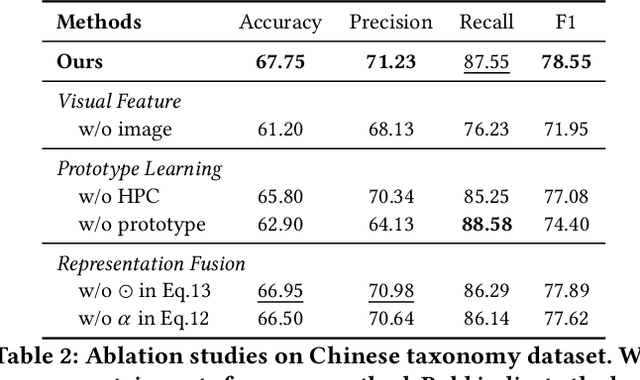
Taxonomy expansion task is essential in organizing the ever-increasing volume of new concepts into existing taxonomies. Most existing methods focus exclusively on using textual semantics, leading to an inability to generalize to unseen terms and the "Prototypical Hypernym Problem." In this paper, we propose Visual Taxonomy Expansion (VTE), introducing visual features into the taxonomy expansion task. We propose a textual hypernymy learning task and a visual prototype learning task to cluster textual and visual semantics. In addition to the tasks on respective modalities, we introduce a hyper-proto constraint that integrates textual and visual semantics to produce fine-grained visual semantics. Our method is evaluated on two datasets, where we obtain compelling results. Specifically, on the Chinese taxonomy dataset, our method significantly improves accuracy by 8.75 %. Additionally, our approach performs better than ChatGPT on the Chinese taxonomy dataset.
TeGit: Generating High-Quality Instruction-Tuning Data with Text-Grounded Task Design
Sep 11, 2023

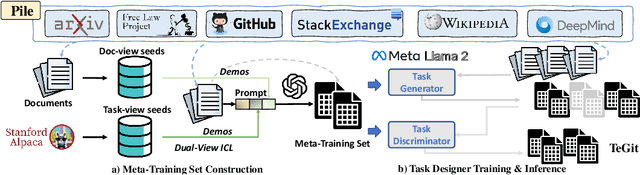
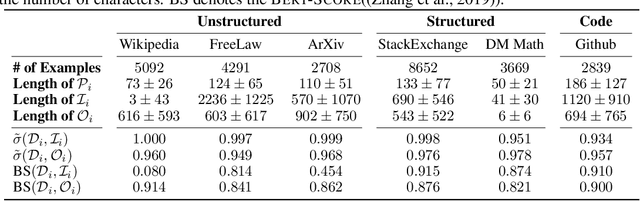
High-quality instruction-tuning data is critical to improving LLM capabilities. Existing data collection methods are limited by unrealistic manual labeling costs or by the hallucination of relying solely on LLM generation. To address the problems, this paper presents a scalable method to automatically collect high-quality instructional adaptation data by training language models to automatically design tasks based on human-written texts. Intuitively, human-written text helps to help the model attenuate illusions during the generation of tasks. Unlike instruction back-translation-based methods that directly take the given text as a response, we require the model to generate the \textit{instruction}, \textit{input}, and \textit{output} simultaneously to filter the noise. The results of the automated and manual evaluation experiments demonstrate the quality of our dataset.
Disco-Bench: A Discourse-Aware Evaluation Benchmark for Language Modelling
Jul 22, 2023



Modeling discourse -- the linguistic phenomena that go beyond individual sentences, is a fundamental yet challenging aspect of natural language processing (NLP). However, existing evaluation benchmarks primarily focus on the evaluation of inter-sentence properties and overlook critical discourse phenomena that cross sentences. To bridge the gap, we propose Disco-Bench, a benchmark that can evaluate intra-sentence discourse properties across a diverse set of NLP tasks, covering understanding, translation, and generation. Disco-Bench consists of 9 document-level testsets in the literature domain, which contain rich discourse phenomena (e.g. cohesion and coherence) in Chinese and/or English. For linguistic analysis, we also design a diagnostic test suite that can examine whether the target models learn discourse knowledge. We totally evaluate 20 general-, in-domain and commercial models based on Transformer, advanced pretraining architectures and large language models (LLMs). Our results show (1) the challenge and necessity of our evaluation benchmark; (2) fine-grained pretraining based on literary document-level training data consistently improves the modeling of discourse information. We will release the datasets, pretrained models, and leaderboard, which we hope can significantly facilitate research in this field: https://github.com/longyuewangdcu/Disco-Bench.