 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYen-Chun Chen
iFusion: Inverting Diffusion for Pose-Free Reconstruction from Sparse Views
Dec 28, 2023
We present iFusion, a novel 3D object reconstruction framework that requires only two views with unknown camera poses. While single-view reconstruction yields visually appealing results, it can deviate significantly from the actual object, especially on unseen sides. Additional views improve reconstruction fidelity but necessitate known camera poses. However, assuming the availability of pose may be unrealistic, and existing pose estimators fail in sparse view scenarios. To address this, we harness a pre-trained novel view synthesis diffusion model, which embeds implicit knowledge about the geometry and appearance of diverse objects. Our strategy unfolds in three steps: (1) We invert the diffusion model for camera pose estimation instead of synthesizing novel views. (2) The diffusion model is fine-tuned using provided views and estimated poses, turned into a novel view synthesizer tailored for the target object. (3) Leveraging registered views and the fine-tuned diffusion model, we reconstruct the 3D object. Experiments demonstrate strong performance in both pose estimation and novel view synthesis. Moreover, iFusion seamlessly integrates with various reconstruction methods and enhances them.
LACMA: Language-Aligning Contrastive Learning with Meta-Actions for Embodied Instruction Following
Oct 18, 2023End-to-end Transformers have demonstrated an impressive success rate for Embodied Instruction Following when the environment has been seen in training. However, they tend to struggle when deployed in an unseen environment. This lack of generalizability is due to the agent's insensitivity to subtle changes in natural language instructions. To mitigate this issue, we propose explicitly aligning the agent's hidden states with the instructions via contrastive learning. Nevertheless, the semantic gap between high-level language instructions and the agent's low-level action space remains an obstacle. Therefore, we further introduce a novel concept of meta-actions to bridge the gap. Meta-actions are ubiquitous action patterns that can be parsed from the original action sequence. These patterns represent higher-level semantics that are intuitively aligned closer to the instructions. When meta-actions are applied as additional training signals, the agent generalizes better to unseen environments. Compared to a strong multi-modal Transformer baseline, we achieve a significant 4.5% absolute gain in success rate in unseen environments of ALFRED Embodied Instruction Following. Additional analysis shows that the contrastive objective and meta-actions are complementary in achieving the best results, and the resulting agent better aligns its states with corresponding instructions, making it more suitable for real-world embodied agents. The code is available at: https://github.com/joeyy5588/LACMA.
Uni-ControlNet: All-in-One Control to Text-to-Image Diffusion Models
May 31, 2023

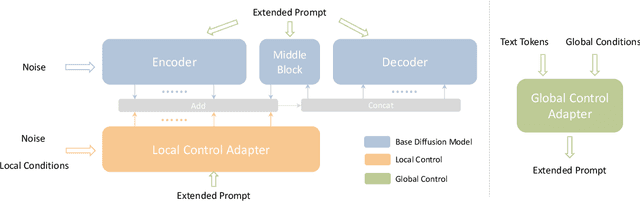
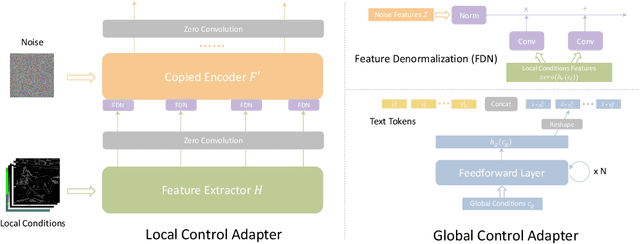
Text-to-Image diffusion models have made tremendous progress over the past two years, enabling the generation of highly realistic images based on open-domain text descriptions. However, despite their success, text descriptions often struggle to adequately convey detailed controls, even when composed of long and complex texts. Moreover, recent studies have also shown that these models face challenges in understanding such complex texts and generating the corresponding images. Therefore, there is a growing need to enable more control modes beyond text description. In this paper, we introduce Uni-ControlNet, a novel approach that allows for the simultaneous utilization of different local controls (e.g., edge maps, depth map, segmentation masks) and global controls (e.g., CLIP image embeddings) in a flexible and composable manner within one model. Unlike existing methods, Uni-ControlNet only requires the fine-tuning of two additional adapters upon frozen pre-trained text-to-image diffusion models, eliminating the huge cost of training from scratch. Moreover, thanks to some dedicated adapter designs, Uni-ControlNet only necessitates a constant number (i.e., 2) of adapters, regardless of the number of local or global controls used. This not only reduces the fine-tuning costs and model size, making it more suitable for real-world deployment, but also facilitate composability of different conditions. Through both quantitative and qualitative comparisons, Uni-ControlNet demonstrates its superiority over existing methods in terms of controllability, generation quality and composability. Code is available at \url{https://github.com/ShihaoZhaoZSH/Uni-ControlNet}.
Modality-Independent Teachers Meet Weakly-Supervised Audio-Visual Event Parser
May 27, 2023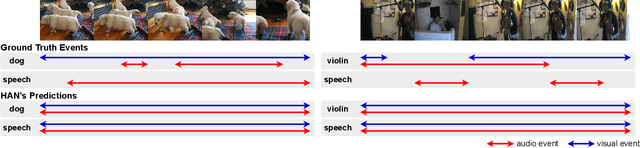
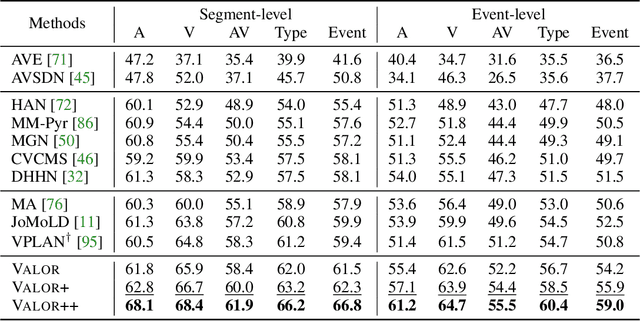
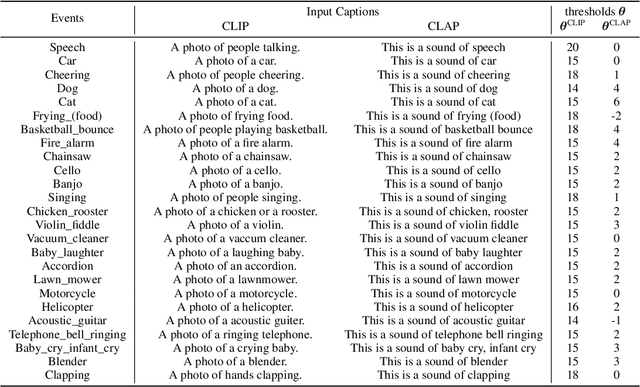
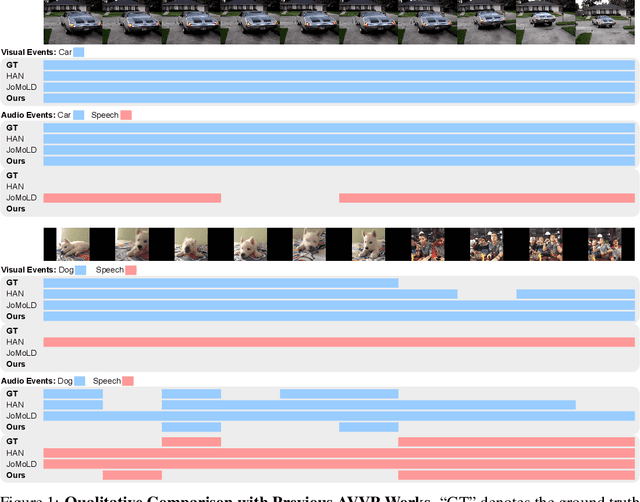
Audio-visual learning has been a major pillar of multi-modal machine learning, where the community mostly focused on its modality-aligned setting, i.e., the audio and visual modality are both assumed to signal the prediction target. With the Look, Listen, and Parse dataset (LLP), we investigate the under-explored unaligned setting, where the goal is to recognize audio and visual events in a video with only weak labels observed. Such weak video-level labels only tell what events happen without knowing the modality they are perceived (audio, visual, or both). To enhance learning in this challenging setting, we incorporate large-scale contrastively pre-trained models as the modality teachers. A simple, effective, and generic method, termed Visual-Audio Label Elaboration (VALOR), is innovated to harvest modality labels for the training events. Empirical studies show that the harvested labels significantly improve an attentional baseline by 8.0 in average F-score (Type@AV). Surprisingly, we found that modality-independent teachers outperform their modality-fused counterparts since they are noise-proof from the other potentially unaligned modality. Moreover, our best model achieves the new state-of-the-art on all metrics of LLP by a substantial margin (+5.4 F-score for Type@AV). VALOR is further generalized to Audio-Visual Event Localization and achieves the new state-of-the-art as well. Code is available at: https://github.com/Franklin905/VALOR.
Frido: Feature Pyramid Diffusion for Complex Scene Image Synthesis
Aug 29, 2022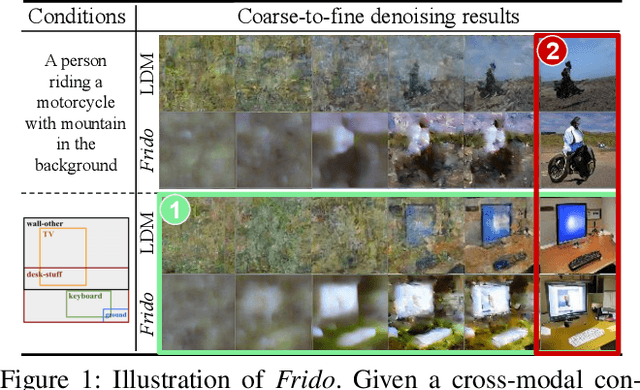
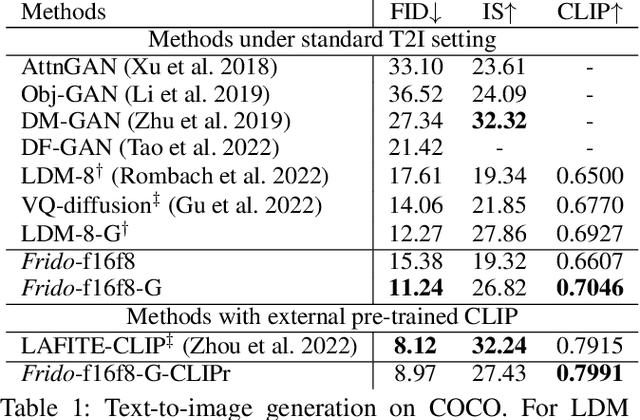
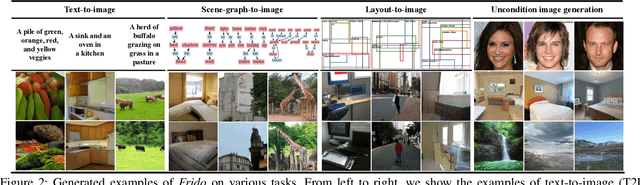
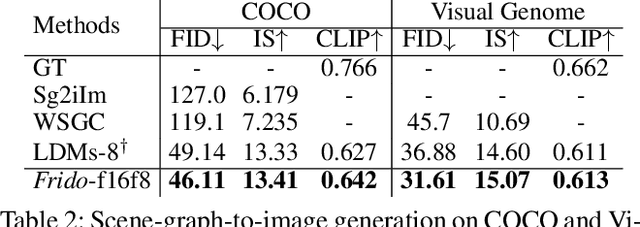
Diffusion models (DMs) have shown great potential for high-quality image synthesis. However, when it comes to producing images with complex scenes, how to properly describe both image global structures and object details remains a challenging task. In this paper, we present Frido, a Feature Pyramid Diffusion model performing a multi-scale coarse-to-fine denoising process for image synthesis. Our model decomposes an input image into scale-dependent vector quantized features, followed by a coarse-to-fine gating for producing image output. During the above multi-scale representation learning stage, additional input conditions like text, scene graph, or image layout can be further exploited. Thus, Frido can be also applied for conditional or cross-modality image synthesis. We conduct extensive experiments over various unconditioned and conditional image generation tasks, ranging from text-to-image synthesis, layout-to-image, scene-graph-to-image, to label-to-image. More specifically, we achieved state-of-the-art FID scores on five benchmarks, namely layout-to-image on COCO and OpenImages, scene-graph-to-image on COCO and Visual Genome, and label-to-image on COCO. Code is available at https://github.com/davidhalladay/Frido.
GLIPv2: Unifying Localization and Vision-Language Understanding
Jun 12, 2022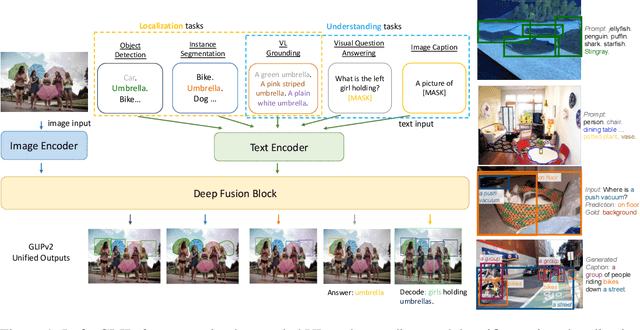
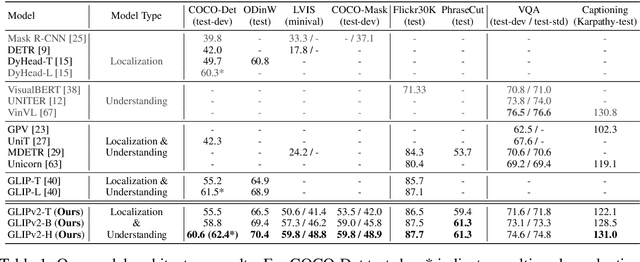
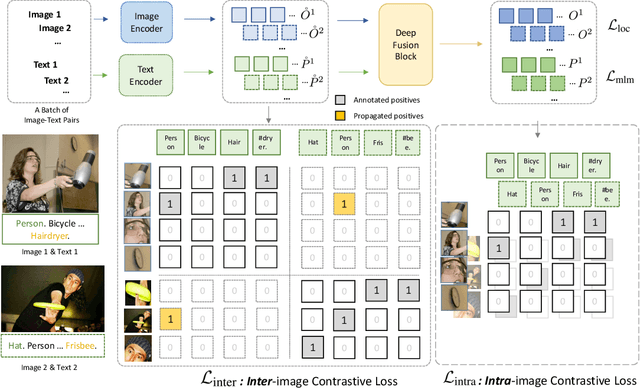
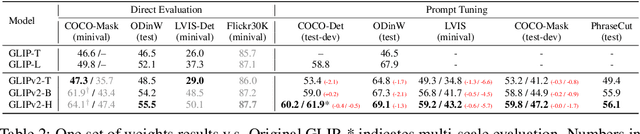
We present GLIPv2, a grounded VL understanding model, that serves both localization tasks (e.g., object detection, instance segmentation) and Vision-Language (VL) understanding tasks (e.g., VQA, image captioning). GLIPv2 elegantly unifies localization pre-training and Vision-Language Pre-training (VLP) with three pre-training tasks: phrase grounding as a VL reformulation of the detection task, region-word contrastive learning as a novel region-word level contrastive learning task, and the masked language modeling. This unification not only simplifies the previous multi-stage VLP procedure but also achieves mutual benefits between localization and understanding tasks. Experimental results show that a single GLIPv2 model (all model weights are shared) achieves near SoTA performance on various localization and understanding tasks. The model also shows (1) strong zero-shot and few-shot adaption performance on open-vocabulary object detection tasks and (2) superior grounding capability on VL understanding tasks. Code will be released at https://github.com/microsoft/GLIP.
Multimodal Adaptive Distillation for Leveraging Unimodal Encoders for Vision-Language Tasks
Apr 28, 2022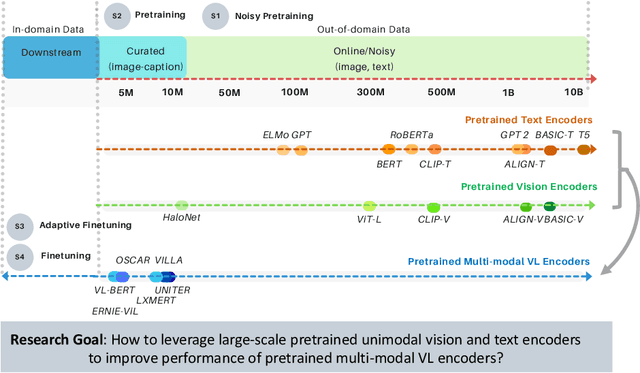
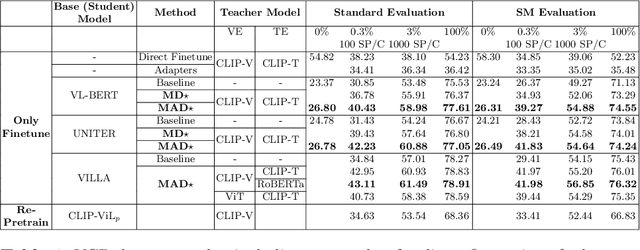
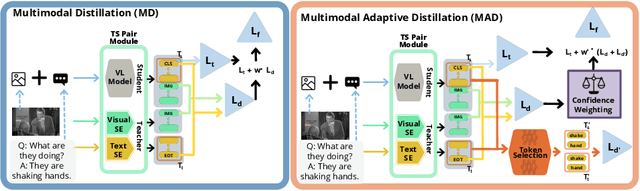
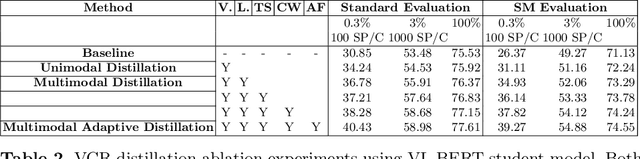
Cross-modal encoders for vision-language (VL) tasks are often pretrained with carefully curated vision-language datasets. While these datasets reach an order of 10 million samples, the labor cost is prohibitive to scale further. Conversely, unimodal encoders are pretrained with simpler annotations that are less cost-prohibitive, achieving scales of hundreds of millions to billions. As a result, unimodal encoders have achieved state-of-art (SOTA) on many downstream tasks. However, challenges remain when applying to VL tasks. The pretraining data is not optimal for cross-modal architectures and requires heavy computational resources. In addition, unimodal architectures lack cross-modal interactions that have demonstrated significant benefits for VL tasks. Therefore, how to best leverage pretrained unimodal encoders for VL tasks is still an area of active research. In this work, we propose a method to leverage unimodal vision and text encoders for VL tasks that augment existing VL approaches while conserving computational complexity. Specifically, we propose Multimodal Adaptive Distillation (MAD), which adaptively distills useful knowledge from pretrained encoders to cross-modal VL encoders. Second, to better capture nuanced impacts on VL task performance, we introduce an evaluation protocol that includes Visual Commonsense Reasoning (VCR), Visual Entailment (SNLI-VE), and Visual Question Answering (VQA), across a variety of data constraints and conditions of domain shift. Experiments demonstrate that MAD leads to consistent gains in the low-shot, domain-shifted, and fully-supervised conditions on VCR, SNLI-VE, and VQA, achieving SOTA performance on VCR compared to other single models pretrained with image-text data. Finally, MAD outperforms concurrent works utilizing pretrained vision encoder from CLIP. Code will be made available.
CLIP-TD: CLIP Targeted Distillation for Vision-Language Tasks
Jan 15, 2022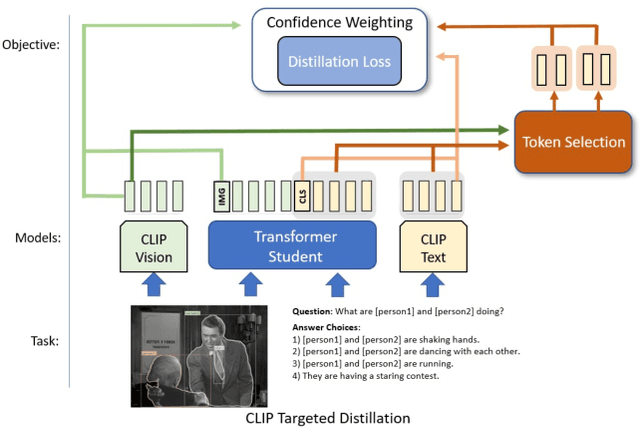
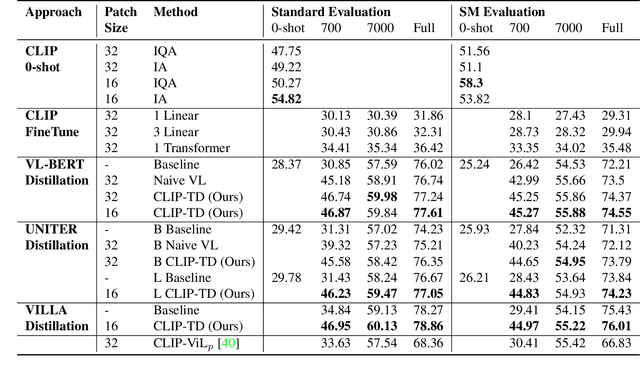
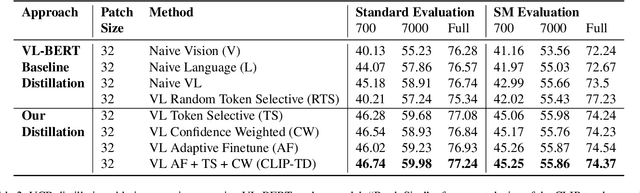

Contrastive language-image pretraining (CLIP) links vision and language modalities into a unified embedding space, yielding the tremendous potential for vision-language (VL) tasks. While early concurrent works have begun to study this potential on a subset of tasks, important questions remain: 1) What is the benefit of CLIP on unstudied VL tasks? 2) Does CLIP provide benefit in low-shot or domain-shifted scenarios? 3) Can CLIP improve existing approaches without impacting inference or pretraining complexity? In this work, we seek to answer these questions through two key contributions. First, we introduce an evaluation protocol that includes Visual Commonsense Reasoning (VCR), Visual Entailment (SNLI-VE), and Visual Question Answering (VQA), across a variety of data availability constraints and conditions of domain shift. Second, we propose an approach, named CLIP Targeted Distillation (CLIP-TD), to intelligently distill knowledge from CLIP into existing architectures using a dynamically weighted objective applied to adaptively selected tokens per instance. Experiments demonstrate that our proposed CLIP-TD leads to exceptional gains in the low-shot (up to 51.9%) and domain-shifted (up to 71.3%) conditions of VCR, while simultaneously improving performance under standard fully-supervised conditions (up to 2%), achieving state-of-art performance on VCR compared to other single models that are pretrained with image-text data only. On SNLI-VE, CLIP-TD produces significant gains in low-shot conditions (up to 6.6%) as well as fully supervised (up to 3%). On VQA, CLIP-TD provides improvement in low-shot (up to 9%), and in fully-supervised (up to 1.3%). Finally, CLIP-TD outperforms concurrent works utilizing CLIP for finetuning, as well as baseline naive distillation approaches. Code will be made available.
VALUE: A Multi-Task Benchmark for Video-and-Language Understanding Evaluation
Jun 08, 2021

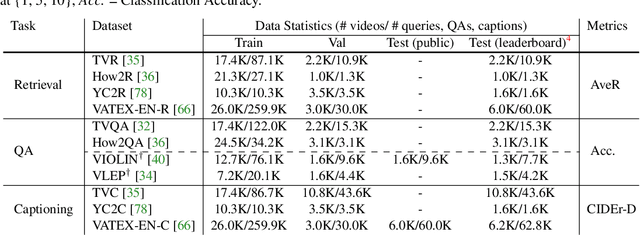
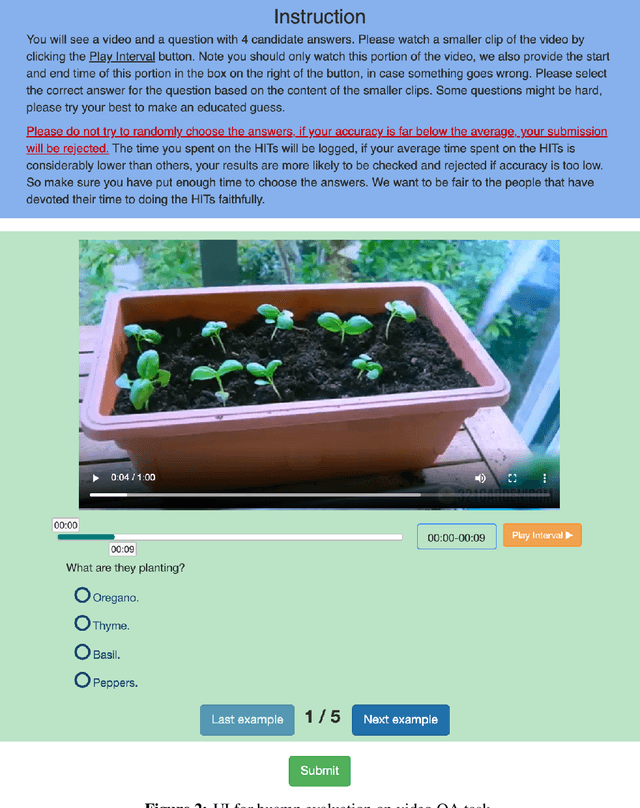
Most existing video-and-language (VidL) research focuses on a single dataset, or multiple datasets of a single task. In reality, a truly useful VidL system is expected to be easily generalizable to diverse tasks, domains, and datasets. To facilitate the evaluation of such systems, we introduce Video-And-Language Understanding Evaluation (VALUE) benchmark, an assemblage of 11 VidL datasets over 3 popular tasks: (i) text-to-video retrieval; (ii) video question answering; and (iii) video captioning. VALUE benchmark aims to cover a broad range of video genres, video lengths, data volumes, and task difficulty levels. Rather than focusing on single-channel videos with visual information only, VALUE promotes models that leverage information from both video frames and their associated subtitles, as well as models that share knowledge across multiple tasks. We evaluate various baseline methods with and without large-scale VidL pre-training, and systematically investigate the impact of video input channels, fusion methods, and different video representations. We also study the transferability between tasks, and conduct multi-task learning under different settings. The significant gap between our best model and human performance calls for future study for advanced VidL models. VALUE is available at https://value-leaderboard.github.io/.