 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYimeng Zhu
On decoder-only architecture for speech-to-text and large language model integration
Jul 14, 2023
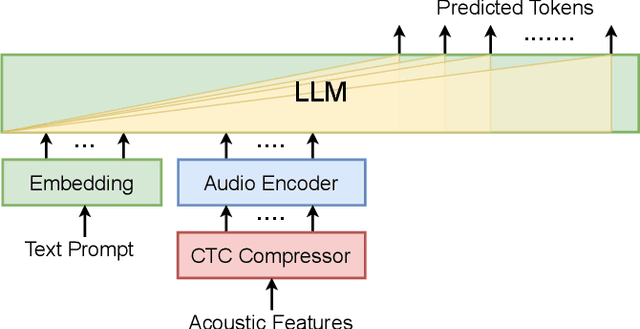
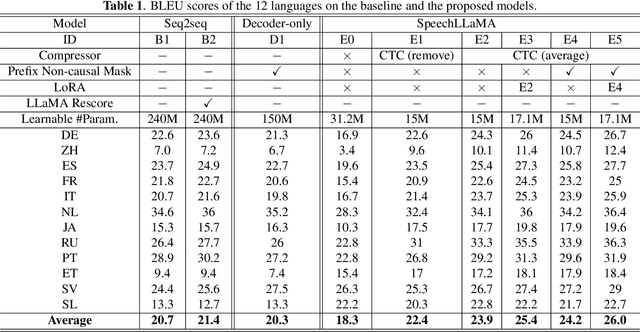
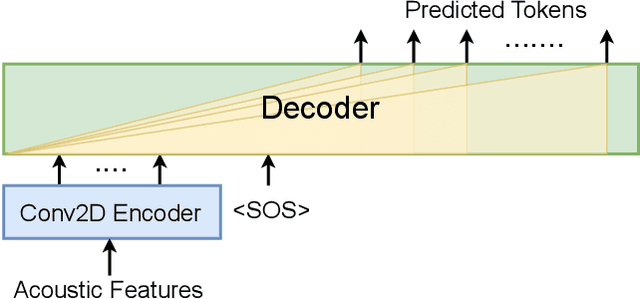
Large language models (LLMs) have achieved remarkable success in the field of natural language processing, enabling better human-computer interaction using natural language. However, the seamless integration of speech signals into LLMs has not been explored well. The "decoder-only" architecture has also not been well studied for speech processing tasks. In this research, we introduce Speech-LLaMA, a novel approach that effectively incorporates acoustic information into text-based large language models. Our method leverages Connectionist Temporal Classification and a simple audio encoder to map the compressed acoustic features to the continuous semantic space of the LLM. In addition, we further probe the decoder-only architecture for speech-to-text tasks by training a smaller scale randomly initialized speech-LLaMA model from speech-text paired data alone. We conduct experiments on multilingual speech-to-text translation tasks and demonstrate a significant improvement over strong baselines, highlighting the potential advantages of decoder-only models for speech-to-text conversion.
Building High-accuracy Multilingual ASR with Gated Language Experts and Curriculum Training
Mar 01, 2023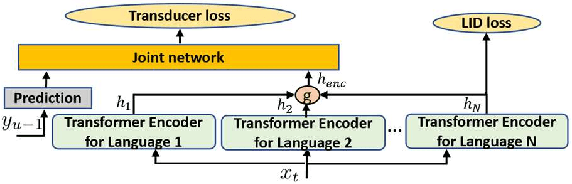
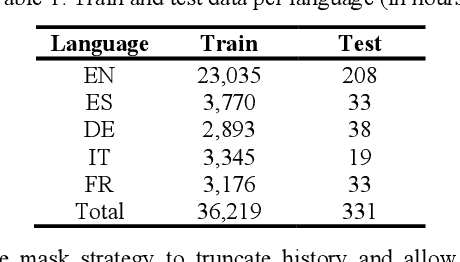
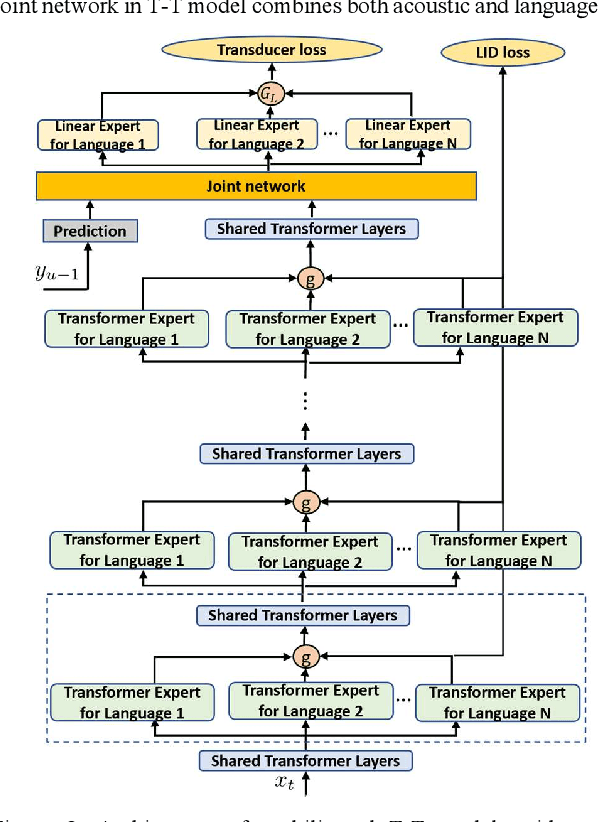
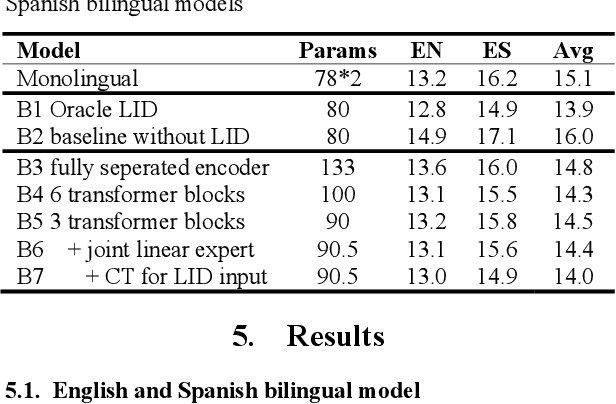
We propose gated language experts to improve multilingual transformer transducer models without any language identification (LID) input from users during inference. We define gating mechanism and LID loss to let transformer encoders learn language-dependent information, construct the multilingual transformer block with gated transformer experts and shared transformer layers for compact models, and apply linear experts on joint network output to better regularize speech acoustic and token label joint information. Furthermore, a curriculum training scheme is proposed to let LID guide the gated language experts for better serving their corresponding languages. Evaluated on the English and Spanish bilingual task, our methods achieve average 12.5% and 7.3% relative word error reductions over the baseline bilingual model and monolingual models, respectively, obtaining similar results to the upper bound model trained and inferred with oracle LID. We further explore our method on trilingual, quadrilingual, and pentalingual models, and observe similar advantages as in the bilingual models, which demonstrates the easy extension to more languages.