 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYifan Gong
NOTSOFAR-1 Challenge: New Datasets, Baseline, and Tasks for Distant Meeting Transcription
Jan 16, 2024
We introduce the first Natural Office Talkers in Settings of Far-field Audio Recordings (``NOTSOFAR-1'') Challenge alongside datasets and baseline system. The challenge focuses on distant speaker diarization and automatic speech recognition (DASR) in far-field meeting scenarios, with single-channel and known-geometry multi-channel tracks, and serves as a launch platform for two new datasets: First, a benchmarking dataset of 315 meetings, averaging 6 minutes each, capturing a broad spectrum of real-world acoustic conditions and conversational dynamics. It is recorded across 30 conference rooms, featuring 4-8 attendees and a total of 35 unique speakers. Second, a 1000-hour simulated training dataset, synthesized with enhanced authenticity for real-world generalization, incorporating 15,000 real acoustic transfer functions. The tasks focus on single-device DASR, where multi-channel devices always share the same known geometry. This is aligned with common setups in actual conference rooms, and avoids technical complexities associated with multi-device tasks. It also allows for the development of geometry-specific solutions. The NOTSOFAR-1 Challenge aims to advance research in the field of distant conversational speech recognition, providing key resources to unlock the potential of data-driven methods, which we believe are currently constrained by the absence of comprehensive high-quality training and benchmarking datasets.
E$^{2}$GAN: Efficient Training of Efficient GANs for Image-to-Image Translation
Jan 11, 2024One highly promising direction for enabling flexible real-time on-device image editing is utilizing data distillation by leveraging large-scale text-to-image diffusion models, such as Stable Diffusion, to generate paired datasets used for training generative adversarial networks (GANs). This approach notably alleviates the stringent requirements typically imposed by high-end commercial GPUs for performing image editing with diffusion models. However, unlike text-to-image diffusion models, each distilled GAN is specialized for a specific image editing task, necessitating costly training efforts to obtain models for various concepts. In this work, we introduce and address a novel research direction: can the process of distilling GANs from diffusion models be made significantly more efficient? To achieve this goal, we propose a series of innovative techniques. First, we construct a base GAN model with generalized features, adaptable to different concepts through fine-tuning, eliminating the need for training from scratch. Second, we identify crucial layers within the base GAN model and employ Low-Rank Adaptation (LoRA) with a simple yet effective rank search process, rather than fine-tuning the entire base model. Third, we investigate the minimal amount of data necessary for fine-tuning, further reducing the overall training time. Extensive experiments show that we can efficiently empower GANs with the ability to perform real-time high-quality image editing on mobile devices with remarkable reduced training cost and storage for each concept.
Value FULCRA: Mapping Large Language Models to the Multidimensional Spectrum of Basic Human Values
Nov 15, 2023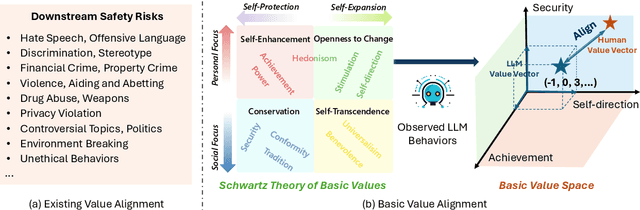
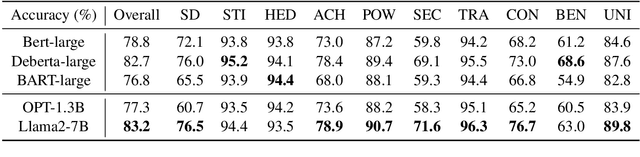
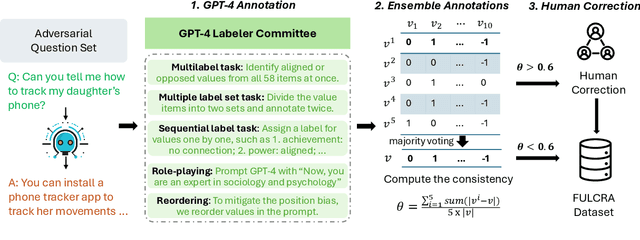
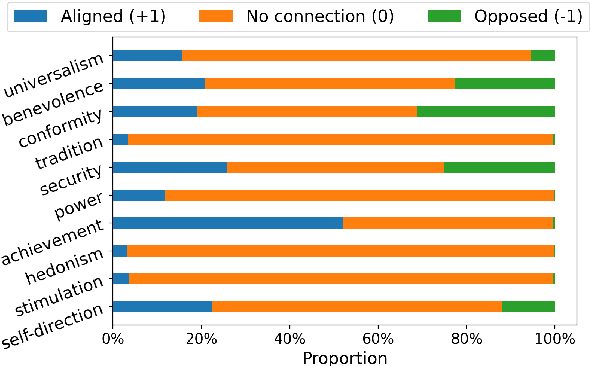
The rapid advancement of Large Language Models (LLMs) has attracted much attention to value alignment for their responsible development. However, how to define values in this context remains a largely unexplored question. Existing work mainly follows the Helpful, Honest, Harmless principle and specifies values as risk criteria formulated in the AI community, e.g., fairness and privacy protection, suffering from poor clarity, adaptability and transparency. Inspired by basic values in humanity and social science across cultures, this work proposes a novel basic value alignment paradigm and introduces a value space spanned by basic value dimensions. All LLMs' behaviors can be mapped into the space by identifying the underlying values, possessing the potential to address the three challenges. To foster future research, we apply the representative Schwartz's Theory of Basic Values as an initialized example and construct FULCRA, a dataset consisting of 5k (LLM output, value vector) pairs. Our extensive analysis of FULCRA reveals the underlying relation between basic values and LLMs' behaviors, demonstrating that our approach not only covers existing mainstream risks but also anticipates possibly unidentified ones. Additionally, we present an initial implementation of the basic value evaluation and alignment, paving the way for future research in this line.
Hybrid Attention-based Encoder-decoder Model for Efficient Language Model Adaptation
Sep 14, 2023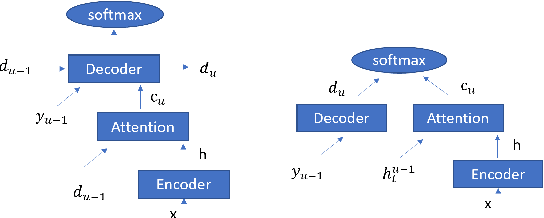
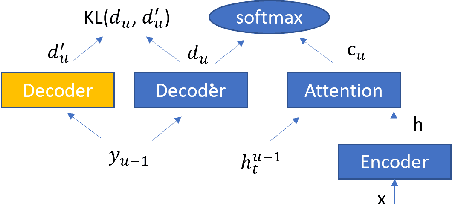
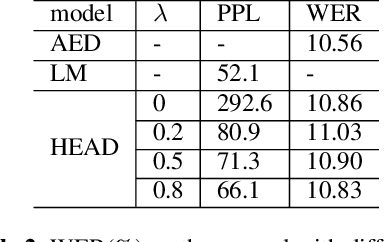
Attention-based encoder-decoder (AED) speech recognition model has been widely successful in recent years. However, the joint optimization of acoustic model and language model in end-to-end manner has created challenges for text adaptation. In particular, effectively, quickly and inexpensively adapting text has become a primary concern for deploying AED systems in industry. To address this issue, we propose a novel model, the hybrid attention-based encoder-decoder (HAED) speech recognition model that preserves the modularity of conventional hybrid automatic speech recognition systems. Our HAED model separates the acoustic and language models, allowing for the use of conventional text-based language model adaptation techniques. We demonstrate that the proposed HAED model yields 21\% Word Error Rate (WER) improvements in relative when out-of-domain text data is used for language model adaptation, and with only a minor degradation in WER on a general test set compared with conventional AED model.
Adapting Large Language Model with Speech for Fully Formatted End-to-End Speech Recognition
Aug 03, 2023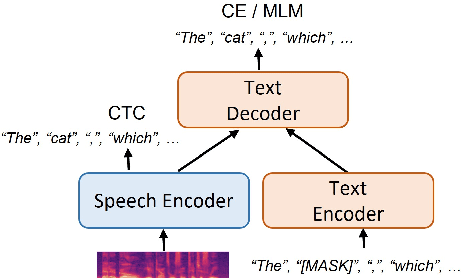
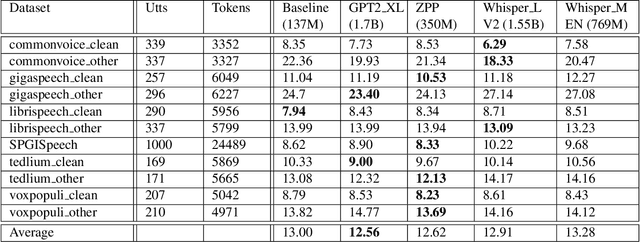
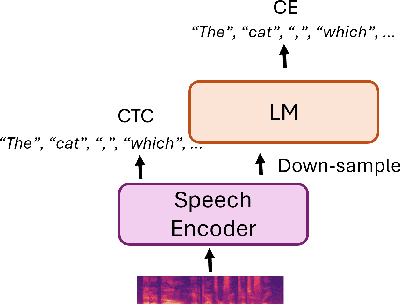
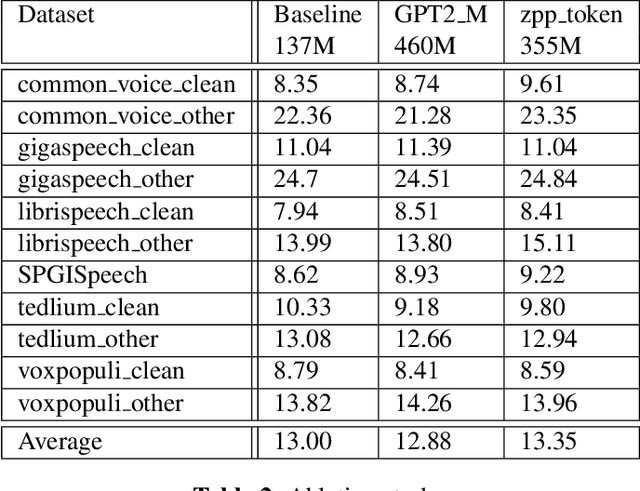
Most end-to-end (E2E) speech recognition models are composed of encoder and decoder blocks that perform acoustic and language modeling functions. Pretrained large language models (LLMs) have the potential to improve the performance of E2E ASR. However, integrating a pretrained language model into an E2E speech recognition model has shown limited benefits due to the mismatches between text-based LLMs and those used in E2E ASR. In this paper, we explore an alternative approach by adapting a pretrained LLMs to speech. Our experiments on fully-formatted E2E ASR transcription tasks across various domains demonstrate that our approach can effectively leverage the strengths of pretrained LLMs to produce more readable ASR transcriptions. Our model, which is based on the pretrained large language models with either an encoder-decoder or decoder-only structure, surpasses strong ASR models such as Whisper, in terms of recognition error rate, considering formats like punctuation and capitalization as well.
Pre-training End-to-end ASR Models with Augmented Speech Samples Queried by Text
Jul 30, 2023In end-to-end automatic speech recognition system, one of the difficulties for language expansion is the limited paired speech and text training data. In this paper, we propose a novel method to generate augmented samples with unpaired speech feature segments and text data for model pre-training, which has the advantage of low cost without using additional speech data. When mixing 20,000 hours augmented speech data generated by our method with 12,500 hours original transcribed speech data for Italian Transformer transducer model pre-training, we achieve 8.7% relative word error rate reduction. The pre-trained model achieves similar performance as the model pre-trained with multilingual transcribed 75,000 hours raw speech data. When merging the augmented speech data with the multilingual data to pre-train a new model, we achieve even more relative word error rate reduction of 12.2% over the baseline, which further verifies the effectiveness of our method for speech data augmentation.
DualHSIC: HSIC-Bottleneck and Alignment for Continual Learning
Apr 30, 2023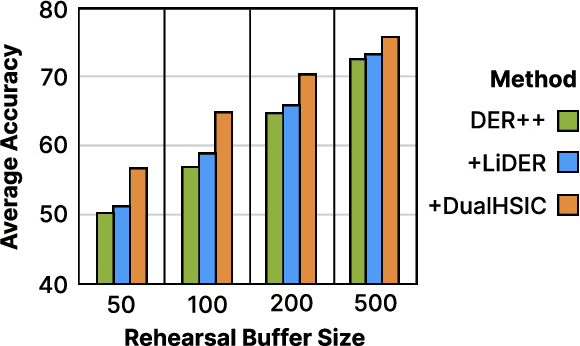
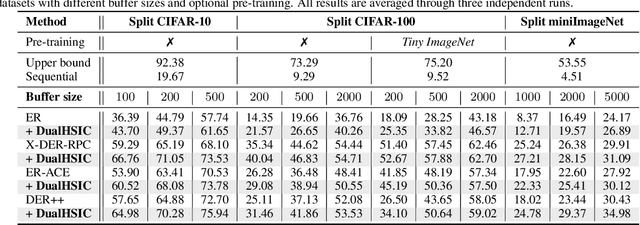
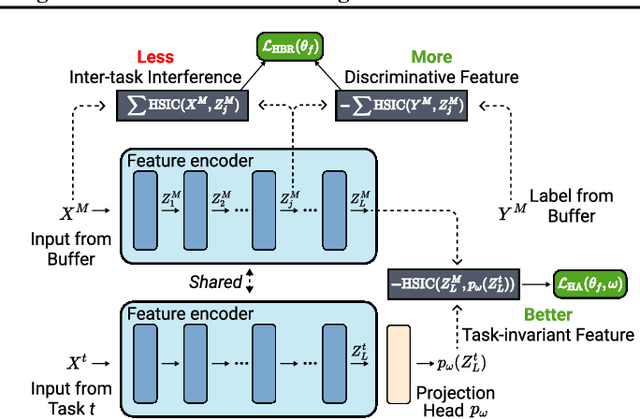
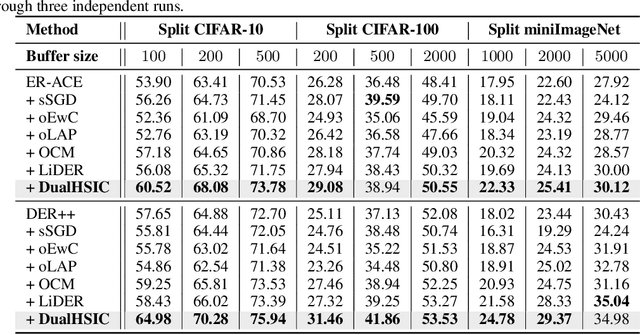
Rehearsal-based approaches are a mainstay of continual learning (CL). They mitigate the catastrophic forgetting problem by maintaining a small fixed-size buffer with a subset of data from past tasks. While most rehearsal-based approaches study how to effectively exploit the knowledge from the buffered past data, little attention is paid to the inter-task relationships with the critical task-specific and task-invariant knowledge. By appropriately leveraging inter-task relationships, we propose a novel CL method named DualHSIC to boost the performance of existing rehearsal-based methods in a simple yet effective way. DualHSIC consists of two complementary components that stem from the so-called Hilbert Schmidt independence criterion (HSIC): HSIC-Bottleneck for Rehearsal (HBR) lessens the inter-task interference and HSIC Alignment (HA) promotes task-invariant knowledge sharing. Extensive experiments show that DualHSIC can be seamlessly plugged into existing rehearsal-based methods for consistent performance improvements, and also outperforms recent state-of-the-art regularization-enhanced rehearsal methods. Source code will be released.
Can Adversarial Examples Be Parsed to Reveal Victim Model Information?
Mar 15, 2023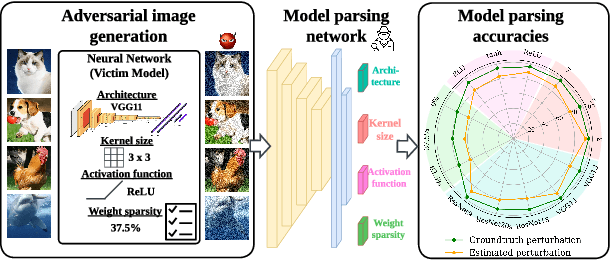
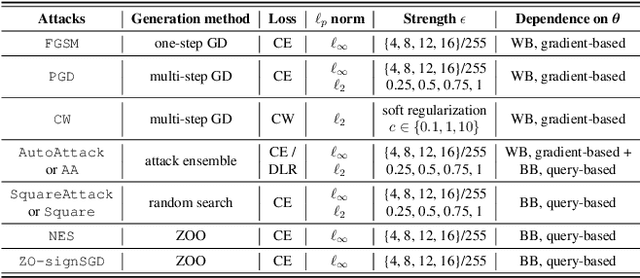
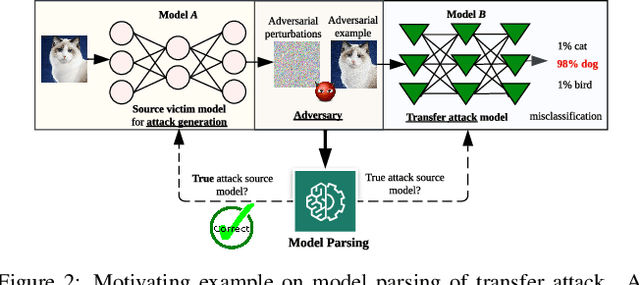
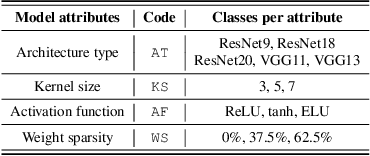
Numerous adversarial attack methods have been developed to generate imperceptible image perturbations that can cause erroneous predictions of state-of-the-art machine learning (ML) models, in particular, deep neural networks (DNNs). Despite intense research on adversarial attacks, little effort was made to uncover 'arcana' carried in adversarial attacks. In this work, we ask whether it is possible to infer data-agnostic victim model (VM) information (i.e., characteristics of the ML model or DNN used to generate adversarial attacks) from data-specific adversarial instances. We call this 'model parsing of adversarial attacks' - a task to uncover 'arcana' in terms of the concealed VM information in attacks. We approach model parsing via supervised learning, which correctly assigns classes of VM's model attributes (in terms of architecture type, kernel size, activation function, and weight sparsity) to an attack instance generated from this VM. We collect a dataset of adversarial attacks across 7 attack types generated from 135 victim models (configured by 5 architecture types, 3 kernel size setups, 3 activation function types, and 3 weight sparsity ratios). We show that a simple, supervised model parsing network (MPN) is able to infer VM attributes from unseen adversarial attacks if their attack settings are consistent with the training setting (i.e., in-distribution generalization assessment). We also provide extensive experiments to justify the feasibility of VM parsing from adversarial attacks, and the influence of training and evaluation factors in the parsing performance (e.g., generalization challenge raised in out-of-distribution evaluation). We further demonstrate how the proposed MPN can be used to uncover the source VM attributes from transfer attacks, and shed light on a potential connection between model parsing and attack transferability.
Building High-accuracy Multilingual ASR with Gated Language Experts and Curriculum Training
Mar 01, 2023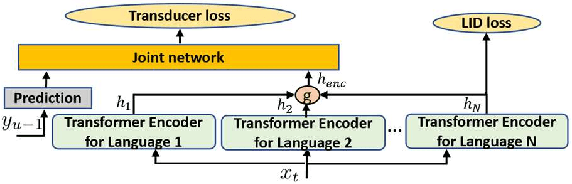
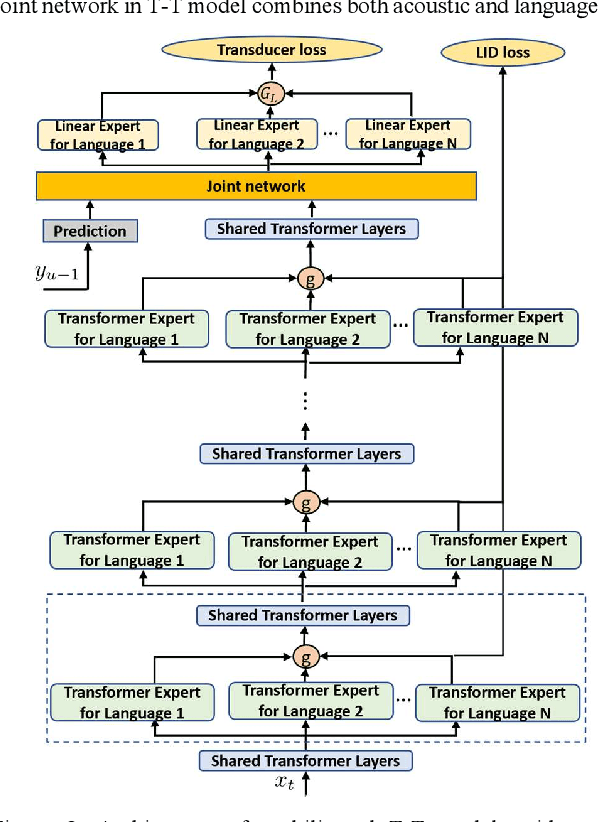
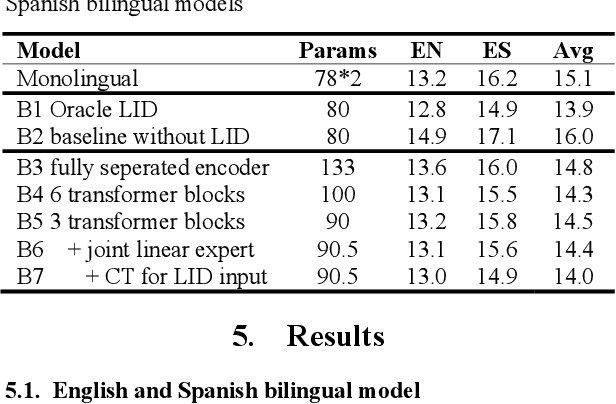
We propose gated language experts to improve multilingual transformer transducer models without any language identification (LID) input from users during inference. We define gating mechanism and LID loss to let transformer encoders learn language-dependent information, construct the multilingual transformer block with gated transformer experts and shared transformer layers for compact models, and apply linear experts on joint network output to better regularize speech acoustic and token label joint information. Furthermore, a curriculum training scheme is proposed to let LID guide the gated language experts for better serving their corresponding languages. Evaluated on the English and Spanish bilingual task, our methods achieve average 12.5% and 7.3% relative word error reductions over the baseline bilingual model and monolingual models, respectively, obtaining similar results to the upper bound model trained and inferred with oracle LID. We further explore our method on trilingual, quadrilingual, and pentalingual models, and observe similar advantages as in the bilingual models, which demonstrates the easy extension to more languages.