 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYinan Yu
Scalability in Building Component Data Annotation: Enhancing Facade Material Classification with Synthetic Data
Apr 12, 2024
Computer vision models trained on Google Street View images can create material cadastres. However, current approaches need manually annotated datasets that are difficult to obtain and often have class imbalance. To address these challenges, this paper fine-tuned a Swin Transformer model on a synthetic dataset generated with DALL-E and compared the performance to a similar manually annotated dataset. Although manual annotation remains the gold standard, the synthetic dataset performance demonstrates a reasonable alternative. The findings will ease annotation needed to develop material cadastres, offering architects insights into opportunities for material reuse, thus contributing to the reduction of demolition waste.
Domain Generalization through Meta-Learning: A Survey
Apr 03, 2024Deep neural networks (DNNs) have revolutionized artificial intelligence but often lack performance when faced with out-of-distribution (OOD) data, a common scenario due to the inevitable domain shifts in real-world applications. This limitation stems from the common assumption that training and testing data share the same distribution-an assumption frequently violated in practice. Despite their effectiveness with large amounts of data and computational power, DNNs struggle with distributional shifts and limited labeled data, leading to overfitting and poor generalization across various tasks and domains. Meta-learning presents a promising approach by employing algorithms that acquire transferable knowledge across various tasks for fast adaptation, eliminating the need to learn each task from scratch. This survey paper delves into the realm of meta-learning with a focus on its contribution to domain generalization. We first clarify the concept of meta-learning for domain generalization and introduce a novel taxonomy based on the feature extraction strategy and the classifier learning methodology, offering a granular view of methodologies. Through an exhaustive review of existing methods and underlying theories, we map out the fundamentals of the field. Our survey provides practical insights and an informed discussion on promising research directions, paving the way for future innovation in meta-learning for domain generalization.
Separable Convolutional Eigen-Filters (SCEF): Building Efficient CNNs Using Redundancy Analysis
Nov 16, 2019



Deep Convolutional Neural Networks (CNNs) have been widely used in computer vision due to its effectiveness. While the high model complexity of CNN enables remarkable learning capacity, the large number of trainable parameters comes with a high cost. In addition to the demand of a large amount of resources, the high complexity of the network can result in a high variance in its generalization performance from a statistical learning theory perspective. One way to reduce the complexity of a network without sacrificing its accuracy is to define and identify redundancies in order to remove them. In this work, we propose a method to observe and analyze redundancies in the weights of 2D convolutional (Conv2D) filters. From our experiments, we observe that 1) the vectorized Conv2D filters exhibit low rank behaviors; 2) the effective ranks of these filters typically decrease when the network goes deeper, and 3) these effective ranks are converging over training steps. Inspired by these observations, we propose a new layer called Separable Convolutional Eigen-Filters (SCEF) as an alternative parameterization to Conv2D filters. A SCEF layer can be easily implemented using the depthwise separable convolutions trained with our proposed training strategy. In addition to the decreased number of trainable parameters by using SCEF, depthwise separable convolutions are known to be more computationally efficient compared to Conv2D operations, which reduces the runtime FLOPs as well. Experiments are conducted on the CIFAR-10 and ImageNet datasets by replacing the Conv2D layers with SCEF. The results have shown an increased accuracy using about 2/3 of the original parameters and reduce the number of FLOPs to 2/3 of the base net.
Learning Hierarchical Feature Space Using CLAss-specific Subspace Multiple Kernel -- Metric Learning for Classification
Oct 21, 2019



Metric learning for classification has been intensively studied over the last decade. The idea is to learn a metric space induced from a normed vector space on which data from different classes are well separated. Different measures of the separation thus lead to various designs of the objective function in the metric learning model. One classical metric is the Mahalanobis distance, where a linear transformation matrix is designed and applied on the original dataset to obtain a new subspace equipped with the Euclidean norm. The kernelized version has also been developed, followed by Multiple-Kernel learning models. In this paper, we consider metric learning to be the identification of the best kernel function with respect to a high class separability in the corresponding metric space. The contribution is twofold: 1) No pairwise computations are required as in most metric learning techniques; 2) Better flexibility and lower computational complexity is achieved using the CLAss-Specific (Multiple) Kernel - Metric Learning (CLAS(M)K-ML). The proposed techniques can be considered as a preprocessing step to any kernel method or kernel approximation technique. An extension to a hierarchical learning structure is also proposed to further improve the classification performance, where on each layer, the CLASMK is computed based on a selected "marginal" subset and feature vectors are constructed by concatenating the features from all previous layers.
SSAP: Single-Shot Instance Segmentation With Affinity Pyramid
Sep 04, 2019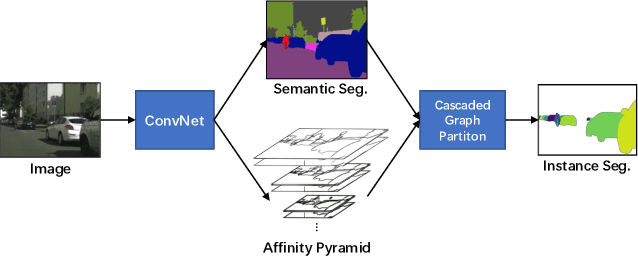
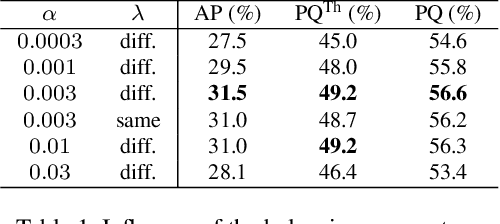
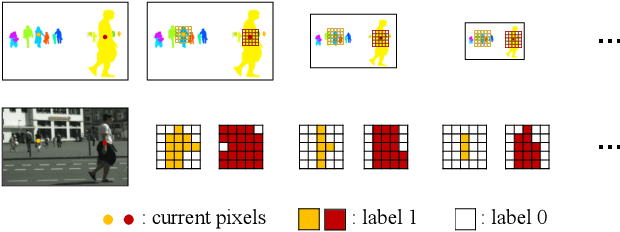
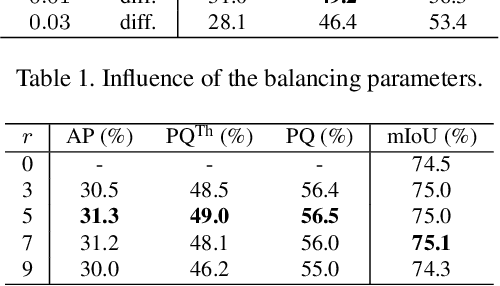
Recently, proposal-free instance segmentation has received increasing attention due to its concise and efficient pipeline. Generally, proposal-free methods generate instance-agnostic semantic segmentation labels and instance-aware features to group pixels into different object instances. However, previous methods mostly employ separate modules for these two sub-tasks and require multiple passes for inference. We argue that treating these two sub-tasks separately is suboptimal. In fact, employing multiple separate modules significantly reduces the potential for application. The mutual benefits between the two complementary sub-tasks are also unexplored. To this end, this work proposes a single-shot proposal-free instance segmentation method that requires only one single pass for prediction. Our method is based on a pixel-pair affinity pyramid, which computes the probability that two pixels belong to the same instance in a hierarchical manner. The affinity pyramid can also be jointly learned with the semantic class labeling and achieve mutual benefits. Moreover, incorporating with the learned affinity pyramid, a novel cascaded graph partition module is presented to sequentially generate instances from coarse to fine. Unlike previous time-consuming graph partition methods, this module achieves $5\times$ speedup and 9% relative improvement on Average-Precision (AP). Our approach achieves state-of-the-art results on the challenging Cityscapes dataset.
High-level Semantic Feature Detection: A New Perspective for Pedestrian Detection
Apr 23, 2019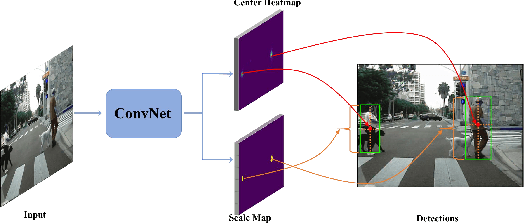

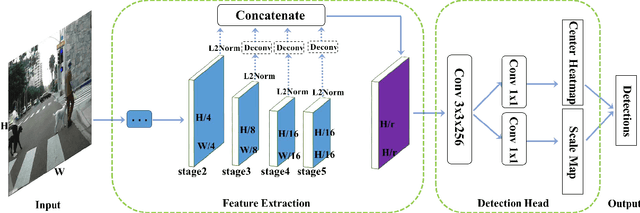
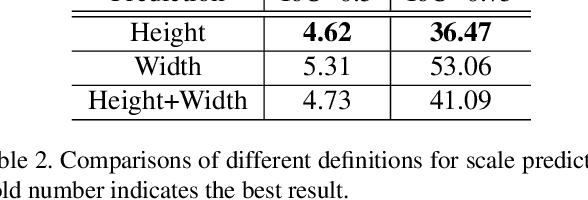
Object detection generally requires sliding-window classifiers in tradition or anchor-based predictions in modern deep learning approaches. However, either of these approaches requires tedious configurations in windows or anchors. In this paper, taking pedestrian detection as an example, we provide a new perspective where detecting objects is motivated as a high-level semantic feature detection task. Like edges, corners, blobs and other feature detectors, the proposed detector scans for feature points all over the image, for which the convolution is naturally suited. However, unlike these traditional low-level features, the proposed detector goes for a higher-level abstraction, that is, we are looking for central points where there are pedestrians, and modern deep models are already capable of such a high-level semantic abstraction. Besides, like blob detection, we also predict the scales of the pedestrian points, which is also a straightforward convolution. Therefore, in this paper, pedestrian detection is simplified as a straightforward center and scale prediction task through convolutions. This way, the proposed method enjoys an anchor-free setting. Though structurally simple, it presents competitive accuracy and good speed on challenging pedestrian detection benchmarks, and hence leading to a new attractive pedestrian detector. Code and models will be available at \url{https://github.com/liuwei16/CSP}.
Elements of Effective Deep Reinforcement Learning towards Tactical Driving Decision Making
Feb 01, 2018



Tactical driving decision making is crucial for autonomous driving systems and has attracted considerable interest in recent years. In this paper, we propose several practical components that can speed up deep reinforcement learning algorithms towards tactical decision making tasks: 1) non-uniform action skipping as a more stable alternative to action-repetition frame skipping, 2) a counter-based penalty for lanes on which ego vehicle has less right-of-road, and 3) heuristic inference-time action masking for apparently undesirable actions. We evaluate the proposed components in a realistic driving simulator and compare them with several baselines. Results show that the proposed scheme provides superior performance in terms of safety, efficiency, and comfort.
Parse Geometry from a Line: Monocular Depth Estimation with Partial Laser Observation
Oct 17, 2016



Many standard robotic platforms are equipped with at least a fixed 2D laser range finder and a monocular camera. Although those platforms do not have sensors for 3D depth sensing capability, knowledge of depth is an essential part in many robotics activities. Therefore, recently, there is an increasing interest in depth estimation using monocular images. As this task is inherently ambiguous, the data-driven estimated depth might be unreliable in robotics applications. In this paper, we have attempted to improve the precision of monocular depth estimation by introducing 2D planar observation from the remaining laser range finder without extra cost. Specifically, we construct a dense reference map from the sparse laser range data, redefining the depth estimation task as estimating the distance between the real and the reference depth. To solve the problem, we construct a novel residual of residual neural network, and tightly combine the classification and regression losses for continuous depth estimation. Experimental results suggest that our method achieves considerable promotion compared to the state-of-the-art methods on both NYUD2 and KITTI, validating the effectiveness of our method on leveraging the additional sensory information. We further demonstrate the potential usage of our method in obstacle avoidance where our methodology provides comprehensive depth information compared to the solution using monocular camera or 2D laser range finder alone.
DenseBox: Unifying Landmark Localization with End to End Object Detection
Sep 19, 2015



How can a single fully convolutional neural network (FCN) perform on object detection? We introduce DenseBox, a unified end-to-end FCN framework that directly predicts bounding boxes and object class confidences through all locations and scales of an image. Our contribution is two-fold. First, we show that a single FCN, if designed and optimized carefully, can detect multiple different objects extremely accurately and efficiently. Second, we show that when incorporating with landmark localization during multi-task learning, DenseBox further improves object detection accuray. We present experimental results on public benchmark datasets including MALF face detection and KITTI car detection, that indicate our DenseBox is the state-of-the-art system for detecting challenging objects such as faces and cars.