 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYingchao Feng
Not Just Learning from Others but Relying on Yourself: A New Perspective on Few-Shot Segmentation in Remote Sensing
Oct 19, 2023



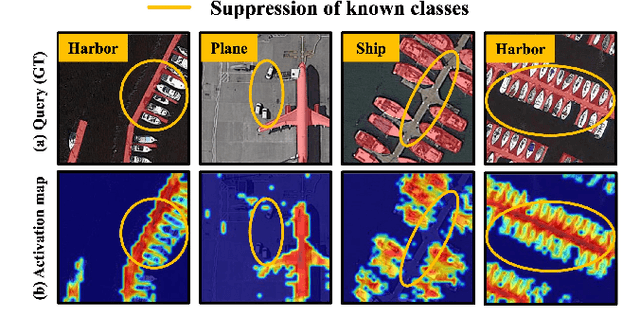
Few-shot segmentation (FSS) is proposed to segment unknown class targets with just a few annotated samples. Most current FSS methods follow the paradigm of mining the semantics from the support images to guide the query image segmentation. However, such a pattern of `learning from others' struggles to handle the extreme intra-class variation, preventing FSS from being directly generalized to remote sensing scenes. To bridge the gap of intra-class variance, we develop a Dual-Mining network named DMNet for cross-image mining and self-mining, meaning that it no longer focuses solely on support images but pays more attention to the query image itself. Specifically, we propose a Class-public Region Mining (CPRM) module to effectively suppress irrelevant feature pollution by capturing the common semantics between the support-query image pair. The Class-specific Region Mining (CSRM) module is then proposed to continuously mine the class-specific semantics of the query image itself in a `filtering' and `purifying' manner. In addition, to prevent the co-existence of multiple classes in remote sensing scenes from exacerbating the collapse of FSS generalization, we also propose a new Known-class Meta Suppressor (KMS) module to suppress the activation of known-class objects in the sample. Extensive experiments on the iSAID and LoveDA remote sensing datasets have demonstrated that our method sets the state-of-the-art with a minimum number of model parameters. Significantly, our model with the backbone of Resnet-50 achieves the mIoU of 49.58% and 51.34% on iSAID under 1-shot and 5-shot settings, outperforming the state-of-the-art method by 1.8% and 1.12%, respectively. The code is publicly available at https://github.com/HanboBizl/DMNet.
Double Similarity Distillation for Semantic Image Segmentation
Jul 19, 2021



The balance between high accuracy and high speed has always been a challenging task in semantic image segmentation. Compact segmentation networks are more widely used in the case of limited resources, while their performances are constrained. In this paper, motivated by the residual learning and global aggregation, we propose a simple yet general and effective knowledge distillation framework called double similarity distillation (DSD) to improve the classification accuracy of all existing compact networks by capturing the similarity knowledge in pixel and category dimensions, respectively. Specifically, we propose a pixel-wise similarity distillation (PSD) module that utilizes residual attention maps to capture more detailed spatial dependencies across multiple layers. Compared with exiting methods, the PSD module greatly reduces the amount of calculation and is easy to expand. Furthermore, considering the differences in characteristics between semantic segmentation task and other computer vision tasks, we propose a category-wise similarity distillation (CSD) module, which can help the compact segmentation network strengthen the global category correlation by constructing the correlation matrix. Combining these two modules, DSD framework has no extra parameters and only a minimal increase in FLOPs. Extensive experiments on four challenging datasets, including Cityscapes, CamVid, ADE20K, and Pascal VOC 2012, show that DSD outperforms current state-of-the-art methods, proving its effectiveness and generality. The code and models will be publicly available.
FAIR1M: A Benchmark Dataset for Fine-grained Object Recognition in High-Resolution Remote Sensing Imagery
Mar 24, 2021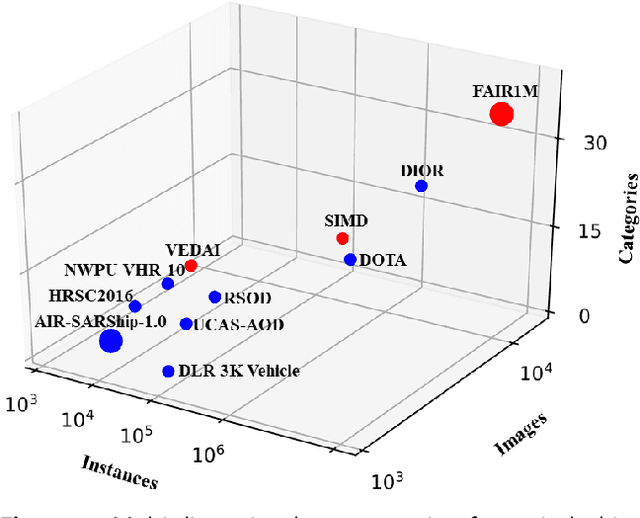
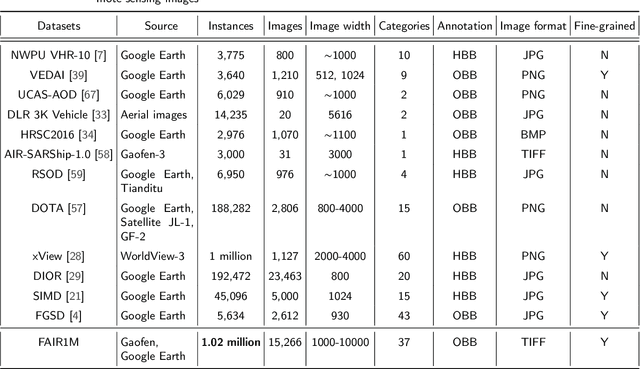
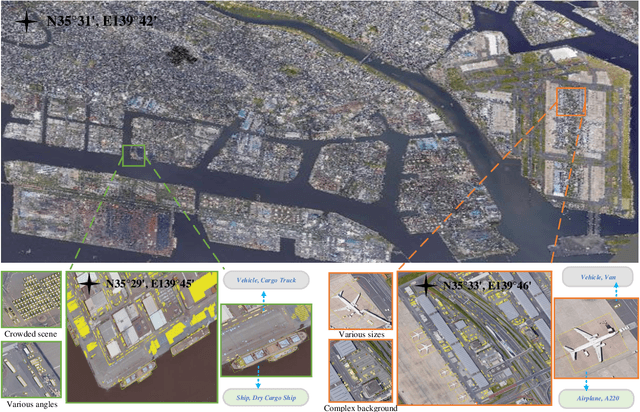
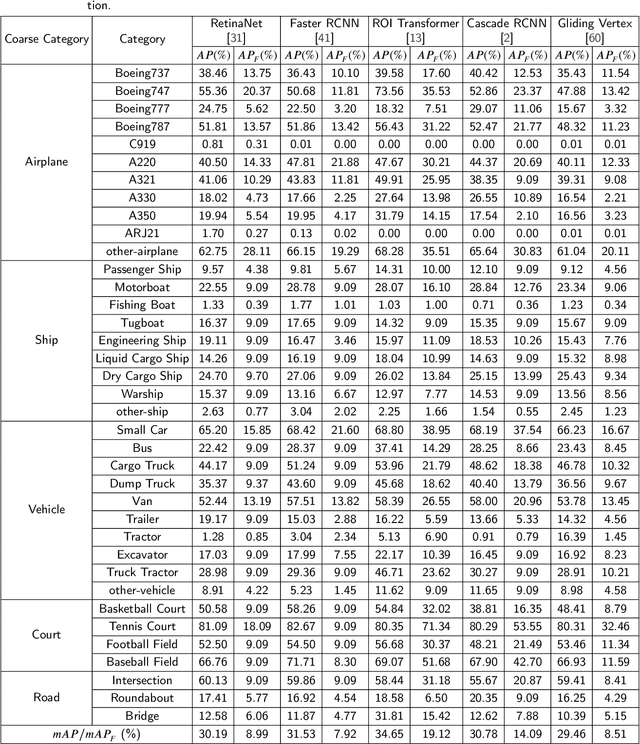
With the rapid development of deep learning, many deep learning-based approaches have made great achievements in object detection task. It is generally known that deep learning is a data-driven method. Data directly impact the performance of object detectors to some extent. Although existing datasets have included common objects in remote sensing images, they still have some limitations in terms of scale, categories, and images. Therefore, there is a strong requirement for establishing a large-scale benchmark on object detection in high-resolution remote sensing images. In this paper, we propose a novel benchmark dataset with more than 1 million instances and more than 15,000 images for Fine-grAined object recognItion in high-Resolution remote sensing imagery which is named as FAIR1M. All objects in the FAIR1M dataset are annotated with respect to 5 categories and 37 sub-categories by oriented bounding boxes. Compared with existing detection datasets dedicated to object detection, the FAIR1M dataset has 4 particular characteristics: (1) it is much larger than other existing object detection datasets both in terms of the quantity of instances and the quantity of images, (2) it provides more rich fine-grained category information for objects in remote sensing images, (3) it contains geographic information such as latitude, longitude and resolution, (4) it provides better image quality owing to a careful data cleaning procedure. To establish a baseline for fine-grained object recognition, we propose a novel evaluation method and benchmark fine-grained object detection tasks and a visual classification task using several State-Of-The-Art (SOTA) deep learning-based models on our FAIR1M dataset. Experimental results strongly indicate that the FAIR1M dataset is closer to practical application and it is considerably more challenging than existing datasets.
Ship Instance Segmentation From Remote Sensing Images Using Sequence Local Context Module
Apr 22, 2019
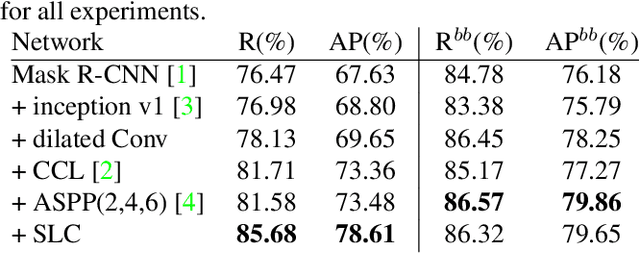
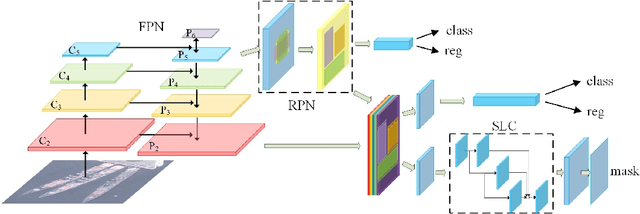

The performance of object instance segmentation in remote sensing images has been greatly improved through the introduction of many landmark frameworks based on convolutional neural network. However, the object densely issue still affects the accuracy of such segmentation frameworks. Objects of the same class are easily confused, which is most likely due to the close docking between objects. We think context information is critical to address this issue. So, we propose a novel framework called SLCMASK-Net, in which a sequence local context module (SLC) is introduced to avoid confusion between objects of the same class. The SLC module applies a sequence of dilation convolution blocks to progressively learn multi-scale context information in the mask branch. Besides, we try to add SLC module to different locations in our framework and experiment with the effect of different parameter settings. Comparative experiments are conducted on remote sensing images acquired by QuickBird with a resolution of $0.5m-1m$ and the results show that the proposed method achieves state-of-the-art performance.