 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYiqun Li
FDSPC: Fast and Direct Smooth Path Planning via Continuous Curvature Integration
May 06, 2024
In recent decades, global path planning of robot has seen significant advancements. Both heuristic search-based methods and probability sampling-based methods have shown capabilities to find feasible solutions in complex scenarios. However, mainstream global path planning algorithms often produce paths with bends, requiring additional smoothing post-processing. In this work, we propose a fast and direct path planning method based on continuous curvature integration. This method ensures path feasibility while directly generating global smooth paths with constant velocity, thus eliminating the need for post-path-smoothing. Furthermore, we compare the proposed method with existing approaches in terms of solution time, path length, memory usage, and smoothness under multiple scenarios. The proposed method is vastly superior to the average performance of state-of-the-art (SOTA) methods, especially in terms of the self-defined $\mathcal{S}_2 $ smoothness (mean angle of steering). These results demonstrate the effectiveness and superiority of our approach in several representative environments.
PEVA-Net: Prompt-Enhanced View Aggregation Network for Zero/Few-Shot Multi-View 3D Shape Recognition
Apr 30, 2024Large vision-language models have impressively promote the performance of 2D visual recognition under zero/few-shot scenarios. In this paper, we focus on exploiting the large vision-language model, i.e., CLIP, to address zero/few-shot 3D shape recognition based on multi-view representations. The key challenge for both tasks is to generate a discriminative descriptor of the 3D shape represented by multiple view images under the scenarios of either without explicit training (zero-shot 3D shape recognition) or training with a limited number of data (few-shot 3D shape recognition). We analyze that both tasks are relevant and can be considered simultaneously. Specifically, leveraging the descriptor which is effective for zero-shot inference to guide the tuning of the aggregated descriptor under the few-shot training can significantly improve the few-shot learning efficacy. Hence, we propose Prompt-Enhanced View Aggregation Network (PEVA-Net) to simultaneously address zero/few-shot 3D shape recognition. Under the zero-shot scenario, we propose to leverage the prompts built up from candidate categories to enhance the aggregation process of multiple view-associated visual features. The resulting aggregated feature serves for effective zero-shot recognition of the 3D shapes. Under the few-shot scenario, we first exploit a transformer encoder to aggregate the view-associated visual features into a global descriptor. To tune the encoder, together with the main classification loss, we propose a self-distillation scheme via a feature distillation loss by treating the zero-shot descriptor as the guidance signal for the few-shot descriptor. This scheme can significantly enhance the few-shot learning efficacy.
Exploiting Low-level Representations for Ultra-Fast Road Segmentation
Feb 06, 2024Achieving real-time and accuracy on embedded platforms has always been the pursuit of road segmentation methods. To this end, they have proposed many lightweight networks. However, they ignore the fact that roads are "stuff" (background or environmental elements) rather than "things" (specific identifiable objects), which inspires us to explore the feasibility of representing roads with low-level instead of high-level features. Surprisingly, we find that the primary stage of mainstream network models is sufficient to represent most pixels of the road for segmentation. Motivated by this, we propose a Low-level Feature Dominated Road Segmentation network (LFD-RoadSeg). Specifically, LFD-RoadSeg employs a bilateral structure. The spatial detail branch is firstly designed to extract low-level feature representation for the road by the first stage of ResNet-18. To suppress texture-less regions mistaken as the road in the low-level feature, the context semantic branch is then designed to extract the context feature in a fast manner. To this end, in the second branch, we asymmetrically downsample the input image and design an aggregation module to achieve comparable receptive fields to the third stage of ResNet-18 but with less time consumption. Finally, to segment the road from the low-level feature, a selective fusion module is proposed to calculate pixel-wise attention between the low-level representation and context feature, and suppress the non-road low-level response by this attention. On KITTI-Road, LFD-RoadSeg achieves a maximum F1-measure (MaxF) of 95.21% and an average precision of 93.71%, while reaching 238 FPS on a single TITAN Xp and 54 FPS on a Jetson TX2, all with a compact model size of just 936k parameters. The source code is available at https://github.com/zhouhuan-hust/LFD-RoadSeg.
Fast Safe Rectangular Corridor-based Online AGV Trajectory Optimization with Obstacle Avoidance
Sep 14, 2023
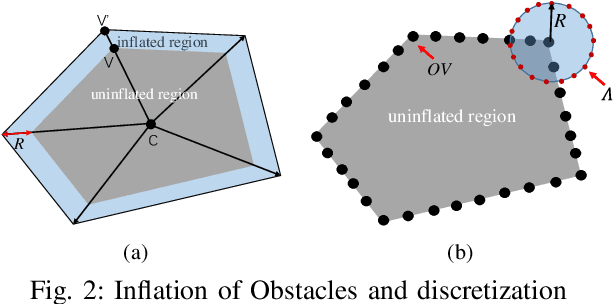
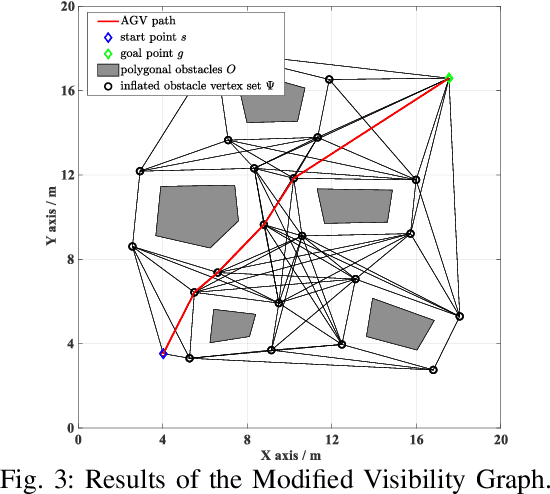
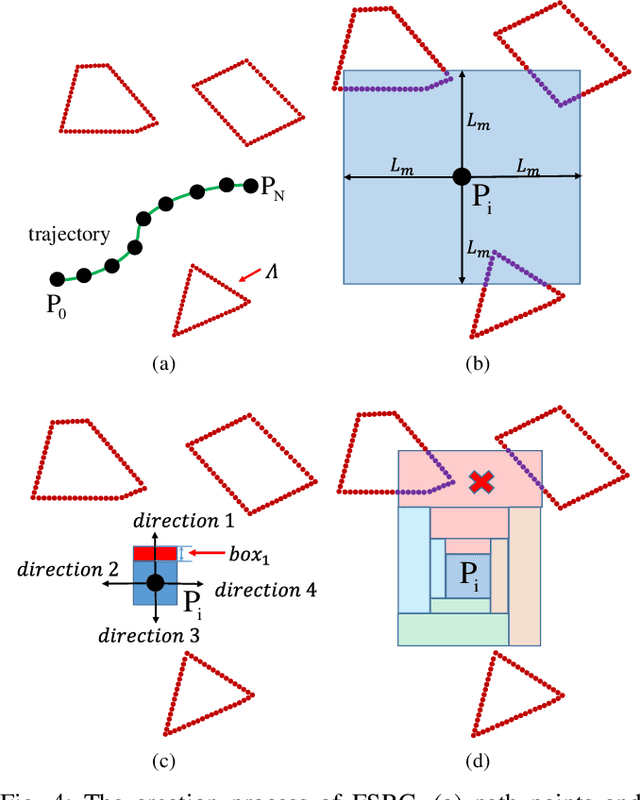
Automated Guided Vehicles (AGVs) are widely adopted in various industries due to their efficiency and adaptability. However, safely deploying AGVs in dynamic environments remains a significant challenge. This paper introduces an online trajectory optimization framework, the Fast Safe Rectangular Corridor (FSRC), designed for AGVs in obstacle-rich settings. The primary challenge is efficiently planning trajectories that prioritize safety and collision avoidance. To tackle this challenge, the FSRC algorithm constructs convex regions, represented as rectangular corridors, to address obstacle avoidance constraints within an optimal control problem. This conversion from non-convex to box constraints improves the collision avoidance efficiency and quality. Additionally, the Modified Visibility Graph algorithm speeds up path planning, and a boundary discretization strategy expedites FSRC construction. The framework also includes a dynamic obstacle avoidance strategy for real-time adaptability. Our framework's effectiveness and superiority have been demonstrated in experiments, particularly in computational efficiency (see Fig. \ref{fig:case1} and \ref{fig:case23}). Compared to state-of-the-art frameworks, our trajectory planning framework significantly enhances computational efficiency, ranging from 1 to 2 orders of magnitude (see Table \ref{tab:res}). Notably, the FSRC algorithm outperforms other safe convex corridor-based methods, substantially improving computational efficiency by 1 to 2 orders of magnitude (see Table \ref{tab:FRSC}).
SCA-PVNet: Self-and-Cross Attention Based Aggregation of Point Cloud and Multi-View for 3D Object Retrieval
Jul 20, 2023To address 3D object retrieval, substantial efforts have been made to generate highly discriminative descriptors of 3D objects represented by a single modality, e.g., voxels, point clouds or multi-view images. It is promising to leverage the complementary information from multi-modality representations of 3D objects to further improve retrieval performance. However, multi-modality 3D object retrieval is rarely developed and analyzed on large-scale datasets. In this paper, we propose self-and-cross attention based aggregation of point cloud and multi-view images (SCA-PVNet) for 3D object retrieval. With deep features extracted from point clouds and multi-view images, we design two types of feature aggregation modules, namely the In-Modality Aggregation Module (IMAM) and the Cross-Modality Aggregation Module (CMAM), for effective feature fusion. IMAM leverages a self-attention mechanism to aggregate multi-view features while CMAM exploits a cross-attention mechanism to interact point cloud features with multi-view features. The final descriptor of a 3D object for object retrieval can be obtained via concatenating the aggregated features from both modules. Extensive experiments and analysis are conducted on three datasets, ranging from small to large scale, to show the superiority of the proposed SCA-PVNet over the state-of-the-art methods.
UDC 2020 Challenge on Image Restoration of Under-Display Camera: Methods and Results
Aug 18, 2020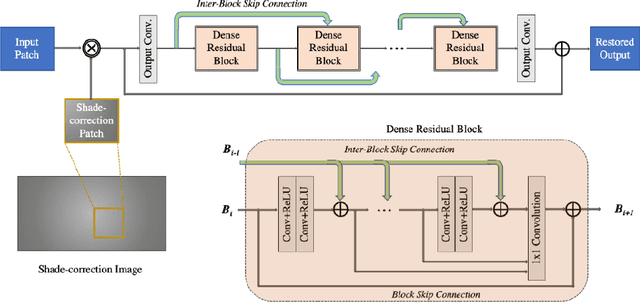
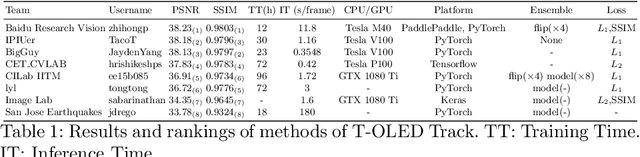
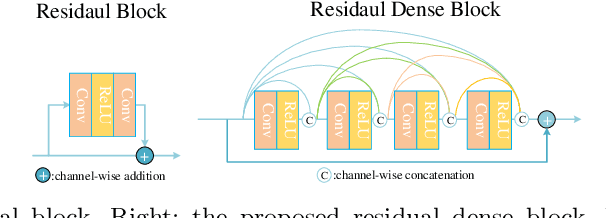
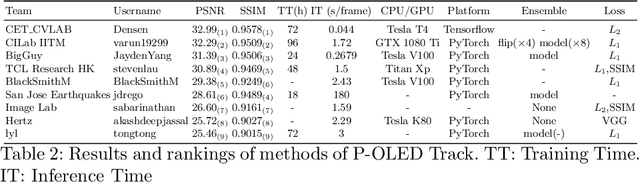
This paper is the report of the first Under-Display Camera (UDC) image restoration challenge in conjunction with the RLQ workshop at ECCV 2020. The challenge is based on a newly-collected database of Under-Display Camera. The challenge tracks correspond to two types of display: a 4k Transparent OLED (T-OLED) and a phone Pentile OLED (P-OLED). Along with about 150 teams registered the challenge, eight and nine teams submitted the results during the testing phase for each track. The results in the paper are state-of-the-art restoration performance of Under-Display Camera Restoration. Datasets and paper are available at https://yzhouas.github.io/projects/UDC/udc.html.
Few-Shot Defect Segmentation Leveraging Abundant Normal Training Samples Through Normal Background Regularization and Crop-and-Paste Operation
Jul 18, 2020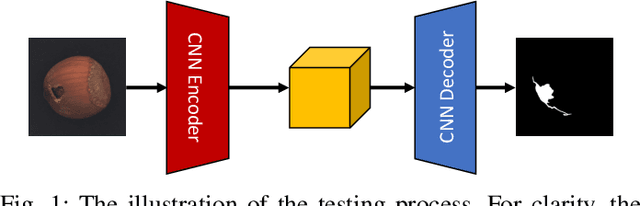
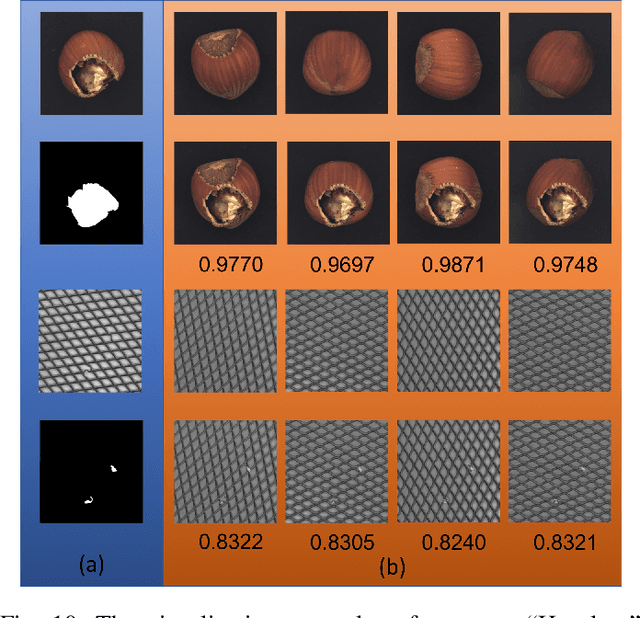
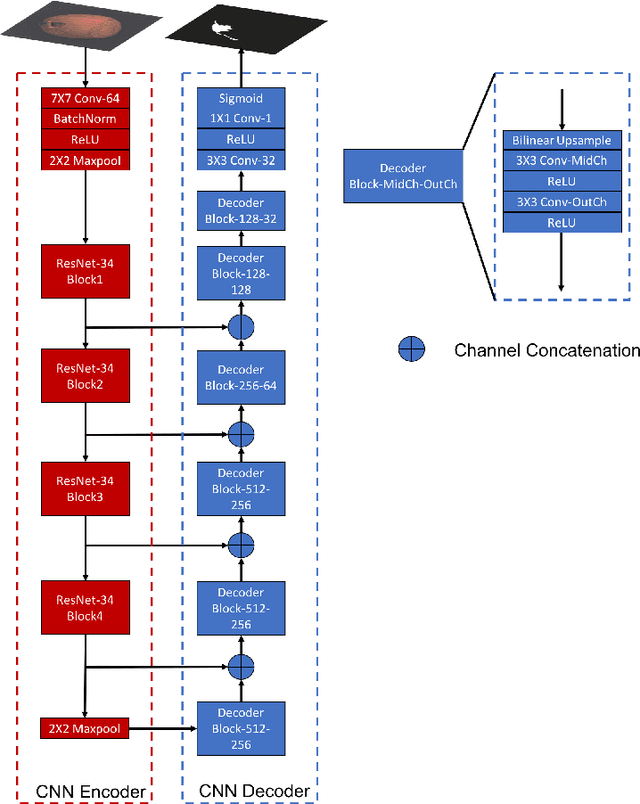
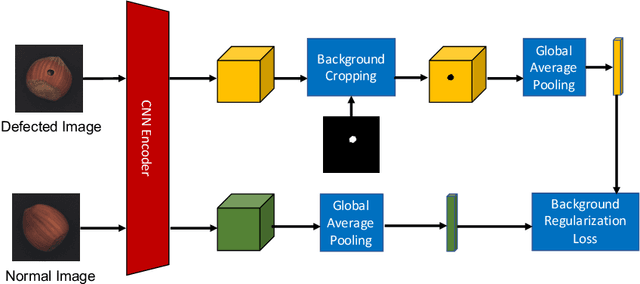
In industrial product quality assessment, it is essential to determine whether a product is defect-free and further analyze the severity of anomality. To this end, accurate defect segmentation on images of products provides an important functionality. In industrial inspection tasks, it is common to capture abundant defect-free image samples but very limited anomalous ones. Therefore, it is critical to develop automatic and accurate defect segmentation systems using only a small number of annotated anomalous training images. This paper tackles the challenging few-shot defect segmentation task with sufficient normal (defect-free) training images but very few anomalous ones. We present two effective regularization techniques via incorporating abundant defect-free images into the training of a UNet-like encoder-decoder defect segmentation network. We first propose a Normal Background Regularization (NBR) loss which is jointly minimized with the segmentation loss, enhancing the encoder network to produce distinctive representations for normal regions. Secondly, we crop/paste defective regions to the randomly selected normal images for data augmentation and propose a weighted binary cross-entropy loss to enhance the training by emphasizing more realistic crop-and-pasted augmented images based on feature-level similarity comparison. Both techniques are implemented on an encoder-decoder segmentation network backboned by ResNet-34 for few-shot defect segmentation. Extensive experiments are conducted on the recently released MVTec Anomaly Detection dataset with high-resolution industrial images. Under both 1-shot and 5-shot defect segmentation settings, the proposed method significantly outperforms several benchmarking methods.
DDR-ID: Dual Deep Reconstruction Networks Based Image Decomposition for Anomaly Detection
Jul 18, 2020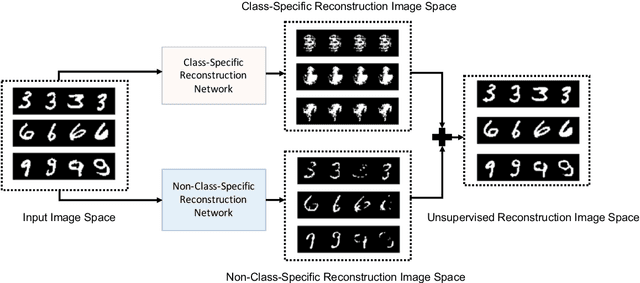


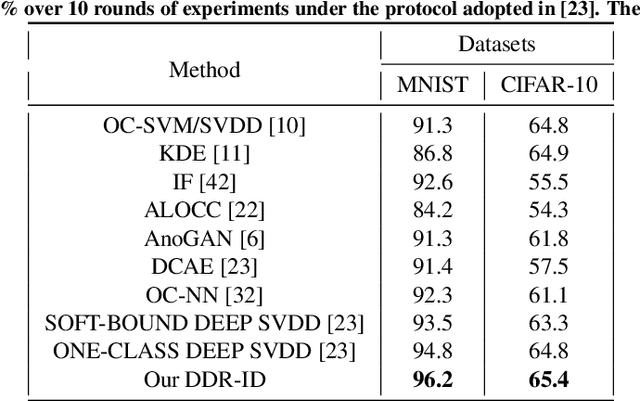
One pivot challenge for image anomaly (AD) detection is to learn discriminative information only from normal class training images. Most image reconstruction based AD methods rely on the discriminative capability of reconstruction error. This is heuristic as image reconstruction is unsupervised without incorporating normal-class-specific information. In this paper, we propose an AD method called dual deep reconstruction networks based image decomposition (DDR-ID). The networks are trained by jointly optimizing for three losses: the one-class loss, the latent space constrain loss and the reconstruction loss. After training, DDR-ID can decompose an unseen image into its normal class and the residual components, respectively. Two anomaly scores are calculated to quantify the anomalous degree of the image in either normal class latent space or reconstruction image space. Thereby, anomaly detection can be performed via thresholding the anomaly score. The experiments demonstrate that DDR-ID outperforms multiple related benchmarking methods in image anomaly detection using MNIST, CIFAR-10 and Endosome datasets and adversarial attack detection using GTSRB dataset.
Machine Learning and Control Theory
Jun 10, 2020
We survey in this article the connections between Machine Learning and Control Theory. Control Theory provide useful concepts and tools for Machine Learning. Conversely Machine Learning can be used to solve large control problems. In the first part of the paper, we develop the connections between reinforcement learning and Markov Decision Processes, which are discrete time control problems. In the second part, we review the concept of supervised learning and the relation with static optimization. Deep learning which extends supervised learning, can be viewed as a control problem. In the third part, we present the links between stochastic gradient descent and mean-field theory. Conversely, in the fourth and fifth parts, we review machine learning approaches to stochastic control problems, and focus on the deterministic case, to explain, more easily, the numerical algorithms.
FaultNet: Faulty Rail-Valves Detection using Deep Learning and Computer Vision
Nov 09, 2019

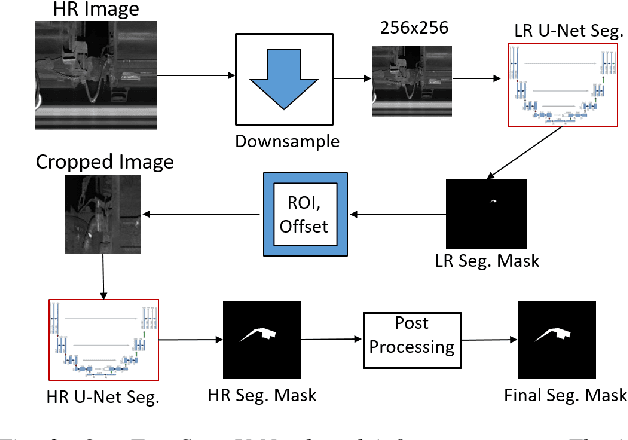
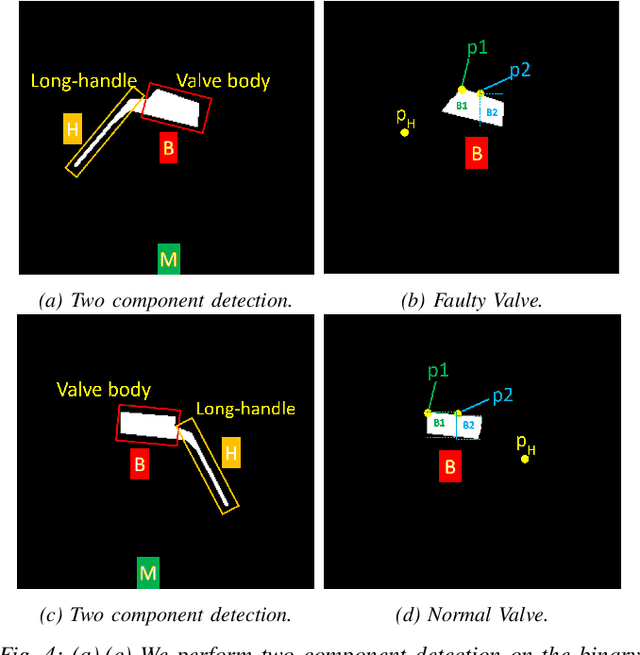
Regular inspection of rail valves and engines is an important task to ensure the safety and efficiency of railway networks around the globe. Over the past decade, computer vision and pattern recognition based techniques have gained traction for such inspection and defect detection tasks. An automated end-to-end trained system can potentially provide a low-cost, high throughput, and cheap alternative to manual visual inspection of these components. However, such systems require a huge amount of defective images for networks to understand complex defects. In this paper, a multi-phase deep learning based technique is proposed to perform accurate fault detection of rail-valves. Our approach uses a two-step method to perform high precision image segmentation of rail-valves resulting in pixel-wise accurate segmentation. Thereafter, a computer vision technique is used to identify faulty valves. We demonstrate that the proposed approach results in improved detection performance when compared to current state-of-theart techniques used in fault detection.
* 8 pages, 8 figures, ITSC 2019