 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYixue Hao
MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors
May 02, 2024
Large 2D vision-language models (2D-LLMs) have gained significant attention by bridging Large Language Models (LLMs) with images using a simple projector. Inspired by their success, large 3D point cloud-language models (3D-LLMs) also integrate point clouds into LLMs. However, directly aligning point clouds with LLM requires expensive training costs, typically in hundreds of GPU-hours on A100, which hinders the development of 3D-LLMs. In this paper, we introduce MiniGPT-3D, an efficient and powerful 3D-LLM that achieves multiple SOTA results while training for only 27 hours on one RTX 3090. Specifically, we propose to align 3D point clouds with LLMs using 2D priors from 2D-LLMs, which can leverage the similarity between 2D and 3D visual information. We introduce a novel four-stage training strategy for modality alignment in a cascaded way, and a mixture of query experts module to adaptively aggregate features with high efficiency. Moreover, we utilize parameter-efficient fine-tuning methods LoRA and Norm fine-tuning, resulting in only 47.8M learnable parameters, which is up to 260x fewer than existing methods. Extensive experiments show that MiniGPT-3D achieves SOTA on 3D object classification and captioning tasks, with significantly cheaper training costs. Notably, MiniGPT-3D gains an 8.12 increase on GPT-4 evaluation score for the challenging object captioning task compared to ShapeLLM-13B, while the latter costs 160 total GPU-hours on 8 A800. We are the first to explore the efficient 3D-LLM, offering new insights to the community. Code and weights are available at https://github.com/TangYuan96/MiniGPT-3D.
PDF: A Probability-Driven Framework for Open World 3D Point Cloud Semantic Segmentation
Apr 01, 2024Existing point cloud semantic segmentation networks cannot identify unknown classes and update their knowledge, due to a closed-set and static perspective of the real world, which would induce the intelligent agent to make bad decisions. To address this problem, we propose a Probability-Driven Framework (PDF) for open world semantic segmentation that includes (i) a lightweight U-decoder branch to identify unknown classes by estimating the uncertainties, (ii) a flexible pseudo-labeling scheme to supply geometry features along with probability distribution features of unknown classes by generating pseudo labels, and (iii) an incremental knowledge distillation strategy to incorporate novel classes into the existing knowledge base gradually. Our framework enables the model to behave like human beings, which could recognize unknown objects and incrementally learn them with the corresponding knowledge. Experimental results on the S3DIS and ScanNetv2 datasets demonstrate that the proposed PDF outperforms other methods by a large margin in both important tasks of open world semantic segmentation.
CasFusionNet: A Cascaded Network for Point Cloud Semantic Scene Completion by Dense Feature Fusion
Nov 24, 2022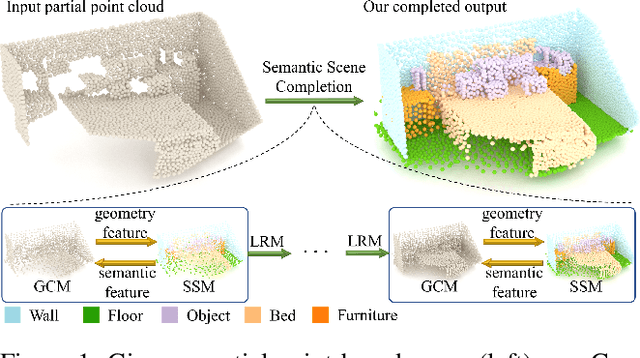
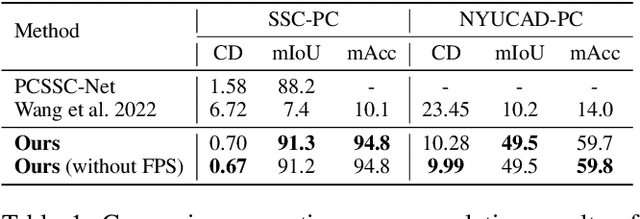
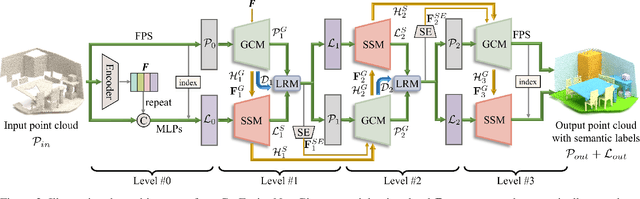
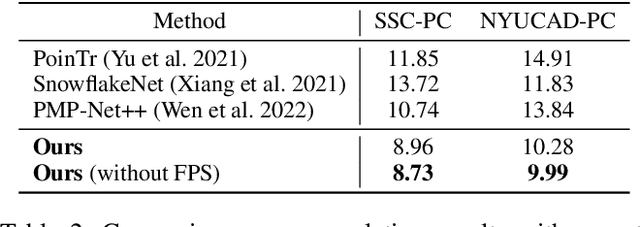
Semantic scene completion (SSC) aims to complete a partial 3D scene and predict its semantics simultaneously. Most existing works adopt the voxel representations, thus suffering from the growth of memory and computation cost as the voxel resolution increases. Though a few works attempt to solve SSC from the perspective of 3D point clouds, they have not fully exploited the correlation and complementarity between the two tasks of scene completion and semantic segmentation. In our work, we present CasFusionNet, a novel cascaded network for point cloud semantic scene completion by dense feature fusion. Specifically, we design (i) a global completion module (GCM) to produce an upsampled and completed but coarse point set, (ii) a semantic segmentation module (SSM) to predict the per-point semantic labels of the completed points generated by GCM, and (iii) a local refinement module (LRM) to further refine the coarse completed points and the associated labels from a local perspective. We organize the above three modules via dense feature fusion in each level, and cascade a total of four levels, where we also employ feature fusion between each level for sufficient information usage. Both quantitative and qualitative results on our compiled two point-based datasets validate the effectiveness and superiority of our CasFusionNet compared to state-of-the-art methods in terms of both scene completion and semantic segmentation. The codes and datasets are available at: https://github.com/JinfengX/CasFusionNet.
Label-less Learning for Traffic Control in an Edge Network
Aug 29, 2018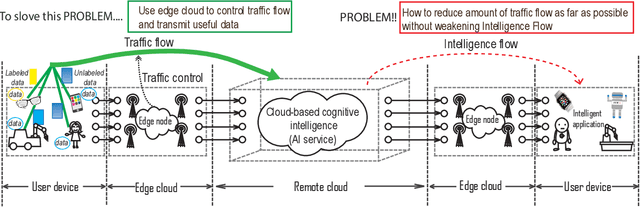
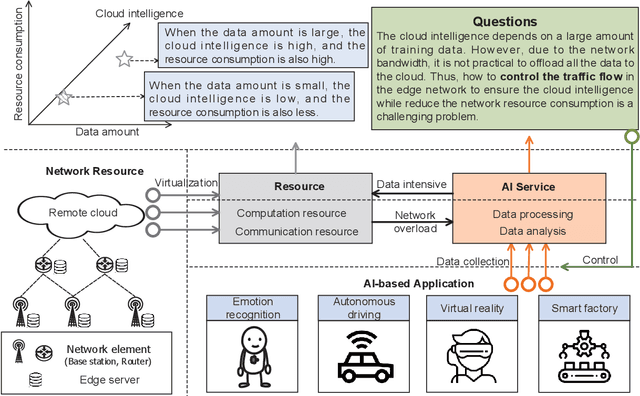
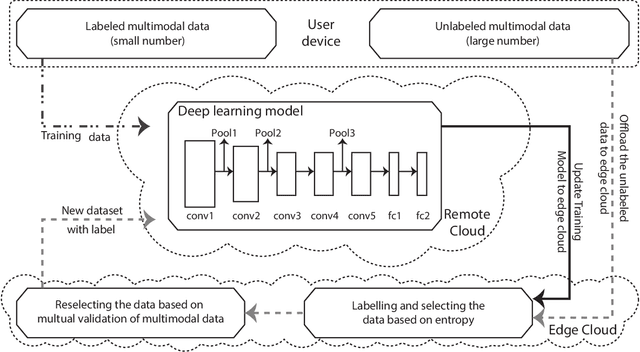
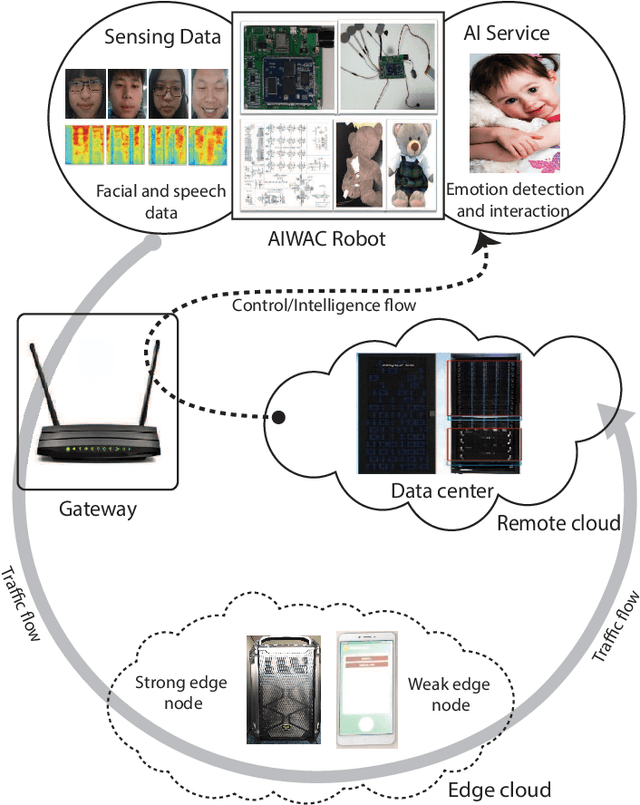
With the development of intelligent applications (e.g., self-driving, real-time emotion recognition, etc), there are higher requirements for the cloud intelligence. However, cloud intelligence depends on the multi-modal data collected by user equipments (UEs). Due to the limited capacity of network bandwidth, offloading all data generated from the UEs to the remote cloud is impractical. Thus, in this article, we consider the challenging issue of achieving a certain level of cloud intelligence while reducing network traffic. In order to solve this problem, we design a traffic control algorithm based on label-less learning on the edge cloud, which is dubbed as LLTC. By the use of the limited computing and storage resources at edge cloud, LLTC evaluates the value of data, which will be offloaded. Specifically, we first give a statement of the problem and the system architecture. Then, we design the LLTC algorithm in detail. Finally, we set up the system testbed. Experimental results show that the proposed LLTC can guarantee the required cloud intelligence while minimizing the amount of data transmission.