 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXianzhi Li
MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors
May 02, 2024
Large 2D vision-language models (2D-LLMs) have gained significant attention by bridging Large Language Models (LLMs) with images using a simple projector. Inspired by their success, large 3D point cloud-language models (3D-LLMs) also integrate point clouds into LLMs. However, directly aligning point clouds with LLM requires expensive training costs, typically in hundreds of GPU-hours on A100, which hinders the development of 3D-LLMs. In this paper, we introduce MiniGPT-3D, an efficient and powerful 3D-LLM that achieves multiple SOTA results while training for only 27 hours on one RTX 3090. Specifically, we propose to align 3D point clouds with LLMs using 2D priors from 2D-LLMs, which can leverage the similarity between 2D and 3D visual information. We introduce a novel four-stage training strategy for modality alignment in a cascaded way, and a mixture of query experts module to adaptively aggregate features with high efficiency. Moreover, we utilize parameter-efficient fine-tuning methods LoRA and Norm fine-tuning, resulting in only 47.8M learnable parameters, which is up to 260x fewer than existing methods. Extensive experiments show that MiniGPT-3D achieves SOTA on 3D object classification and captioning tasks, with significantly cheaper training costs. Notably, MiniGPT-3D gains an 8.12 increase on GPT-4 evaluation score for the challenging object captioning task compared to ShapeLLM-13B, while the latter costs 160 total GPU-hours on 8 A800. We are the first to explore the efficient 3D-LLM, offering new insights to the community. Code and weights are available at https://github.com/TangYuan96/MiniGPT-3D.
Mamba3D: Enhancing Local Features for 3D Point Cloud Analysis via State Space Model
Apr 23, 2024Existing Transformer-based models for point cloud analysis suffer from quadratic complexity, leading to compromised point cloud resolution and information loss. In contrast, the newly proposed Mamba model, based on state space models (SSM), outperforms Transformer in multiple areas with only linear complexity. However, the straightforward adoption of Mamba does not achieve satisfactory performance on point cloud tasks. In this work, we present Mamba3D, a state space model tailored for point cloud learning to enhance local feature extraction, achieving superior performance, high efficiency, and scalability potential. Specifically, we propose a simple yet effective Local Norm Pooling (LNP) block to extract local geometric features. Additionally, to obtain better global features, we introduce a bidirectional SSM (bi-SSM) with both a token forward SSM and a novel backward SSM that operates on the feature channel. Extensive experimental results show that Mamba3D surpasses Transformer-based counterparts and concurrent works in multiple tasks, with or without pre-training. Notably, Mamba3D achieves multiple SoTA, including an overall accuracy of 92.6% (train from scratch) on the ScanObjectNN and 95.1% (with single-modal pre-training) on the ModelNet40 classification task, with only linear complexity.
PDF: A Probability-Driven Framework for Open World 3D Point Cloud Semantic Segmentation
Apr 01, 2024Existing point cloud semantic segmentation networks cannot identify unknown classes and update their knowledge, due to a closed-set and static perspective of the real world, which would induce the intelligent agent to make bad decisions. To address this problem, we propose a Probability-Driven Framework (PDF) for open world semantic segmentation that includes (i) a lightweight U-decoder branch to identify unknown classes by estimating the uncertainties, (ii) a flexible pseudo-labeling scheme to supply geometry features along with probability distribution features of unknown classes by generating pseudo labels, and (iii) an incremental knowledge distillation strategy to incorporate novel classes into the existing knowledge base gradually. Our framework enables the model to behave like human beings, which could recognize unknown objects and incrementally learn them with the corresponding knowledge. Experimental results on the S3DIS and ScanNetv2 datasets demonstrate that the proposed PDF outperforms other methods by a large margin in both important tasks of open world semantic segmentation.
SKU-Patch: Towards Efficient Instance Segmentation for Unseen Objects in Auto-Store
Nov 08, 2023In large-scale storehouses, precise instance masks are crucial for robotic bin picking but are challenging to obtain. Existing instance segmentation methods typically rely on a tedious process of scene collection, mask annotation, and network fine-tuning for every single Stock Keeping Unit (SKU). This paper presents SKU-Patch, a new patch-guided instance segmentation solution, leveraging only a few image patches for each incoming new SKU to predict accurate and robust masks, without tedious manual effort and model re-training. Technical-wise, we design a novel transformer-based network with (i) a patch-image correlation encoder to capture multi-level image features calibrated by patch information and (ii) a patch-aware transformer decoder with parallel task heads to generate instance masks. Extensive experiments on four storehouse benchmarks manifest that SKU-Patch is able to achieve the best performance over the state-of-the-art methods. Also, SKU-Patch yields an average of nearly 100% grasping success rate on more than 50 unseen SKUs in a robot-aided auto-store logistic pipeline, showing its effectiveness and practicality.
Geo-Encoder: A Chunk-Argument Bi-Encoder Framework for Chinese Geographic Re-Ranking
Sep 04, 2023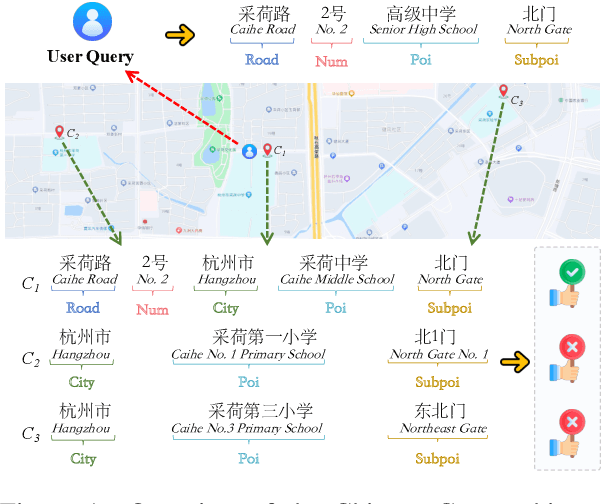
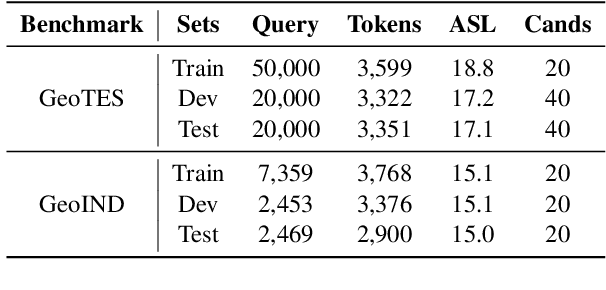
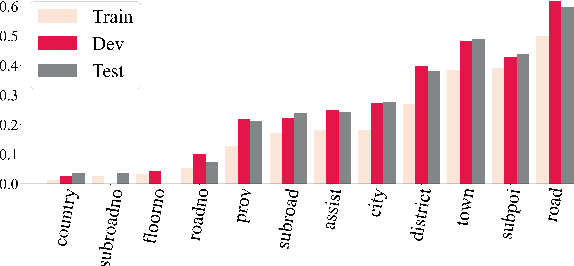
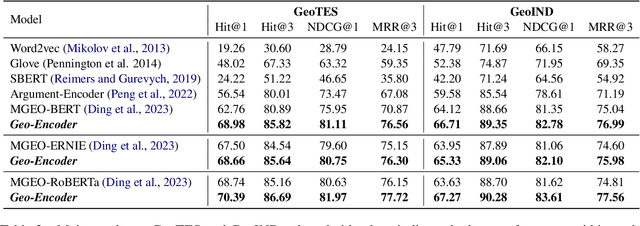
Chinese geographic re-ranking task aims to find the most relevant addresses among retrieved candidates, which is crucial for location-related services such as navigation maps. Unlike the general sentences, geographic contexts are closely intertwined with geographical concepts, from general spans (e.g., province) to specific spans (e.g., road). Given this feature, we propose an innovative framework, namely Geo-Encoder, to more effectively integrate Chinese geographical semantics into re-ranking pipelines. Our methodology begins by employing off-the-shelf tools to associate text with geographical spans, treating them as chunking units. Then, we present a multi-task learning module to simultaneously acquire an effective attention matrix that determines chunk contributions to extra semantic representations. Furthermore, we put forth an asynchronous update mechanism for the proposed addition task, aiming to guide the model capable of effectively focusing on specific chunks. Experiments on two distinct Chinese geographic re-ranking datasets, show that the Geo-Encoder achieves significant improvements when compared to state-of-the-art baselines. Notably, it leads to a substantial improvement in the Hit@1 score of MGEO-BERT, increasing it by 6.22% from 62.76 to 68.98 on the GeoTES dataset.
Point-Bind & Point-LLM: Aligning Point Cloud with Multi-modality for 3D Understanding, Generation, and Instruction Following
Sep 01, 2023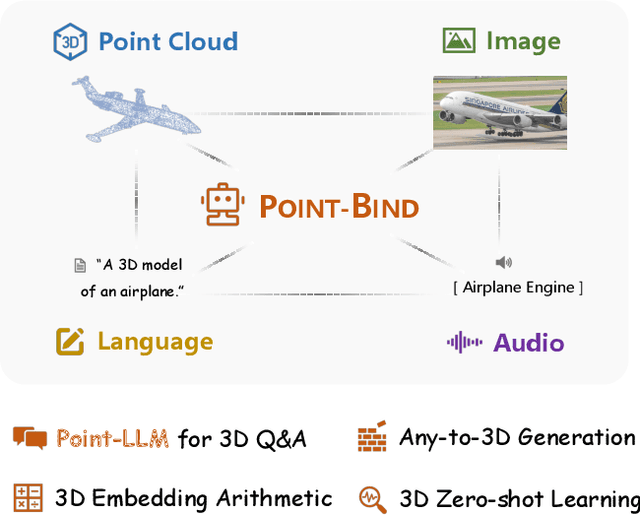
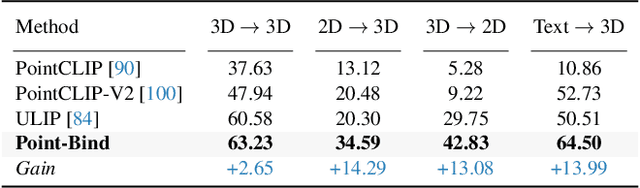
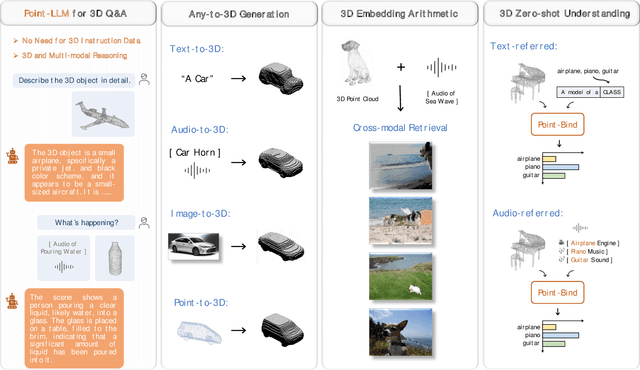
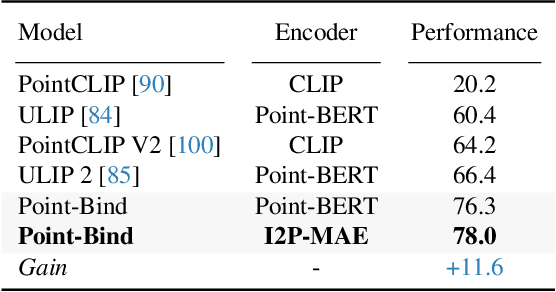
We introduce Point-Bind, a 3D multi-modality model aligning point clouds with 2D image, language, audio, and video. Guided by ImageBind, we construct a joint embedding space between 3D and multi-modalities, enabling many promising applications, e.g., any-to-3D generation, 3D embedding arithmetic, and 3D open-world understanding. On top of this, we further present Point-LLM, the first 3D large language model (LLM) following 3D multi-modal instructions. By parameter-efficient fine-tuning techniques, Point-LLM injects the semantics of Point-Bind into pre-trained LLMs, e.g., LLaMA, which requires no 3D instruction data, but exhibits superior 3D and multi-modal question-answering capacity. We hope our work may cast a light on the community for extending 3D point clouds to multi-modality applications. Code is available at https://github.com/ZiyuGuo99/Point-Bind_Point-LLM.
ChatGPT as Data Augmentation for Compositional Generalization: A Case Study in Open Intent Detection
Aug 25, 2023



Open intent detection, a crucial aspect of natural language understanding, involves the identification of previously unseen intents in user-generated text. Despite the progress made in this field, challenges persist in handling new combinations of language components, which is essential for compositional generalization. In this paper, we present a case study exploring the use of ChatGPT as a data augmentation technique to enhance compositional generalization in open intent detection tasks. We begin by discussing the limitations of existing benchmarks in evaluating this problem, highlighting the need for constructing datasets for addressing compositional generalization in open intent detection tasks. By incorporating synthetic data generated by ChatGPT into the training process, we demonstrate that our approach can effectively improve model performance. Rigorous evaluation of multiple benchmarks reveals that our method outperforms existing techniques and significantly enhances open intent detection capabilities. Our findings underscore the potential of large language models like ChatGPT for data augmentation in natural language understanding tasks.
Learning Monocular Depth in Dynamic Environment via Context-aware Temporal Attention
May 12, 2023



The monocular depth estimation task has recently revealed encouraging prospects, especially for the autonomous driving task. To tackle the ill-posed problem of 3D geometric reasoning from 2D monocular images, multi-frame monocular methods are developed to leverage the perspective correlation information from sequential temporal frames. However, moving objects such as cars and trains usually violate the static scene assumption, leading to feature inconsistency deviation and misaligned cost values, which would mislead the optimization algorithm. In this work, we present CTA-Depth, a Context-aware Temporal Attention guided network for multi-frame monocular Depth estimation. Specifically, we first apply a multi-level attention enhancement module to integrate multi-level image features to obtain an initial depth and pose estimation. Then the proposed CTA-Refiner is adopted to alternatively optimize the depth and pose. During the refinement process, context-aware temporal attention (CTA) is developed to capture the global temporal-context correlations to maintain the feature consistency and estimation integrity of moving objects. In particular, we propose a long-range geometry embedding (LGE) module to produce a long-range temporal geometry prior. Our approach achieves significant improvements over state-of-the-art approaches on three benchmark datasets.
Are ChatGPT and GPT-4 General-Purpose Solvers for Financial Text Analytics? An Examination on Several Typical Tasks
May 10, 2023



The most recent large language models such as ChatGPT and GPT-4 have garnered significant attention, as they are capable of generating high-quality responses to human input. Despite the extensive testing of ChatGPT and GPT-4 on generic text corpora, showcasing their impressive capabilities, a study focusing on financial corpora has not been conducted. In this study, we aim to bridge this gap by examining the potential of ChatGPT and GPT-4 as a solver for typical financial text analytic problems in the zero-shot or few-shot setting. Specifically, we assess their capabilities on four representative tasks over five distinct financial textual datasets. The preliminary study shows that ChatGPT and GPT-4 struggle on tasks such as financial named entity recognition (NER) and sentiment analysis, where domain-specific knowledge is required, while they excel in numerical reasoning tasks. We report both the strengths and limitations of the current versions of ChatGPT and GPT-4, comparing them to the state-of-the-art finetuned models as well as pretrained domain-specific generative models. Our experiments provide qualitative studies, through which we hope to help understand the capability of the existing models and facilitate further improvements.
Pay More Attention to Relation Exploration for Knowledge Base Question Answering
May 03, 2023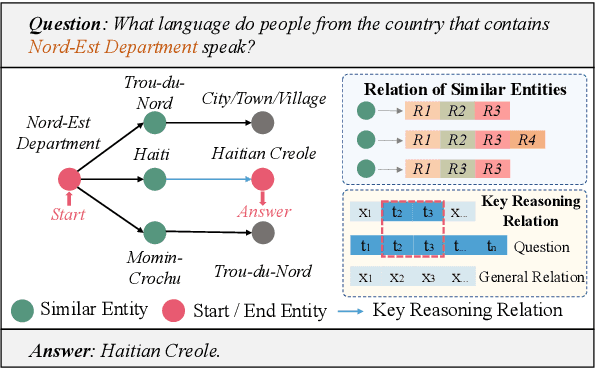
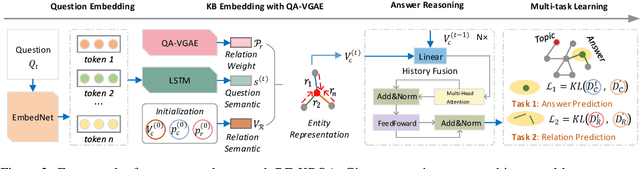
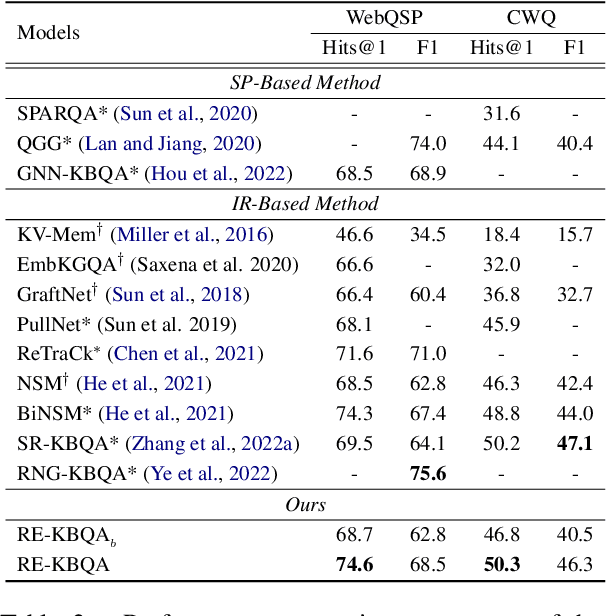
Knowledge base question answering (KBQA) is a challenging task that aims to retrieve correct answers from large-scale knowledge bases. Existing attempts primarily focus on entity representation and final answer reasoning, which results in limited supervision for this task. Moreover, the relations, which empirically determine the reasoning path selection, are not fully considered in recent advancements. In this study, we propose a novel framework, RE-KBQA, that utilizes relations in the knowledge base to enhance entity representation and introduce additional supervision. We explore guidance from relations in three aspects, including (1) distinguishing similar entities by employing a variational graph auto-encoder to learn relation importance; (2) exploring extra supervision by predicting relation distributions as soft labels with a multi-task scheme; (3) designing a relation-guided re-ranking algorithm for post-processing. Experimental results on two benchmark datasets demonstrate the effectiveness and superiority of our framework, improving the F1 score by 5.7% from 40.5 to 46.3 on CWQ and 5.8% from 62.8 to 68.5 on WebQSP, better or on par with state-of-the-art methods.