 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYongyi Yang
HERTA: A High-Efficiency and Rigorous Training Algorithm for Unfolded Graph Neural Networks
Mar 26, 2024
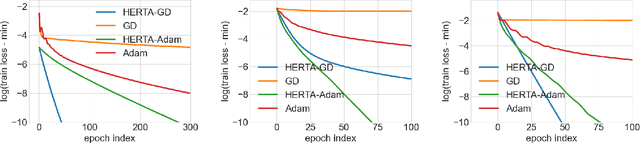
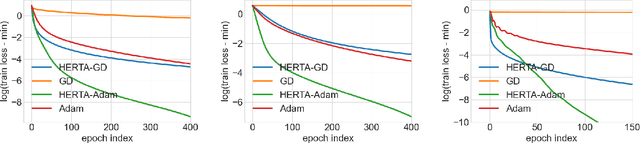
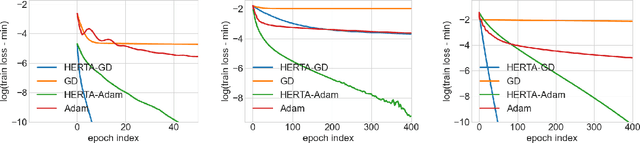
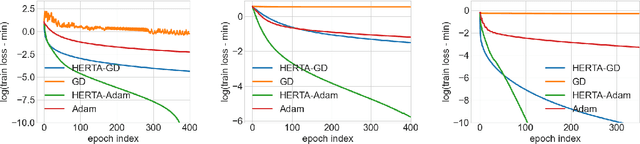
As a variant of Graph Neural Networks (GNNs), Unfolded GNNs offer enhanced interpretability and flexibility over traditional designs. Nevertheless, they still suffer from scalability challenges when it comes to the training cost. Although many methods have been proposed to address the scalability issues, they mostly focus on per-iteration efficiency, without worst-case convergence guarantees. Moreover, those methods typically add components to or modify the original model, thus possibly breaking the interpretability of Unfolded GNNs. In this paper, we propose HERTA: a High-Efficiency and Rigorous Training Algorithm for Unfolded GNNs that accelerates the whole training process, achieving a nearly-linear time worst-case training guarantee. Crucially, HERTA converges to the optimum of the original model, thus preserving the interpretability of Unfolded GNNs. Additionally, as a byproduct of HERTA, we propose a new spectral sparsification method applicable to normalized and regularized graph Laplacians that ensures tighter bounds for our algorithm than existing spectral sparsifiers do. Experiments on real-world datasets verify the superiority of HERTA as well as its adaptability to various loss functions and optimizers.
Going Beyond Linear Mode Connectivity: The Layerwise Linear Feature Connectivity
Jul 17, 2023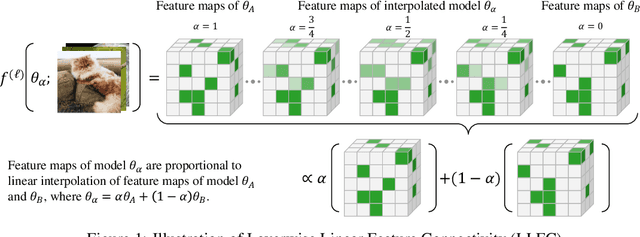
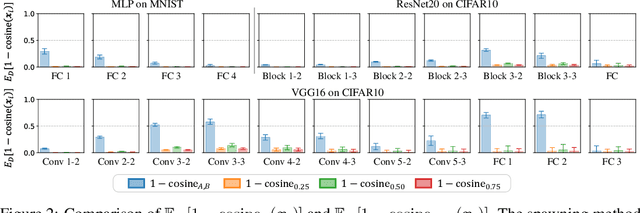
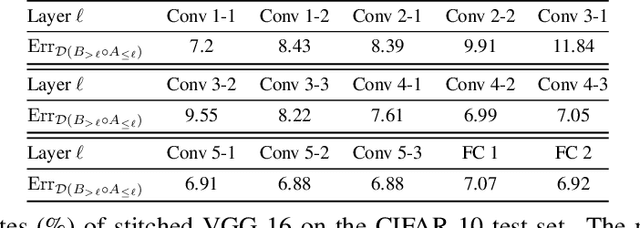
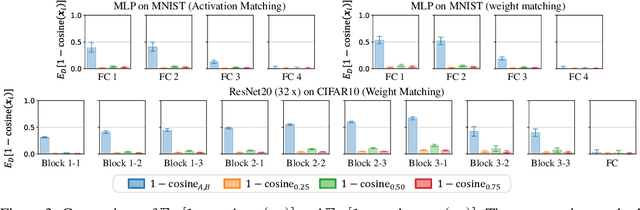
Recent work has revealed many intriguing empirical phenomena in neural network training, despite the poorly understood and highly complex loss landscapes and training dynamics. One of these phenomena, Linear Mode Connectivity (LMC), has gained considerable attention due to the intriguing observation that different solutions can be connected by a linear path in the parameter space while maintaining near-constant training and test losses. In this work, we introduce a stronger notion of linear connectivity, Layerwise Linear Feature Connectivity (LLFC), which says that the feature maps of every layer in different trained networks are also linearly connected. We provide comprehensive empirical evidence for LLFC across a wide range of settings, demonstrating that whenever two trained networks satisfy LMC (via either spawning or permutation methods), they also satisfy LLFC in nearly all the layers. Furthermore, we delve deeper into the underlying factors contributing to LLFC, which reveal new insights into the spawning and permutation approaches. The study of LLFC transcends and advances our understanding of LMC by adopting a feature-learning perspective.
Are Neurons Actually Collapsed? On the Fine-Grained Structure in Neural Representations
Jun 29, 2023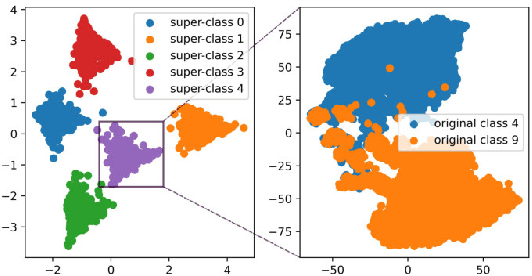

Recent work has observed an intriguing ''Neural Collapse'' phenomenon in well-trained neural networks, where the last-layer representations of training samples with the same label collapse into each other. This appears to suggest that the last-layer representations are completely determined by the labels, and do not depend on the intrinsic structure of input distribution. We provide evidence that this is not a complete description, and that the apparent collapse hides important fine-grained structure in the representations. Specifically, even when representations apparently collapse, the small amount of remaining variation can still faithfully and accurately captures the intrinsic structure of input distribution. As an example, if we train on CIFAR-10 using only 5 coarse-grained labels (by combining two classes into one super-class) until convergence, we can reconstruct the original 10-class labels from the learned representations via unsupervised clustering. The reconstructed labels achieve $93\%$ accuracy on the CIFAR-10 test set, nearly matching the normal CIFAR-10 accuracy for the same architecture. We also provide an initial theoretical result showing the fine-grained representation structure in a simplified synthetic setting. Our results show concretely how the structure of input data can play a significant role in determining the fine-grained structure of neural representations, going beyond what Neural Collapse predicts.
Descent Steps of a Relation-Aware Energy Produce Heterogeneous Graph Neural Networks
Jun 24, 2022


Heterogeneous graph neural networks (GNNs) achieve strong performance on node classification tasks in a semi-supervised learning setting. However, as in the simpler homogeneous GNN case, message-passing-based heterogeneous GNNs may struggle to balance between resisting the oversmoothing occuring in deep models and capturing long-range dependencies graph structured data. Moreover, the complexity of this trade-off is compounded in the heterogeneous graph case due to the disparate heterophily relationships between nodes of different types. To address these issues, we proposed a novel heterogeneous GNN architecture in which layers are derived from optimization steps that descend a novel relation-aware energy function. The corresponding minimizer is fully differentiable with respect to the energy function parameters, such that bilevel optimization can be applied to effectively learn a functional form whose minimum provides optimal node representations for subsequent classification tasks. In particular, this methodology allows us to model diverse heterophily relationships between different node types while avoiding oversmoothing effects. Experimental results on 8 heterogeneous graph benchmarks demonstrates that our proposed method can achieve competitive node classification accuracy.
Transformers from an Optimization Perspective
May 27, 2022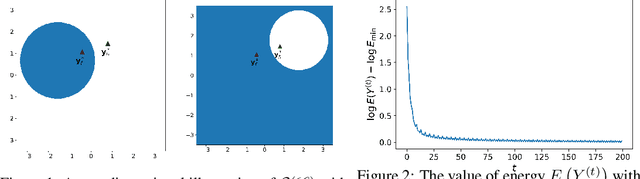

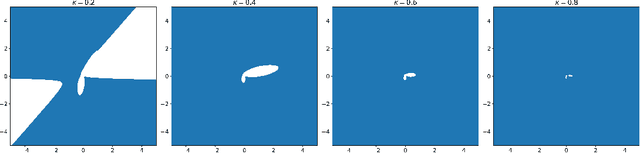
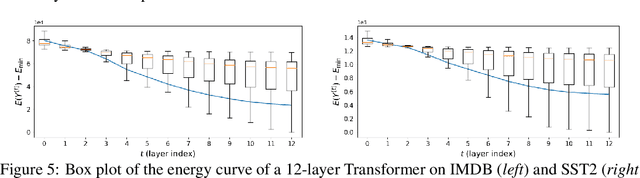
Deep learning models such as the Transformer are often constructed by heuristics and experience. To provide a complementary foundation, in this work we study the following problem: Is it possible to find an energy function underlying the Transformer model, such that descent steps along this energy correspond with the Transformer forward pass? By finding such a function, we can reinterpret Transformers as the unfolding of an interpretable optimization process across iterations. This unfolding perspective has been frequently adopted in the past to elucidate more straightforward deep models such as MLPs and CNNs; however, it has thus far remained elusive obtaining a similar equivalence for more complex models with self-attention mechanisms like the Transformer. To this end, we first outline several major obstacles before providing companion techniques to at least partially address them, demonstrating for the first time a close association between energy function minimization and deep layers with self-attention. This interpretation contributes to our intuition and understanding of Transformers, while potentially laying the ground-work for new model designs.
Implicit vs Unfolded Graph Neural Networks
Nov 12, 2021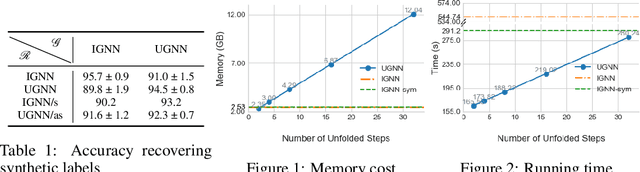


It has been observed that graph neural networks (GNN) sometimes struggle to maintain a healthy balance between modeling long-range dependencies across nodes while avoiding unintended consequences such as oversmoothed node representations. To address this issue (among other things), two separate strategies have recently been proposed, namely implicit and unfolded GNNs. The former treats node representations as the fixed points of a deep equilibrium model that can efficiently facilitate arbitrary implicit propagation across the graph with a fixed memory footprint. In contrast, the latter involves treating graph propagation as the unfolded descent iterations as applied to some graph-regularized energy function. While motivated differently, in this paper we carefully elucidate the similarity and differences of these methods, quantifying explicit situations where the solutions they produced may actually be equivalent and others where behavior diverges. This includes the analysis of convergence, representational capacity, and interpretability. We also provide empirical head-to-head comparisons across a variety of synthetic and public real-world benchmarks.
Why Propagate Alone? Parallel Use of Labels and Features on Graphs
Oct 14, 2021



Graph neural networks (GNNs) and label propagation represent two interrelated modeling strategies designed to exploit graph structure in tasks such as node property prediction. The former is typically based on stacked message-passing layers that share neighborhood information to transform node features into predictive embeddings. In contrast, the latter involves spreading label information to unlabeled nodes via a parameter-free diffusion process, but operates independently of the node features. Given then that the material difference is merely whether features or labels are smoothed across the graph, it is natural to consider combinations of the two for improving performance. In this regard, it has recently been proposed to use a randomly-selected portion of the training labels as GNN inputs, concatenated with the original node features for making predictions on the remaining labels. This so-called label trick accommodates the parallel use of features and labels, and is foundational to many of the top-ranking submissions on the Open Graph Benchmark (OGB) leaderboard. And yet despite its wide-spread adoption, thus far there has been little attempt to carefully unpack exactly what statistical properties the label trick introduces into the training pipeline, intended or otherwise. To this end, we prove that under certain simplifying assumptions, the stochastic label trick can be reduced to an interpretable, deterministic training objective composed of two factors. The first is a data-fitting term that naturally resolves potential label leakage issues, while the second serves as a regularization factor conditioned on graph structure that adapts to graph size and connectivity. Later, we leverage this perspective to motivate a broader range of label trick use cases, and provide experiments to verify the efficacy of these extensions.
Graph Neural Networks Inspired by Classical Iterative Algorithms
Mar 10, 2021

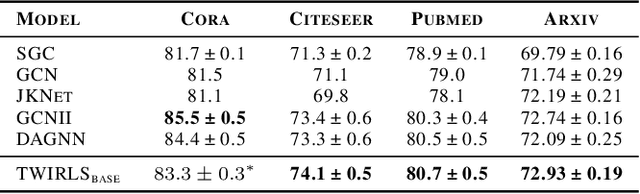
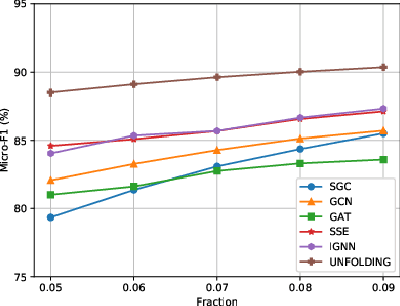
Despite the recent success of graph neural networks (GNN), common architectures often exhibit significant limitations, including sensitivity to oversmoothing, long-range dependencies, and spurious edges, e.g., as can occur as a result of graph heterophily or adversarial attacks. To at least partially address these issues within a simple transparent framework, we consider a new family of GNN layers designed to mimic and integrate the update rules of two classical iterative algorithms, namely, proximal gradient descent and iterative reweighted least squares (IRLS). The former defines an extensible base GNN architecture that is immune to oversmoothing while nonetheless capturing long-range dependencies by allowing arbitrary propagation steps. In contrast, the latter produces a novel attention mechanism that is explicitly anchored to an underlying end-toend energy function, contributing stability with respect to edge uncertainty. When combined we obtain an extremely simple yet robust model that we evaluate across disparate scenarios including standardized benchmarks, adversarially-perturbated graphs, graphs with heterophily, and graphs involving long-range dependencies. In doing so, we compare against SOTA GNN approaches that have been explicitly designed for the respective task, achieving competitive or superior node classification accuracy.
Relation of the Relations: A New Paradigm of the Relation Extraction Problem
Jun 05, 2020
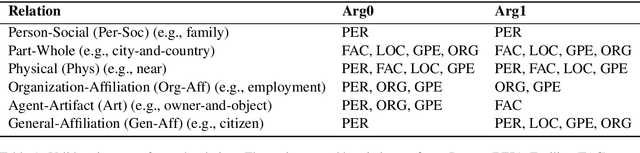
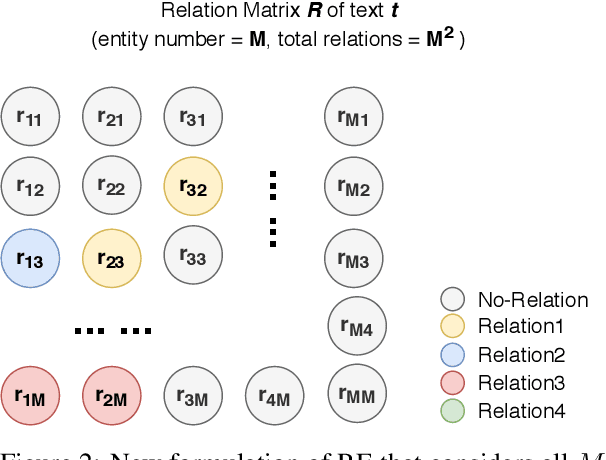
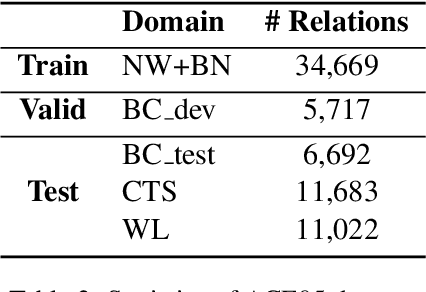
In natural language, often multiple entities appear in the same text. However, most previous works in Relation Extraction (RE) limit the scope to identifying the relation between two entities at a time. Such an approach induces a quadratic computation time, and also overlooks the interdependency between multiple relations, namely the relation of relations (RoR). Due to the significance of RoR in existing datasets, we propose a new paradigm of RE that considers as a whole the predictions of all relations in the same context. Accordingly, we develop a data-driven approach that does not require hand-crafted rules but learns by itself the RoR, using Graph Neural Networks and a relation matrix transformer. Experiments show that our model outperforms the state-of-the-art approaches by +1.12\% on the ACE05 dataset and +2.55\% on SemEval 2018 Task 7.2, which is a substantial improvement on the two competitive benchmarks.